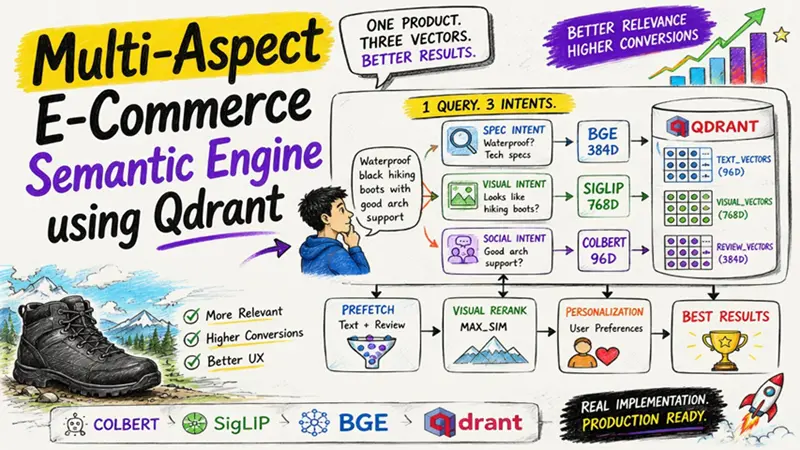
基于Qdrant的多维电商语义引擎
我如何使用ColBERT、SigLIP和BGE在单个Qdrant点内构建多向量语义搜索引擎,在触及数据库之前先拆分用户意图
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
六个月前,我在为一个小型电商目录构建语义搜索引擎。一切看起来都不错。我使用了一个好的嵌入模型、余弦相似度,搜索结果看起来也很合理。
然后我搜索了:
"防水黑色登山靴,带良好足弓支撑"
第一个结果很完美。第二个是一件防水夹克。第三个是一双黑色切尔西靴。
从技术上讲,搜索结果并没有错。每个结果在语义上都与查询相似。但如果我是顾客,我根本不在乎。我想要的是带足弓支撑的登山靴,而不是恰好包含几个相似词汇的产品。
我尝试了更好的嵌入模型。我改变了分块策略。我添加了更多元数据。结果略有改善,但真正的问题从未消失。
问题不在于模型。 问题在于一个假设:一个嵌入向量就能代表整个产品。一件产品有技术规格、图片和顾客评论。这些是不同类型的信息,而我却将它们全部压缩进一个向量中。
于是我重建了系统。 我不再为每个产品使用一个嵌入向量,而是为规格、图片和评论发现分别存储独立的向量空间。在嵌入之前,我将每个查询拆分为不同类型的意图,并在此基础上添加了轻量级的个性化层。
1、心智模型:在阅读一行代码之前
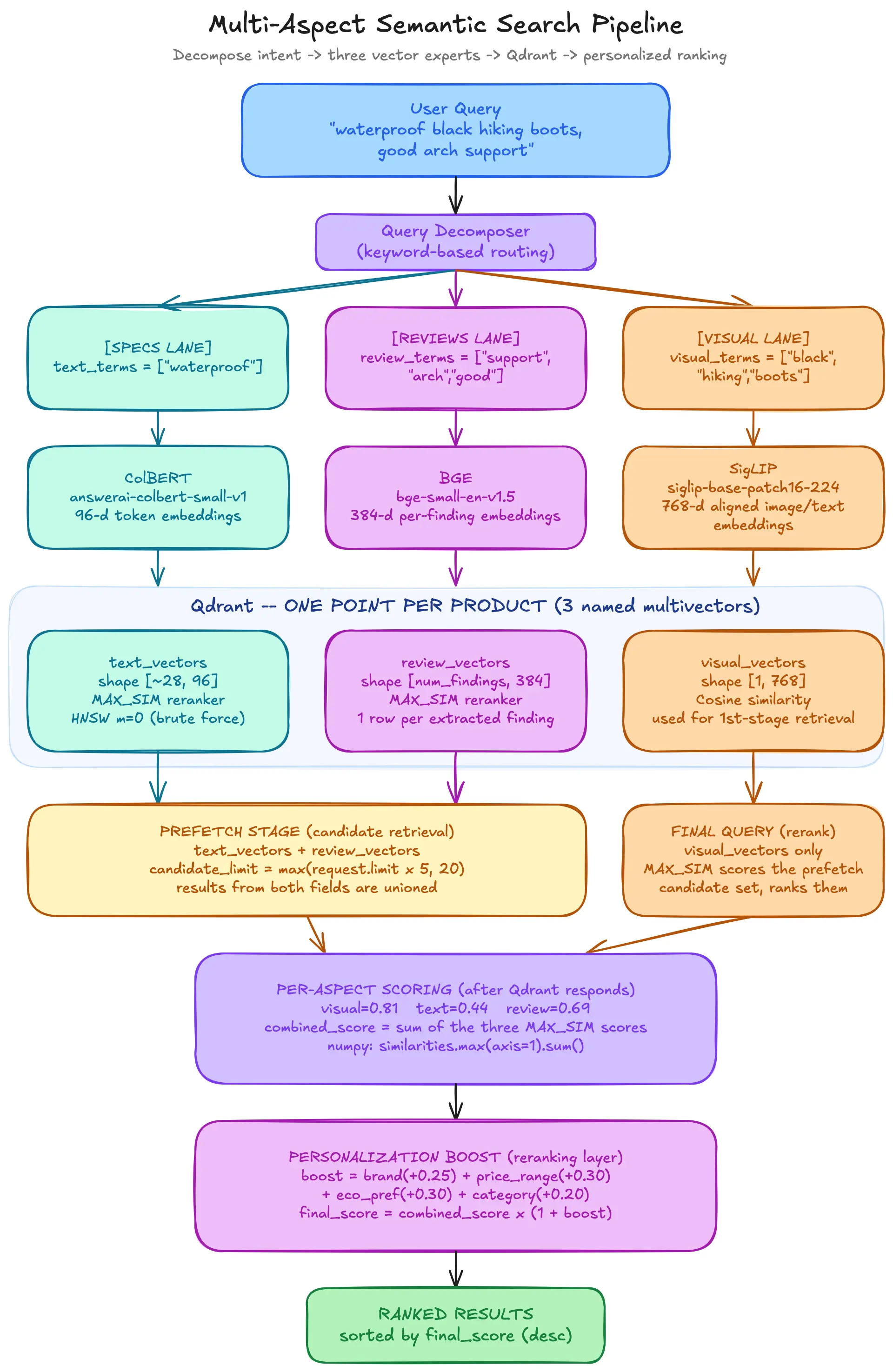
把系统想象成三个专家在评估同一件产品。
当用户搜索"防水黑色登山靴,带良好足弓支撑"时,查询被拆分为三个问题:
- 它防水吗?→ 规格专家 (ColBERT)
- 它看起来像黑色登山靴吗?→ 视觉专家 (SigLIP)
- 顾客称赞足弓支撑吗?→ 评论专家 (BGE)
每位专家搜索存储在同一个Qdrant点内的不同向量字段。文本和评论检索先提名候选,视觉通道执行最终评分,个性化则对结果进行重排序。
系统不强迫一个嵌入向量代表一切,而是评估独立的证据片段,在排名阶段将它们组合起来。
2、核心问题:一个向量无法代表一切
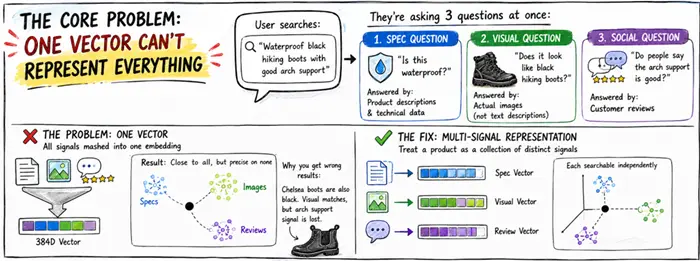
当有人搜索"防水黑色登山靴,带良好足弓支撑"时,他们问的不是一个问题,而是同时问三个问题:
- 第一个是规格问题:"这是防水的吗?"由产品描述和技术数据表回答。
- 第二个是视觉问题:"它看起来像黑色登山靴吗?"由图片回答。不是图片的文字描述,而是实际图片。
- 第三个是社交问题:"人们说足弓支撑好吗?"由顾客评论回答。
没有一个单一的嵌入模型能以同等保真度捕捉所有三种信号。当你将它们汇合在一起时,你得到的向量大致位于三者附近,但对任何一个都不精确。这就是为什么你会在登山靴结果中看到切尔西靴。两者都是黑色鞋类。视觉信号表现尚可。足弓支撑信号则完全丢失了。
解决方案是停止将产品视为一个整体,而是将其视为独立信号的集合,每个信号都可以独立搜索。
3、为什么我选择Qdrant
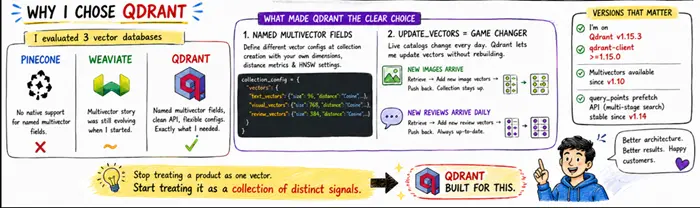
在做出决定之前,我评估了Pinecone、Weaviate和Qdrant。决定性因素是命名多向量字段。我需要为每个文档存储多种不同类型的向量,每种都有自己的维度和比较函数。Pinecone不支持这个功能。Weaviate的多向量方案在我开始时仍在发展中。
Qdrant的API很简洁:你在创建集合时定义命名向量配置,每个配置有不同的维度、距离度量和HNSW设置。
另一个打动我的是update_vectors。在实时目录中:
- 产品获得新图片。视觉矩阵需要增长,而无需重建集合。
- 评论每天到达。每条新评论都会向评论矩阵添加行。
- Qdrant通过允许你检索现有向量字段、连接新向量并将更新后的矩阵推回来处理这两种情况。集合保持在线,正在运行的查询继续工作。
版本很重要。我使用的是Qdrant v1.15.3,使用qdrant-client>=1.15.0。多向量从v1.10开始可用,但使多阶段搜索干净工作的query_points预取API在v1.14中变得稳定。
