基于Qwen3-VL的视觉RAG
视觉RAG允许我们解决"大海捞针"问题,当大海捞针是一堆多模态数据时。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
2026年初,随着Qwen3-VL-Embedding和Qwen3-VL-Reranker家族的发布,多模态领域发生了转变。这些模型建立在最先进的Qwen3-VL基础模型之上,解决了行业中最持久的"大海捞针"RAG问题——大海捞针是一座包含图表、视频和视觉文档的复杂多模态数据山。
视觉RAG允许我们解决"大海捞针"问题,当大海捞针是一堆多模态数据时。
通过将文本、图像和视频映射到共享的嵌入空间,我们终于可以超越基于简单OCR的检索,实现对视觉数据的真正语义理解。
1、系统架构概述
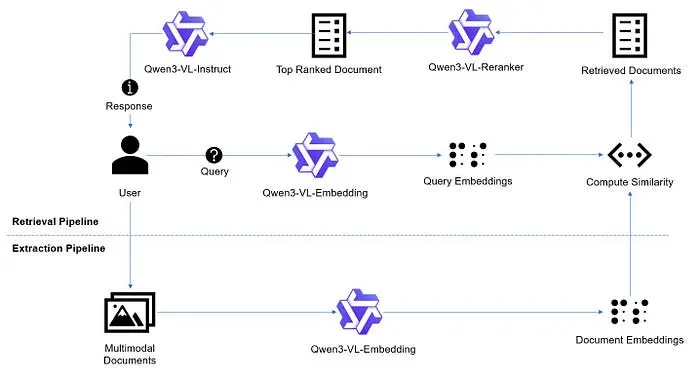
该架构分为两个主要阶段:提取管道和检索管道。在提取阶段,多模态文档(包含文本和视觉数据)由Qwen3-VL-Embedding模型处理,以生成高维向量表示。这些文档嵌入存储为系统的可搜索知识库。
当用户提交查询时,检索管道被触发。Qwen3-VL-Embedding模型将用户的输入转换为查询嵌入,然后与现有的文档嵌入进行比较以计算相似度。此过程识别一组可能相关的检索文档。为了确保最高的准确性,这些候选文档通过Qwen3-VL-Reranker,将其缩小到最相关的单个顶级文档。这种两阶段检索和重新排序的方法显著提高了检索准确性。最后,Qwen3-VL-Instruct模型将这一特定上下文与原始用户查询合成,生成一个基于上下文的准确响应。
1.1 Qwen3-VL-Embedding
与传统的嵌入模型不同,Qwen3-VL-Embedding模型处理多模态输入——包括文本、图像和视频,并生成语义丰富的向量,在共享嵌入空间中捕获视觉和文本信息。简单来说,这意味着文本"一只狗在公园里玩"的嵌入和一只狗在公园里玩的实际图像的嵌入将非常相似。这种跨模态语义相似性促进了跨不同模态的高效相似性计算和检索。
在这一点上,值得注意的是,由于Qwen3-VL-Embedding基于Qwen3-VL模型,它需要特定的输入格式,如他们的论文中所述。

{instruction}是一个占位符,表示嵌入模型应该如何处理数据。非查询嵌入的默认指令是'表示用户的输入。'。对于查询嵌入,默认指令是'检索与用户查询相关的图像或文本。'
{instance}标签是您想要嵌入的数据的占位符,可以是文本、图像或视频的形式。对于图像,我们使用特殊的令牌系列<|vision_start|><|image_pad|><|vision_end|>来向模型指示图像将在此处插入。在模型内部,视觉编码器构建图像的编码并将其插入那里。换句话说,这些标记告诉模型"这里放一张图像"。
为了完整性,以下是嵌入模型所需的输入模板示例:


1.2 Qwen3-VL-Reranker
重新排序器是"精确"工具,它通过优化结果来补充嵌入模型。它同时查看查询和文档以计算细粒度的相关性分数,显著减少"幻觉"检索。
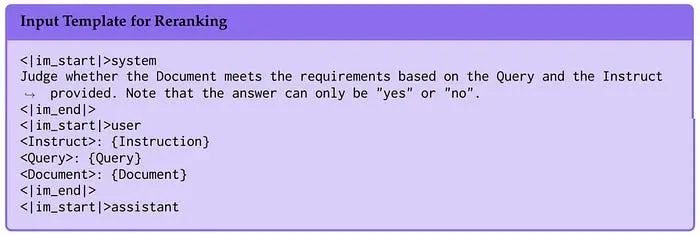
与嵌入模型一样,重新排序器也需要特殊的输入模板。
2、示例用例——多模态问答
让我们通过一个实际用例来分析:Alphabet 2025年第一季度收益幻灯片。像这样的幻灯片对于标准RAG来说是出了名的困难,因为关键数据(收入、增长)被困在复杂的图表中,传统的基于OCR的RAG管道无法访问。
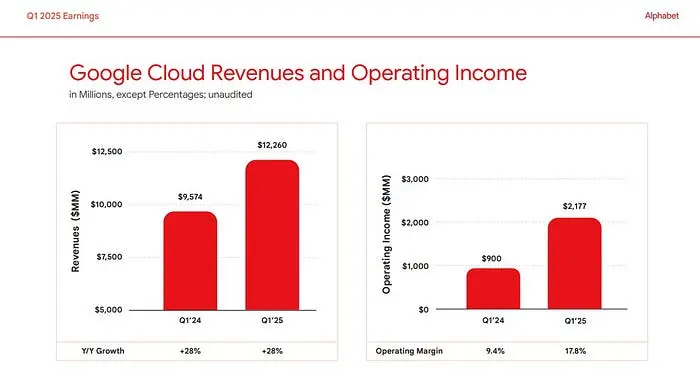
Alphabet 2025年第一季度收益幻灯片的示例幻灯片。关键信息存储在图表中,这对传统的基于OCR的RAG管道构成了挑战。
第一步:初始化嵌入模型
我们使用vLLM作为我们的高吞吐量推理引擎。
from vllm import LLM
# 初始化嵌入模型
embedding_model = LLM(
model="Qwen/Qwen3-VL-Embedding-2B",
runner="pooling",
dtype='bfloat16',
