RAG重排序器实践
本文分享我现在对重排序器的思考——它们为什么存在、在现代 RAG 系统中处于什么位置,以及将它们投入生产时真正需要权衡什么。
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
如果您曾经将检索增强生成(Retrieval-Augmented Generation,简称 RAG)系统交付给真实用户,您就已经知道那个令人不安的事实:检索质量比模型大小更重要。
过去几年,我一直在不同团队构建搜索、推荐和 RAG 流水线——包括支持机器人、内部知识助手和面向用户的语义搜索。每当时延预算收紧或者演示中出现幻觉时,问题从来不是 LLM。而是上下文。
这就是重排序器默默发挥作用的地方。
在这篇文章中,我将分享我现在对重排序器的思考——它们为什么存在、在现代 RAG 系统中处于什么位置,以及将它们投入生产时真正需要权衡什么。我还会展示一个使用向量数据库(在本例中是 Milvus)的具体示例,并讨论重排序何时有帮助——何时完全没有帮助。
这不是一篇宣传文章。而是关于什么有效、什么无效,以及我希望早点知道的事情。
1、为什么"足够好"的检索在大规模场景下会失败
大多数团队以相同的方式开始构建 RAG:
- 分块文档
- 生成嵌入(embeddings)
- 运行近似最近邻搜索
- 将 top-k 个分块发送给 LLM
它的效果出奇地好——直到它不再奏效。
最初的裂痕通常出现在这些时候:
- 文档在语义上相似但上下文不同
- 查询简短、模糊或具有对话性
- 需要高精度,而不仅仅是语义接近度
密集检索擅长召回(recall),而不是精度(precision)。这就是设计使然。嵌入压缩的是意义,而不是意图。
一旦我理解了这一点,重排序就不再感觉是可选的了。
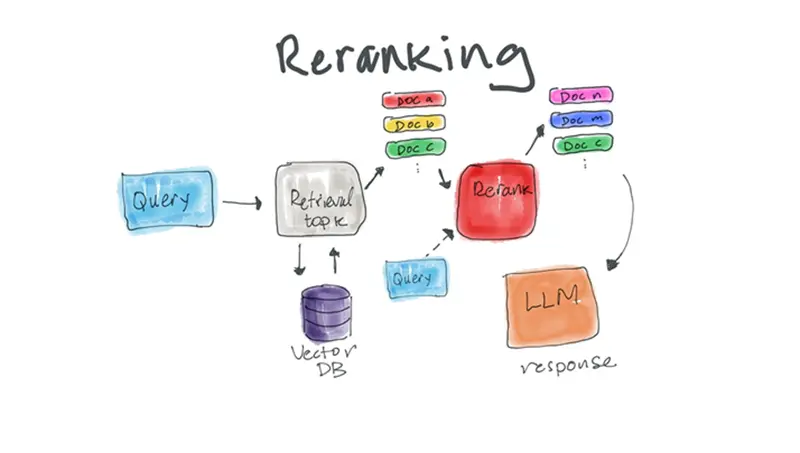
2、重排序器:它们实际做什么
重排序器不会替代您的向量搜索。它改进它。
可以这样理解流水线:
- 向量搜索 → 广泛的语义召回
- 重排序 → 细粒度的相关性判断
与比较查询和文档嵌入不同,重排序器通常直接评估查询-文档对,通常使用交叉编码器架构。
实际影响:
- 更好的 top-k 结果排序
- 发送给 LLM 的不相关分块更少
- 下游幻觉率更低
如果您是 RAG 模式的新手,这篇关于检索增强生成的概念性文章是很好的复习。但真正的价值体现在从图表转向指标时。
3、我第一次正确测量重排序效果
起初我没有"感觉"到改进。我测量了它。
我们评估了:
- 内部 QA 数据集上的 Precision@k
- 答案引用准确性
- 每个请求的 LLM token 使用量
令人惊讶的结果?重排序往往降低了总系统成本,尽管它增加了额外的模型调用。
为什么?更少的不相关分块意味着:
- 更短的提示词
- 更少的 LLM 往返交互
- 更确定性的答案
这与我反复观察到的现象一致:检索质量直接影响成本曲线。如果您正在建模此问题,RAG 成本计算器等工具实际上对粗略规划很有用。
4、向量数据库适合什么场景
向量数据库处理它们最擅长的事情:
- 高吞吐量的相似性搜索
- 索引数百万(或数十亿)个嵌入
- 元数据过滤和混合查询
一些系统——例如 Milvus——可以轻松地高效检索候选集。但重排序通常发生在向量索引之外。
这种分离很重要。
我见过团队试图用越来越复杂的启发式方法使向量搜索过载。这几乎总是适得其反。保持检索快速且近似。让重排序器进行昂贵的思考。
如果您需要嵌入本身的基础知识,这篇关于向量嵌入的词汇表是一个可靠的参考资料。
5、一个最小化、现实的 RAG + 重排序器示例
这是一个简化的 Python 示例,展示了我通常如何组织这些内容。这不是玩具代码——它的结构接近我实际部署的代码。
from pymilvus import connections, Collection
from sentence_transformers import SentenceTransformer
from my_reranker import rerank # placeholder for any cross-encoder reranker
# 1. Connect to Milvus
connections.connect("default", host="localhost", port="19530")
collection = Collection("docs")
# 2. Embed the query
embedder = SentenceTransformer("all-MiniLM-L6-v2")
query = "How do we rotate API keys safely?"