4、系统存储的内容:一个点,三个矩阵
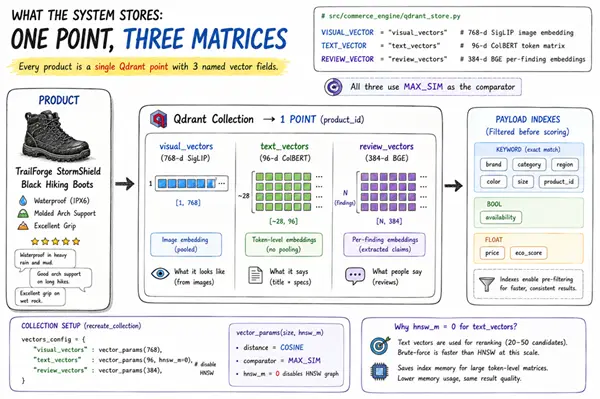
每个产品变成一个Qdrant点。该点有三个命名字段:
# src/commerce_engine/qdrant_store.py
VISUAL_VECTOR = "visual_vectors" # 768维 SigLIP 图像嵌入
TEXT_VECTOR = "text_vectors" # 96维 ColBERT 令牌矩阵
REVIEW_VECTOR = "review_vectors" # 384维 BGE 每个发现的嵌入
所有三个都使用 MAX_SIM 作为比较器。以下是完整的集合设置:
def vector_params(size: int, *, hnsw_m: int | None = None) -> models.VectorParams:
hnsw_config = None
if hnsw_m is not None:
hnsw_config = models.HnswConfigDiff(m=hnsw_m)
return models.VectorParams(
size=size,
distance=models.Distance.COSINE,
multivector_config=models.MultiVectorConfig(
comparator=models.MultiVectorComparator.MAX_SIM
),
hnsw_config=hnsw_config,
)
def recreate_collection(client, collection, *, profile="baseline", disable_text_hnsw=True):
client.create_collection(
collection_name=collection,
vectors_config={
VISUAL_VECTOR: vector_params(VISION_DIM), # 768
TEXT_VECTOR: vector_params(TEXT_DIM, hnsw_m=0 if disable_text_hnsw else None),# 96
REVIEW_VECTOR: vector_params(REVIEW_DIM), # 384
},
quantization_config=quantization_config(profile),
)
create_payload_indexes(client, collection)
TEXT_VECTOR 上设置 hnsw_m=0 是有意为之。设置 m=0 完全禁用了该字段的HNSW图索引。通常这会是性能灾难,但这里不是,有两个原因:
- 文本向量不用于第一阶段检索。 它们用作预取阶段已返回的小候选集上的ColBERT重排序器。在20-50个候选中,暴力矩阵比较胜过HNSW,因为图遍历开销在N较小时比它节省的成本更多。
- 它节省了索引内存。 令牌级矩阵比池化向量更大。跳过
text_vectors的HNSW图减少了内存占用,当你跨产品存储数千个令牌的96维矩阵时,这一点会产生复合效应。
负载也会单独索引,以便Qdrant可以在评分前进行过滤:
def create_payload_indexes(client, collection):
# 关键词字段
for field in ["brand", "category", "region", "color", "size", "product_id"]:
client.create_payload_index(
collection_name=collection,
field_name=field,
field_schema=models.PayloadSchemaType.KEYWORD,
)
# 布尔字段
client.create_payload_index(
collection_name=collection,
field_name="availability",