trust_remote_code=True,
max_model_len=-1,
)
第二步:构建RAG逻辑
我们创建一个MultiModalRAG类来处理繁重的工作:将PDF页面转换为图像、生成向量和执行相似性搜索。
from helpers import prepare_vllm_inputs_embedding
class MultiModalRAG:
def __init__(self, embedding_model=None):
self.embedding_model = embedding_model
self.documents = []
self.embeddings = []
def embed_pdf(self, pdf_path):
images = convert_from_path(pdf_path)
emb_inputs = []
for idx, img in enumerate(images):
self.documents.append({'pdf_path': pdf_path, 'page_num': idx, 'image': img})
emb_inputs.append({"image": img})
emb_inputs_for_vllm = [prepare_vllm_inputs_embedding(inp, self.embedding_model) for inp in emb_inputs]
emb_outputs = self.embedding_model.embed(emb_inputs_for_vllm)
for output in emb_outputs:
emb = output.outputs.embedding
self.embeddings.append(emb)
def embed_query(self, query):
emb_input = {
"text": query,
"instruction": "Retrieve images or text relevant to the user's query.",
}
emb_input_for_vllm = prepare_vllm_inputs_embedding(emb_input, self.embedding_model)
emb_output = self.embedding_model.embed(emb_input_for_vllm)
query_emb = emb_output[0].outputs.embedding
return query_emb
def search(self, query):
query_embeddings = self.embed_query(query)
similarity_scores = np.array(query_embeddings) @ np.array(self.embeddings).T
top_5_indices = sorted(range(len(similarity_scores)), key=lambda i: similarity_scores[i], reverse=True)[:5]
top_5_documents = [self.documents[i] for i in top_5_indices]
return top_5_documents
multimodal_rag = MultiModalRAG(embedding_model=embedding_model)
请注意,我们调用prepare_vllm_inputs_embedding辅助函数来解析模型所需的输入。
我们可以使用这个类来嵌入PDF文件:
multimodal_rag.embed_pdf("data/slides/2025q1-alphabet-earnings-slides.pdf")
并使用查询在文件上运行搜索:
search_results = multimodal_rag.search("What is Alphabet's Q1 2025 revenue?")
