我的 ReAct 智能体像一台老虎机
我如何将一个需要30次LLM调用的ReAct智能体重设计为只需要2次LLM调用的确定性图,成本降低了一个数量级,并弄清了AI工具的局限性所在

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
一个星期六上午9点,我坐下来处理一个小型自主工作流的规格说明。从数据库读取记录,应用一堆业务规则,查阅一些非结构化的政策文档,然后把决策写回去。
我在六小时内让它端到端运行起来。大部分代码是Claude Code生成的。架构设计没有。
这个区别就是整篇文章的核心。
1、第一个版本代价高昂
我的第一直觉是最明显的那种:给LLM一组工具,写一个解释工作流的系统提示词,让它自己推理完成。经典的ReAct模式。这是每个教程都会采用的模式,Claude Code大约十分钟就能搭建一个。
它也确实能运行。差不多吧。
它读取了记录,调用了聚合工具,调用了供应商查询工具。它到了运行结束,返回了一个结果,但结果以难以预测的方式是错误的。有时它跳过了一条记录。有时它把两个数字相加得到一个既不是和也不是差的第三个数字。有时在相同输入的不同运行之间,工具调用顺序颠倒了。
我数了LLM调用次数。每次运行二十到三十次。每一次都是到前沿模型的往返,每一次都是一个小小的骰子投掷——模型是否会调用正确的工具——每一次都计费。
这是教程中不会出现的部分。一个在你已经理解的工作流上的纯ReAct智能体是一台你在付费运营的老虎机。
对于一个步骤已知、顺序已知、数学必须精确的问题来说,这是错误的工具。
2、从$$$到$的重设计
我删除了ReAct循环。我把整个东西重写为具有八个节点的固定图。六个是普通Python函数。两个调用LLM。状态对象是一个贯穿每个节点的类型化字典。
class ClaimsState(TypedDict):
db: DatabaseClient
current_date: str
policy_context: str
raw_claims: list
aggregated_exposures: list
eligible_payers: dict
governance_filtered_payers: dict
decisions: list
alerts: list
这就是一个工业级理赔分流工作流的整个共享状态。节点接收它,只返回它们更新的键,然后传递下去。没有魔法。没有决定下一步做什么的推理循环。
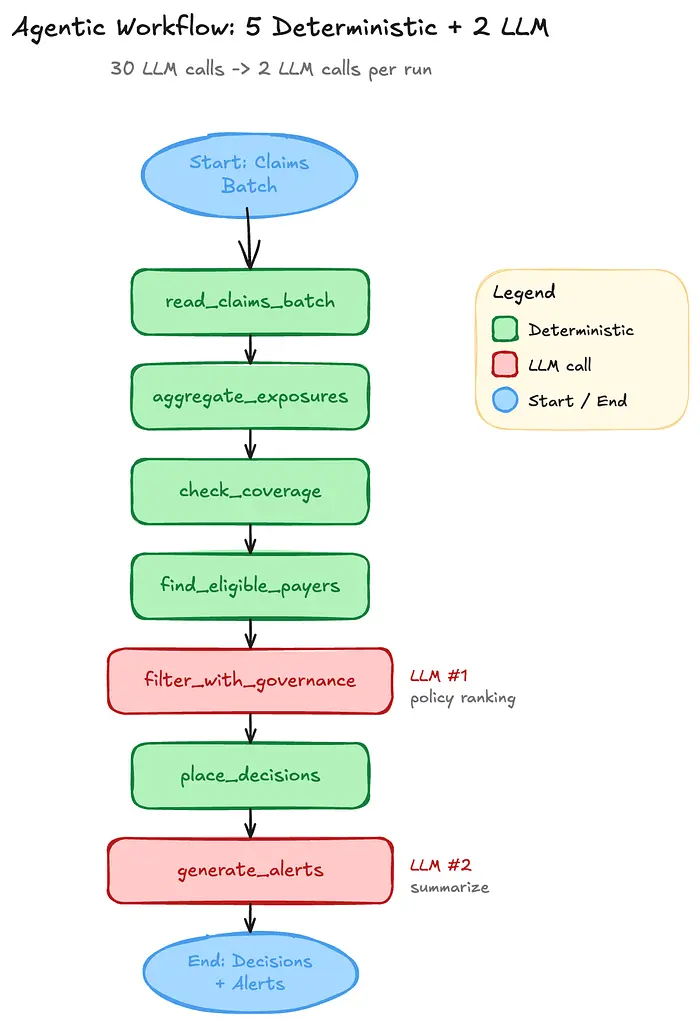
LLM只承担两项工作:
- 读取非结构化的政策PDF并根据它们对候选者进行排名。
- 在最后综合出人类可读的警报摘要。
其他一切——算术部分、基于规则的部分、数据库读取——都变成了确定性的Python。LLM调用次数从每次运行大约三十次降到了两次。在我使用的模型上,这就是每次运行几美元和每次运行几美分的区别。是一个数量级的差异,不是四舍五入的误差。
这是我希望每个读者都能带走的核心观点:找到那一两个LLM确实无法完成的步骤,把LLM放在那里。其他所有地方,写代码。
政策解释就是其中之一。读取一个写着"当患者的计划是PPO时优先选择网络内提供商,除非最近的网络更新备忘录覆盖了它"的PDF,并用通俗英语根据它对列表进行排名——这确实是LLM擅长的事情。两个整数相加不是。
3、LLM仍然试图做算术并出错的地方
有趣的bug出现在重设计开始工作之后。
一个索赔有截止日期。一个付款方有周转时间。检查很简单:today + turnaround <= deadline。我把这个检查放在了LLM治理提示词中,因为LLM已经在筛选候选者了,把这条规则也加进去感觉很自然。
它大约有10%的时间是错误的。特别是边界情况。14天的周转时间对比12天的截止日期会被漏过去。LLM会写一句自信的话解释为什么这个付款方是合适的并批准它们,然后下游节点会愉快地做出一个已经不可行的决策。