field_schema=models.PayloadSchemaType.BOOL,
)
# 浮点字段
for field in ["price", "eco_score"]:
client.create_payload_index(
collection_name=collection,
field_name=field,
field_schema=models.PayloadSchemaType.FLOAT,
)
这比看起来更重要。当索引存在时,Qdrant在向量评分之前运行负载过滤。过滤 availability=True 或 price <= 150.0 在任何嵌入比较运行之前就消除了候选。没有索引,你得到的是后过滤,这更慢且会产生不一致的结果计数。在查询之前为你的可过滤字段建立索引。
5、三个嵌入管道
点中的每个向量字段来自不同的嵌入管道。同一产品在摄取前经过所有三个管道。
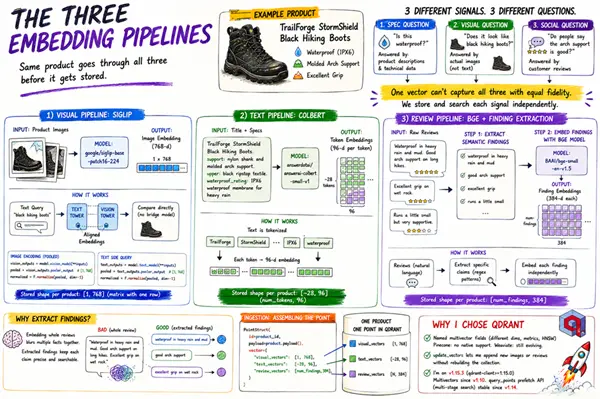
5.1 视觉管道:SigLIP
产品图片经过 google/siglip-base-patch16-224。
SigLIP是一个视觉-语言模型,具有对齐的图像和文本嵌入。 对齐意味着你可以编码一个文本查询如"黑色登山靴"并直接与图像嵌入进行比较。无需桥接模型,无需单独的对齐步骤。
# src/commerce_engine/embeddings.py
def image_patches(self, image_path: Path) -> list[list[float]]:
"""返回形状 [1, 768]:归一化的SigLIP池化图像嵌入。"""
self._load_siglip()
import torch
image = Image.open(image_path).convert("RGB")
siglip_inputs = self._siglip_processor(images=image, return_tensors="pt")
siglip_inputs = {k: v.to(self.device) for k, v in siglip_inputs.items()}
with torch.no_grad():
vision_outputs = self._siglip_model.vision_model(**siglip_inputs)
pooled = vision_outputs.pooler_output # shape: [1, 768]
normalized = torch.nn.functional.normalize(pooled, dim=-1)
return normalized.cpu().numpy().astype(float).tolist()
以及相应的文本端查询编码:
def visual_query(self, query: str) -> list[list[float]]:
"""返回形状 [1, 768]:归一化的SigLIP文本塔输出。"""
self._load_siglip()
text_inputs = self._siglip_processor(
text=[query], return_tensors="pt", padding=True, truncation=True
)
text_inputs = {k: v.to(self.device) for k, v in text_inputs.items()}
with torch.no_grad():
text_outputs = self._siglip_model.text_model(**text_inputs)
pooled = text_outputs.pooler_output # shape: [1, 768]
normalized = torch.nn.functional.normalize(pooled, dim=-1)
return normalized.cpu().numpy().astype(float).tolist()