它返回PDF中最相关的5页列表:
[{'pdf_path': 'data/slides/2025q1-alphabet-earnings-slides.pdf',
'page_num': 3,
'image': <PIL.PpmImagePlugin.PpmImageFile image mode=RGB size=2000x1125>},
{'pdf_path': 'data/slides/2025q1-alphabet-earnings-slides.pdf',
'page_num': 6,
'image': <PIL.PpmImagePlugin.PpmImageFile image mode=RGB size=2000x1125>},
{'pdf_path': 'data/slides/2025q1-alphabet-earnings-slides.pdf',
'page_num': 7,
'image': <PIL.PpmImagePlugin.PpmImageFile image mode=RGB size=2000x1125>},
{'pdf_path': 'data/slides/2025q1-alphabet-earnings-slides.pdf',
'page_num': 4,
'image': <PIL.PpmImagePlugin.PpmImageFile image mode=RGB size=2000x1125>},
{'pdf_path': 'data/slides/2025q1-alphabet-earnings-slides.pdf',
'page_num': 5,
'image': <PIL.PpmImagePlugin.PpmImageFile image mode=RGB size=2000x1125>}]
第三步:精确重新排序
一旦我们有了前5个候选,重新排序器将其缩小到最相关的单个幻灯片。
# 初始化Qwen3-VL-Reranker模型
reranker = LLM(
model='Qwen/Qwen3-VL-Reranker-2B',
runner='pooling',
dtype='bfloat16',
trust_remote_code=True,
hf_overrides={
"architectures": ["Qwen3VLForSequenceClassification"],
"classifier_from_token": ["no", "yes"],
"is_original_qwen3_reranker": True,
},
max_model_len=-1
)
我们准备将发送到重新排序器的输入,使用嵌入模型生成的search_results
# 定义查询和候选文档以进行重新排序
inputs = {
"instruction": "Retrieve images or text relevant to the user's query.",
"query": {
"text": "What is Alphabet's Q1 2025 revenue?"
},
"documents": search_results
}
我们使用辅助函数get_rank_scores来解析重新排序器所需的输入并获取排名分数:
# 获取每个文档的相关性分数
scores = get_rank_scores(reranker, inputs)
def get_top_reranker_result(scores, search_results):
top_document_idx = scores.index(max(scores))
return search_results[top_document_idx]
top_reranker_result = get_top_reranker_result(scores, search_results)
第四步:基于上下文的生成
最后,我们将排名最高的幻灯片传递给Qwen3-VL-Instruct模型以提取答案。
# 初始化Qwen3-VL-Instruct模型
vlm = LLM(
model='Qwen/Qwen3-VL-2B-Instruct',
max_model_len=1024*4,
max_num_seqs=1,
)
我们以所需的格式准备输入:
vlm_input = {
"instruction": "You are an expert financial analyst.",
"text": "What is Alphabet's Q1 2025 revenue?",
"image": top_reranker_result['image']
}
vlm_input = prepare_vllm_inputs_embedding(vlm_input, vlm)
我们将其传递给VLM:
sampling_params = SamplingParams(max_tokens=1024, temperature=0.01)
vlm_output = vlm.generate(vlm_input, sampling_params)
3、结果
系统正确地识别了收入图表并提取了特定数据点。我们可以看到VLM对提供的图像和文本提示进行联合推理,使其能够生成准确的答案。
根据提供的名为"Alphabet收入和营业收入"的图表,我们可以确定Alphabet 2025年第一季度的收入。
左侧的图表显示了两个季度的"收入(百万美元)"。2025年第一季度的数据显示在图表的右侧。
- 对应于Q1ཕ(2025年第一季度)的条形图在y轴上达到了$90,234的值。
- y轴标记为"收入(百万美元)",单位是百万美元。
因此,Alphabet 2025年第一季度的收入为$90,234百万美元。
完整代码可以在此仓库中找到:
GitHub - jamesloyys/Multimodal-RAG
4、结束语
在2026年,RAG不再只是关于文本块和关键词。随着Qwen3-VL系列的发布,我们进入了一个AI"看到"上下文就像它"阅读"上下文一样的时代。对于金融分析师、研究人员和开发人员来说,这个统一框架是多模态智能的新黄金标准。
原文链接: Building State-of-the-Art Vision-Enabled RAG Pipelines (2026)
汇智网翻译整理,转载请标明出处