修复方法是一个六行的确定性守卫,在LLM看到候选列表之前运行:
delivery_dt = datetime.strptime(current_date, "%Y-%m-%d") + timedelta(days=payer.turnaround_days)
deadline_dt = datetime.strptime(claim["deadline"], "%Y-%m-%d")
if delivery_dt > deadline_dt:
logger.info("payer_excluded_lead_time", payer_id=payer.id)
continue
LLM再也没有机会在这方面犯错了。它现在唯一的工作是在可行选项之间进行排名,这才是它真正擅长的事情。
每次我捕获到LLM不可靠时,根本原因都是我让它做了确定性检查可以完成的事情。把检查移到上游,不可靠性就消失了。
这是一小段无聊的代码。但它也是系统从"演示质量"变成"我真的会信任这个"的时刻。
4、Claude Code写了大部分代码
我想精确说明Claude Code做了什么和没做什么,因为答案不是"它很棒"或"它被过度炒作了"。答案比那更有用。
它擅长的:
- 一旦我告诉它节点名称,就能搭建LangGraph DAG和类型化状态。
- 用适当的上下文管理器和Pydantic模型编写SQLite客户端。
- 从单个提示生成跨Azure OpenAI、OpenAI和Anthropic的LLM提供商工厂。
- 在三十秒内调试"为什么这个Pydantic验证失败"。这以前需要我眯着眼睛看错误消息看十分钟。
- 生成那种机械的、仔细的、有点无聊的代码——我可以写但不喜欢写的代码。
- 用不同场景测试智能体。这是我最喜欢Claude Code能做的事情之一。
它不擅长的,以及我必须自己做的:
- 选择架构。 当我问它"这应该是一个ReAct智能体还是一个固定图"时,它给了我两个选项和平衡的总结。它不了解我的问题。它不知道工作流是一个已知的DAG。它不知道算术正确性是一个硬性要求。我必须做出这个决定。
- 知道LLM是错误的工具。 上面的截止日期守卫修复。Claude Code第一次时愉快地写了我包含截止日期检查的LLM提示词,因为那是我要求的。它不会看着系统说"等等,你正在用一个概率系统做确定性检查,这就是bug。"
- 范围纪律。 放任自流的话,它会在每一行周围添加try/except包装器,生成三层抽象"为了未来的灵活性",并产出一个看起来像Java企业应用的项目结构。它产出的每个文件都需要一轮"删除这个、这个和这个"。
- 把整个系统装在脑子里。 它在一个文件内非常出色。跨八个文件,它就失去主线了。我必须自己知道
nodes.py中状态形状的变更意味着procurement_agent_deterministic.py中的相应变更,即使我没有同时粘贴两个文件。
到那天结束时对我有效的思维模型是:Claude Code是一个快速的、不知疲倦的初级工程师,具有很好的局部品味,但对整个系统没有判断力。 对于你面前的四行代码问题,它是你合作过的最好的初级工程师。但它不会拯救你在决定项目是老虎机还是计算器的架构决策上。
如果你想在七小时内交付一个严肃的东西,这正是你想要的交易。你负责思考,它负责打字。
5、一个收获
如果你在2026年构建智能体工作流,一个深思熟虑的设计和默认的ReAct循环之间的成本差异大约是一个数量级。便宜的版本也是更可靠的版本。这不是你在软件中通常得到的权衡,值得放慢速度来抓住它。
原文链接: My ReAct agent was a slot machine. The deterministic version cost 90% less汇智网翻译整理,转载请标明出处