两个输出在存储和查询前都经过L2归一化。这使得余弦相似度等同于点积,Qdrant计算起来更快。
每个产品的存储形状是 [1, 768],一个只有一行的矩阵。从技术上讲,它是一个包含一个元素的2D多向量,但将其存储为矩阵而不是扁平向量可以保持接口一致,并使得将来追加额外的图像块变得简单。
5.2 文本管道:ColBERT
产品标题和规格表经过FastEmbed的 answerdotai/answerai-colbert-small-v1。该模型生成令牌级嵌入,每个令牌96维,不做池化。
def text_late(self, texts: list[str]) -> list[list[list[float]]]:
return [
embedding.astype(float).tolist()
for embedding in self.late_model.embed(texts)
]
返回形状是 [文本数, 令牌数, 96]。对于一个产品标题,你得到一个形状为 [令牌数, 96] 的矩阵。一个规格丰富的产品如"TrailForge StormShield 黑色登山靴。支撑:尼龙鞋芯和模塑足弓支撑。鞋面:黑色防撕裂纺织品。防水等级:IPX6防水膜适用于大雨"会分词为约25-30个令牌,因此存储的矩阵是 [~28, 96]。
文本文档在Product模型中组装:
# src/commerce_engine/models.py
def text_document(self) -> str:
specs = " ".join(f"{key}: {value}" for key, value in sorted(self.specs.items()))
return f"{self.title}. {specs}"
先是标题,然后是所有规格作为键值对。规格键(support、waterproof_rating、upper)作为文本包含在内,以便ColBERT可以将如"waterproof"的查询令牌匹配到规格键,而不仅仅是规格值。
5.3 评论管道:BGE与语义发现提取
原始评论不会直接进入嵌入器。它们首先经过一个发现提取步骤。这就是架构与朴素方法最大不同的地方。
像"大雨和泥泞中防水。长途徒步中足弓支撑好。湿岩上抓地力极佳。"这样的评论包含三个独立的事实声明。将完整评论作为单个向量嵌入会将三者平均化。一个有十条评论的产品整体嵌入后会给出十个平均模糊块。你会丢失对特定查询重要的特定声明。
相反,extract_semantic_findings() 使用正则表达式模式提取特定声明:
# src/commerce_engine/reviews.py
FINDING_PATTERNS = [
r"waterproof(?: in [a-z ]+)?",
r"kept feet dry",
r"good arch support",
r"arch support is [a-z]+",
r"supportive footbed",
r"excellent grip",
r"not enough grip",
r"highly durable",
r"runs a little small",
r"runs small",
r"strong ankle support",
]
def extract_semantic_findings(reviews: list[str]) -> list[str]:
findings: list[str] = []
for review in reviews:
normalized = review.lower().strip()
matched = False
for pattern in FINDING_PATTERNS:
match = re.search(pattern, normalized)
if match:
findings.append(match.group(0))
matched = True
if not matched:
findings.append(normalized.rstrip("."))