query_embedding = embedder.encode([query])[0]
# 3. Vector search (recall-focused)
results = collection.search(
data=[query_embedding],
anns_field="embedding",
param={"metric_type": "IP", "params": {"nprobe": 16}},
limit=20,
output_fields=["text"]
)
candidates = [hit.entity.get("text") for hit in results[0]]
# 4. Rerank (precision-focused)
reranked = rerank(query, candidates)
# 5. Send top results to LLM
context = reranked[:5]# 1. Connect to Milvus
connections.connect("default", host="localhost", port="19530")
collection = Collection("docs")
这里的关键设计选择:
- 向量搜索返回的内容超过您的需求
- 重排序激进地修剪上下文
- LLM 只看到最高置信度的分块
这种模式扩展良好,并且使失败模式易于理解。
6、多模态 RAG 使重排序更加重要
一旦超越文本——图像、音频转录、图表——噪声基准线就会迅速上升。
在多模态系统中,嵌入可以捕获相似性,但不能捕获任务相关性。我见过没有重排序的图像密集型 RAG 系统完全崩溃。
如果您正在探索这一领域,这篇关于多模态 RAG的文章值得一读。要点很简单:您添加的模式越多,就越需要强大的相关性过滤器。
7、延迟、吞吐量和重排序器的权衡
重排序器不是免费的。
您需要付出的代价:
- 额外的推理时间
- GPU 或 CPU 利用率
- 系统复杂性
对我有效的方法:
- 小候选集(最多 10-30 个文档)
- 批量重排序
- 对重复查询进行激进缓存
如果您的系统有严格的延迟 SLA,则有选择性地进行重排序。并非每个查询都需要它。在一些生产设置中,我们只重排序:
- 长尾查询
- 模糊查询
- 高价值用户流程
没有通用的规则——只有测量。
8、智能体和语音驱动系统中的重排序器
在智能体工作流中——尤其是语音助手中——重排序不再关乎精度,而更多地关乎置信度。
当系统必须行动而不仅仅是回答时,错误的上下文比缺失的上下文更糟糕。
我在基于智能体 RAG 模式构建的语音助手中清楚地观察到了这一点。如果您好奇这如何端到端地组合在一起,这篇关于使用智能体 RAG 构建语音助手的演练很好地展示了各个组件。
9、何时重排序是错误的工具
让我们诚实一点——重排序器无法修复:
- 糟糕的分块
- 过时的数据
- 不良的领域覆盖
如果您的嵌入不能很好地表示领域,重排序只是重新排列糟糕的候选者。
我的经验法则:
先修复数据和嵌入。然后重排序。
重排序器放大信号。它们不创建信号。
10、来自实战的最终要点
在交付多个 RAG 系统后,我的立场很简单:
- 密集检索让您接近正确
- 重排序让您真正正确
- 测量让您保持诚实
重排序器并不迷人。演示效果不佳。但当您的系统停止幻觉并开始引用正确的来源时,它们通常是原因所在。
如果您已经在生产环境中运行 RAG 而没有重排序,您可能正在失去质量——以及金钱。
而如果您正在重排序?测量它。调整它。质疑它。真正的收益就出现在那里。
原文链接: Rerankers in Production: What Actually Moved the Needle for My RAG Systems
汇智网翻译整理,转载请标明出处