return list(dict.fromkeys(findings)) # 去重
TrailForge靴子的发现结果如下:["大雨和泥泞中防水", "足弓支撑好", "抓地力极佳"]。每个发现随后分别用 BAAI/bge-small-en-v1.5 嵌入为384维向量:
def review_findings(self, findings: list[str]) -> list[list[float]]:
if not findings:
return [_unit_vector("empty-review", REVIEW_DIM)]
return [
embedding.astype(float).tolist()
for embedding in self.review_model.embed(findings)
]
存储的评论矩阵是 [发现数, 384]。三个发现变成 [3, 384] 矩阵。一个有十条评论和15个提取发现的产品变成 [15, 384]。
当查询包含"足弓支撑好"时,它被嵌入为单个384维向量,并通过MAX_SIM与此矩阵进行比较。最相似的发现胜出。匹配的发现是来自评论的"足弓支撑好",而非所有评论内容的平均近似。
完整的摄取步骤将所有三个矩阵组装到单个点中:
# src/commerce_engine/ingest.py
def product_point(product: Product, embedder: Embedder) -> models.PointStruct:
text_matrix = embedder.text_late([product.text_document()])[0]
review_matrix = embedder.review_findings(
extract_semantic_findings(product.reviews)
)
visual_matrix = embedder.image_patches(Path(product.image_path))
return models.PointStruct(
id=point_id(product.id),
payload=product.payload(),
vector={
VISUAL_VECTOR: visual_matrix, # shape [1, 768]
TEXT_VECTOR: text_matrix, # shape [~28, 96]
REVIEW_VECTOR: review_matrix, # shape [发现数, 384]
},
)
一个产品。一个点。三个矩阵,每个解决不同的检索问题。
6、查询分解:在嵌入之前路由意图
当用户提交查询时,第一步是分解。查询不会直接发送到所有三个向量字段。
# src/commerce_engine/query.py
TEXT_KEYWORDS = {"waterproof", "water-resistant", "rain", "membrane", "insulated", "leather"}
VISUAL_KEYWORDS = {"black", "brown", "charcoal", "red", "blue", "hiking", "boots", "sneakers"}
REVIEW_KEYWORDS = {"support", "arch", "grip", "durable", "comfortable", "runs", "excellent"}
def decompose_query(query: str) -> QueryPlan:
tokens = tokenize(query)
text_terms = [t for t in tokens if t in TEXT_KEYWORDS]
visual_terms = [t for t in tokens if t in VISUAL_KEYWORDS]
review_terms = [t for t in tokens if t in REVIEW_KEYWORDS]
phrase = " ".join(tokens)
# 短语级覆写已知复合词
if "good arch support" in phrase:
review_terms.extend(["good", "arch", "support"])
if "black hiking boots" in phrase:
visual_terms.extend(["black", "hiking", "boots"])
if "waterproof" in phrase:
text_terms.append("waterproof")
return QueryPlan(
original_query=query,
text_terms=list(dict.fromkeys(text_terms)),
visual_terms=list(dict.fromkeys(visual_terms)),
review_terms=list(dict.fromkeys(review_terms)),
)
对于"防水黑色登山靴,带良好足弓支撑",分解产生:
text_terms = ["waterproof"]→ 路由到ColBERT规格匹配visual_terms = ["black", "hiking", "boots"]→ 路由到SigLIP视觉匹配review_terms = ["support", "arch", "good"]→ 路由到BGE评论匹配
QueryPlan模型暴露三个属性,将这些词连接回子查询字符串:
# src/commerce_engine/models.py
@property
def text_query(self) -> str:
return " ".join(self.text_terms or [self.original_query])
@property
def visual_query(self) -> str:
return " ".join(self.visual_terms or [self.original_query])
@property
def review_query(self) -> str:
return " ".join(self.review_terms or [self.original_query])
如果没有词匹配到某个类别,原始查询会作为该字段的子查询后备。这防止了空查询。
我直接说一下局限:这种分解使用关键词匹配,比较粗糙。更好的生产实现会调用LLM来分类查询意图。无论哪种方式,架构都是一样的。重要的是你在嵌入之前进行路由,而不是你使用什么花哨的分类器进行路由。先把结构做对。
7、搜索:预取然后最终评分
Qdrant的query_points支持prefetch参数。它允许你从多个向量字段并行检索候选集,然后仅对这些候选应用最终评分阶段。
# src/commerce_engine/search.py
def search_products(client, collection, request, embedder):
plan = decompose_query(request.query)
query_filter = build_filter(request.filters)
# 嵌入所有三个子查询
text_query = embedder.text_late([plan.text_query])[0]
review_query = embedder.review_findings([plan.review_query])
visual_query = embedder.visual_query(plan.visual_query)
candidate_limit = max(request.limit * 5, 20)
# 文本和评论作为预取候选运行
prefetch = [
models.Prefetch(
query=text_query,
using=TEXT_VECTOR,
limit=candidate_limit,
filter=query_filter,
),
models.Prefetch(
query=review_query,
using=REVIEW_VECTOR,
limit=candidate_limit,
filter=query_filter,
),
]
# 视觉查询对预取候选进行评分和排序
response = client.query_points(
collection_name=collection,
prefetch=prefetch,
query=visual_query,
using=VISUAL_VECTOR,
query_filter=query_filter,
limit=max(request.limit * 3, 10),
with_payload=True,
with_vectors=True,
)
文本和评论预取阶段各返回最多candidate_limit个结果。Qdrant将它们合并。最终的视觉查询然后仅使用VISUAL_VECTOR字段对这些候选进行评分。负载过滤在每个阶段都适用。
在Qdrant响应后,代码计算每个方面的MAX_SIM分数以获得命名的分解:
from commerce_engine.scoring import maxsim_score
for point in response.points:
vectors = point.vector or {}
doc_visual = vectors.get(VISUAL_VECTOR, [])
doc_text = vectors.get(TEXT_VECTOR, [])
doc_review = vectors.get(REVIEW_VECTOR, [])
v_score = maxsim_score(visual_query, doc_visual) if doc_visual else 0.0
t_score = maxsim_score(text_query, doc_text) if doc_text else 0.0
r_score = maxsim_score(review_query, doc_review) if doc_review else 0.0
combined_score = v_score + t_score + r_score
MAX_SIM函数本身是三行NumPy:
# src/commerce_engine/scoring.py
def maxsim_score(query_matrix, doc_matrix) -> float:
query = np.asarray(query_matrix, dtype=np.float32)
doc = np.asarray(doc_matrix, dtype=np.float32)
similarities = query @ doc.T # [查询令牌, 文档令牌]
return float(similarities.max(axis=1).sum())# 每个查询令牌取最大,然后求和
对于每个查询令牌:找到与所有文档令牌的最高相似度。将这些每个令牌的最大值相加。这个和就是MAX_SIM分数。这就是完整的ColBERT晚期交互公式。
在检索后手动计算它,可以在解释字段中给出每个方面的分数(visual=0.81, text=0.44, review=0.69)。这个分解是系统中最好的调试工具。当结果感觉不对时,方面分数立即告诉你视觉、规格或评论信号哪个匹配失败。
8、个性化:对相同候选进行不同重排序
Qdrant返回结果后,个性化层根据请求用户的画像对它们进行重排序。Qdrant检索步骤对每个用户都是相同的。只有重排序发生变化。
# src/commerce_engine/scoring.py
def personalization_boost(payload: dict, profile: UserProfile) -> tuple[float, list[str]]:
boost = 0.0
reasons = []
if payload.get("brand") in profile.preferred_brands:
boost += 0.25
reasons.append(f"偏好品牌: {payload['brand']}")
price = float(payload.get("price", 0.0))
low, high = profile.price_range
if low <= price <= high:
boost += 0.30
reasons.append(f"价格在用户范围内: {low:g}-{high:g}")
if profile.eco_preference and payload.get("is_sustainable"):
boost += 0.30
reasons.append("环保偏好匹配")
if payload.get("category") in profile.favorite_categories:
boost += 0.20
reasons.append(f"偏好品类: {payload['category']}")
return boost, reasons
def rerank(results: list[SearchResult], profile: UserProfile) -> list[SearchResult]:
reranked = []
for result in results:
boost, reasons = personalization_boost(result.payload, profile)
final_score = result.qdrant_score * (1.0 + boost)
reranked.append(
result.model_copy(update={
"final_score": final_score,
"personalization_boost": boost,
"explanation": [*result.explanation, *reasons],
})
)
return sorted(reranked, key=lambda r: r.final_score, reverse=True)
提升是乘性的,而不是加性的。语义得分为0.90、总提升为0.55的产品最终得分为0.90 × 1.55 = 1.395。得分为0.95但没有匹配偏好的产品保持在0.95。个性化可以翻转排名。
每个匹配的提升原因都会被追加到结果的解释字符串中,因此一个顶级结果可能显示:"偏好品牌: TrailForge | 价格在用户范围内: 80-165 | 评论证据: 足弓支撑"。这很重要有两个原因:用户信任他们能理解的推荐,而且你可以在几秒钟内通过查看得分原因来调试一个糟糕的结果。
9、无需重建即可更新产品
生产目录不是静态的。产品获得新图片。评论每天到来。系统需要在不宕机的情况下处理这两种情况。
两种更新操作遵循相同的模式:检索现有向量字段,连接新向量,用update_vectors推送更新后的矩阵。
# src/commerce_engine/updates.py
def append_review(client, collection, product_id, review, embedder):
point = _get_point(client, collection, product_id)
findings = extract_semantic_findings([review])
new_vecs = embedder.review_findings(findings)
existing = (point.vector or {}).get(REVIEW_VECTOR, [])
updated_matrix = [*existing, *new_vecs]
update_named_vectors(client, collection, product_id, {REVIEW_VECTOR: updated_matrix})
client.set_payload(
collection_name=collection,
payload={"reviews": [*point.payload.get("reviews", []), review]},
points=[point_id(product_id)],
wait=True,
)
return {"product_id": product_id, "findings": findings}
def append_image(client, collection, product_id, image_path, embedder):
point = _get_point(client, collection, product_id)
new_vecs = embedder.image_patches(image_path)
existing = (point.vector or {}).get(VISUAL_VECTOR, [])
updated_matrix = [*existing, *new_vecs]
update_named_vectors(client, collection, product_id, {VISUAL_VECTOR: updated_matrix})
return {
"product_id": product_id,
"added_patches": len(new_vecs),
"total_patches": len(updated_matrix),
}
在append_review之后,产品的评论矩阵每提取一个发现就增长一行。在append_image之后,视觉矩阵增加一行。无需重建集合。正在运行的查询继续工作。
这比听起来重要得多。如果添加一条评论就需要重新摄取整个产品,那你只能批量更新,评论数据总会滞后。使用update_vectors,webhook可以实时处理传入的评论,下一次搜索查询立即受益于新信号。
10、基准测试的实际结果
基准测试针对固定产品集(4款登山靴变体)运行了104个查询,由产品属性组合生成:颜色+品类、品牌+品类、基于规格、评论片段和复合查询。延迟使用time.perf_counter针对实时Qdrant实例测量。
基线的结果(无量化,文本禁用HNSW):
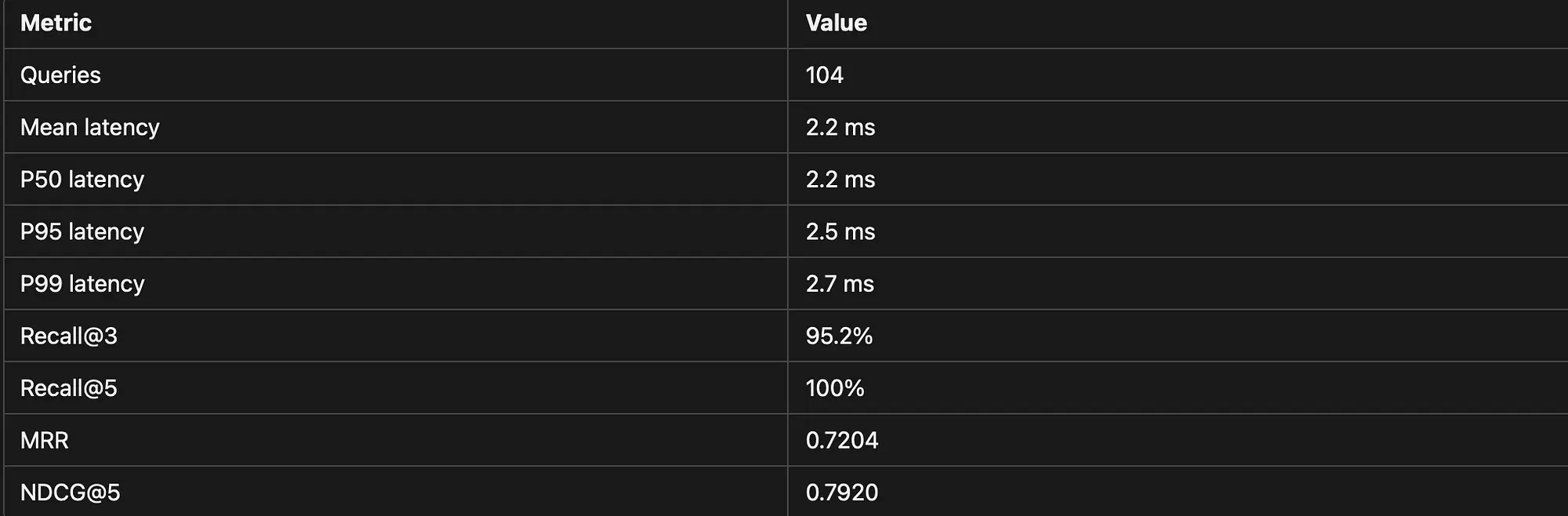
- 平均延迟: 2.2毫秒 / P95:2.5毫秒
- Recall@3: 95.2%(104个查询中有99个在前3名中返回了目标产品)
- Recall@5: 100%
- MRR: 0.7204 / NDCG@5:0.7920
5个失败是边缘情况,查询分解器将所有内容路由到一个方面,但产品的信号存在于不同的字段中。
值得说明的诚实告诫:
- 这是4个产品。2.2毫秒在10万个产品时不会保持不变。
- 基准查询是从它们检索的同一固定数据生成的。存在一些过拟合。
- 二值量化显著降低了Recall@3。将32位浮点压缩为1位对ColBERT的令牌级匹配来说过于极端。从标量INT8开始,在部署前测量召回率。
11、何时不构建这个
三个嵌入管道、一个查询分解器和预取编排并不总是正确答案。如果以下任一条件适用,请跳过:
- 简短、统一的查询如"红鞋"或"羊毛衫"。单个密集向量就能很好地处理。
- 没有清晰的产品图片。 SigLIP需要一致的产品摄影。模糊或不一致的拍摄会产生微弱的视觉信号。放弃该字段。
- 没有客户评论。 评论字段增加了复杂性却零收益。跳过它。
- 目录低于1万产品且查询负载低。 更简单的架构可能足够快且维护成本低得多。
- 基础的检索本身就不好。 糟糕的基础嵌入、错误的分块或配置错误的过滤器不会因为添加更多向量而得到修复。多向量放大了信号。如果没有信号可以放大,它们会放大噪声。
12、何时值得构建
当以下所有条件都满足时,复杂性是值得的:
- 查询包含混合意图。 同一搜索字符串中同时包含规格问题、视觉问题和基于评论的问题。在户外装备、时尚、电子产品和美妆中很常见。
- 大规模清晰的产品图片。 10万+SKU,有一致的产品摄影。SigLIP通道在这里值得其存储成本。
- 评论持续到达。 如果评论每天更新,
update_vectors模式相比批量重新索引变得真正有价值。 - 你有用户画像数据。 个性化层需要信号才能工作。没有它,重排序步骤只是在添加噪声。
13、从头开始的实施路径
不要跳过第1步。单向量基线不仅仅是脚手架。它是衡量额外复杂性是否确实改善了你特定目录结果所需的对照组。
我见过团队第一天就添加三个嵌入管道,因为这个架构听起来令人印象深刻,然后花三周时间试图弄明白为什么召回率变差了。它变差是因为他们的基础嵌入本来就不好。在添加楼层之前先打好地基。
14、构建这个之后真正改变的事情
我回过头来,在完成的系统上运行了原始的"防水黑色登山靴,带良好足弓支撑"查询。排名第1的是TrailForge StormShield。排名第2的是EcoTrek TerraDry。
两者都是真正的登山靴,在客户评论中有真实的足弓支撑记录。
切尔西靴消失了。
关键洞察不是多向量很神奇。关键洞察是原始的设置是要求一个数字代表三种不同类型的证据,而一个数字是不够的。解决方案是停止压缩,开始分离。
生产中的大多数搜索质量问题不是模型问题。它们是信号表示问题。将正确的模型指向混乱的数据会不断返回错误的答案。分离信号才是真正的工作。模型只是工具。
"你的搜索返回了技术上相关但没人点击的结果?问问自己,你在将多少种不同类型的用户意图压缩进一个相似度分数中。"
完整的源代码、测试、基准运行器、FastAPI端点、Streamlit UI和真实产品数据集都在: Github
本文描述的所有内容都映射到src/commerce_engine中的真实文件。没有占位函数,没有伪代码,没有含糊不清的实现细节。
15、项目一览
这是什么: 一个面向电商的多维度语义搜索引擎,在检索前将每个查询拆分为视觉、规格和评论信号。
技术栈:
- 向量数据库:Qdrant
v1.15.3配合qdrant-client>=1.15.0 - 视觉嵌入:
google/siglip-base-patch16-224(768维,通过Hugging Face Transformers) - 文本嵌入:
answerdotai/answerai-colbert-small-v1(96维,通过FastEmbed,ColBERT晚期交互) - 评论嵌入:
BAAI/bge-small-en-v1.5(384维,通过FastEmbed,每个发现) - API:FastAPI + Typer CLI
- UI:Streamlit
- Python:3.11+
自己运行:
git clone https://github.com/dvy246/qdrant-multivector.git
cd qdrant-multivector
uv sync --extra dev
docker compose up -d qdrant
EMBEDDING_BACKEND=deterministic uv run engine init-qdrant
EMBEDDING_BACKEND=deterministic uv run engine ingest --fixtures
EMBEDDING_BACKEND=deterministic uv run engine search \
"Waterproof black hiking boots with good arch support" --user user_a
原文链接:Multi-Aspect E-Commerce Semantic Engine Using Qdrant Multivectors
汇智网翻译整理,转载请标明出处
