SLM vs. LLM:全面对比
问题不在于小模型能否替代大模型,而在于你是否在为工作选择了正确的工具。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
你一直在使用 GPT-4、Claude 或 Gemini 进行开发。它们的输出令人印象深刻,推理能力深不可测,模型似乎对一切都略知一二。然后你收到了账单。一个每天进行数千次调用的生产应用,成本突然超过了你整个计算基础设施。高峰时段的延迟飙升。你开始寻找开源替代方案,但即使是一个 700 亿参数的模型也需要多块 A100 才能以可接受的速度运行。
在光谱的另一端,一场更安静的革命正在发生。拥有 20 亿参数的模型——小到可以在单个 GPU 甚至 CPU 上运行——开始在小规模上匹配那些大玩家。它们并非更差,而是不同。对于越来越多的现实世界问题,"不同"恰恰是你所需要的。
问题不在于小模型能否替代大模型,而在于你是否在为工作选择了正确的工具。
1、没人愿意谈论的成本问题
大语言模型是令人难以置信的工程成果。一个拥有数千亿参数的前沿模型可以在同一次对话中跨领域推理、写诗、调试代码并解释量子力学。但这种广度是有代价的。
以下是在生产环境中运行 LLM 的真实情况:
- 推理成本随使用量增长: 每百万 token 5 到 60 美元,高流量应用每天可能累积数千美元
- 延迟不可预测: 更长的输出和更高的负载意味着更慢的响应,损害用户体验
- 基础设施笨重: 自托管 700 亿+ 参数的模型需要多块高端 GPU、复杂的编排和专业的 ML 工程师
- 微调成本高昂: 为你的领域重新调整一个大型模型可能花费数万美元和数周的实验
对于许多团队来说,LLM 的账单成为其基础设施预算中最大的一项。而令人沮丧的是:大量计算实际上被浪费了。你的应用不需要一个能解释哲学的模型。它需要一个能够分类支持工单、提取实体或生成结构化 JSON 的模型。这些都是窄的、定义明确的任务。而窄任务正是小模型大放异彩的地方。
2、什么是小型语言模型?
小型语言模型(SLM)是大语言模型的紧凑版本,通常具有不到 100 亿个参数。它们专为聚焦的、特定任务的问题而设计,而非广泛的通用推理。
可以这样理解:LLM 是一座研究图书馆,里面有各种学科的书籍,可以在截然不同的领域之间找到联系。SLM 则是一位专业顾问,对某个领域了如指掌,响应更快,成本仅为后者的一小部分。
3、一览表
| 属性 | SLM | LLM |
|---|---|---|
| 参数范围 | 50M - 3B | 10B - 1T+ |
| 基础设施 | 单CPU/GPU,小集群 | 大集群,多GPU |
| 每百万token成本 | $0.05 - $0.50 | $5 - $60 |
成本差异是惊人的。SLM 每 token 的成本可以比前沿 LLM 便宜一到两个数量级。对于高流量应用来说,这就是可控账单和预算危机之间的区别。
4、核心洞见:规模不等于能力
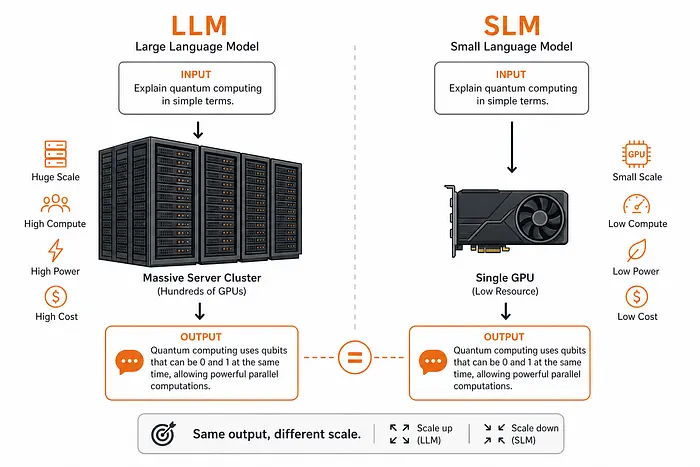
给定相同的提示,一个大约 20 亿参数 的 SLM 和一个 数千亿参数 的 LLM 可以产生 相当的输出 —— 而成本仅为后者的一小部分。
尽管规模小得多,SLM 在应用于聚焦的、特定任务的问题时可以达到相似的性能。
5、各模型的优势领域

大语言模型擅长广泛的通用知识,这就是为什么它们需要数千亿参数。它们为广度而生,能够跨几乎所有领域进行推理,无需特定任务的训练。
小型语言模型则在问题定义明确时大放异彩。在特定领域的任务上,一个 20 亿参数的 SLM 可以匹配甚至超越更大的模型。
SLM 擅长的领域特定任务
- 逻辑谜题: 具有清晰规则的结构化推理
- 客户支持: 工单分类和路由
- 产品标签: 从描述中提取属性
- 代码生成: 样板代码和聚焦的语言任务
6、核心权衡
| 维度 | LLM | SLM |
|---|---|---|
| 广度 | 优秀 - 通用 | 有限 - 任务特定 |
| 深度(聚焦任务) | 良好 | 匹配或超越LLM |
| 部署成本 | 高 | 低 |
| 推理速度 | 较慢 | 更快 |
| 微调成本 | 非常高 | 低(通过LoRA) |
| 本地部署 | 很少可行 | 常规可行 |
| 隐私/本地部署 | 困难 | 简单 |
规律很明确。如果你的问题是开放式的、模糊的,或需要跨领域推理,你需要 LLM。如果你的问题是窄的、结构化的、可重复的,SLM 几乎肯定是更好的选择。
7、为什么 SLM 现在就实用
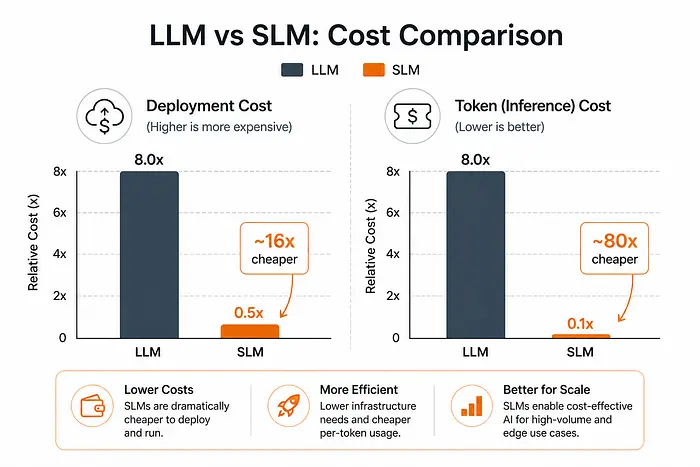
一个典型的拥有 20 亿参数 的 SLM 可以在 1 万到 50 万美元 的硬件成本下本地部署,与 LLM 的基础设施需求相比,这是一个巨大的缩减。
但硬件故事只是一半。运营上的好处同样重要:
- 易于托管: 在单个 CPU/GPU 上运行,无需云依赖。无需复杂的编排,无需多节点设置。
- 价格实惠: 每 token 成本比前沿 LLM 便宜一个数量级。对于高调用量的应用,这完全改变了经济性。
- 运营轻量: 更低的维护成本,更容易版本管理和重新部署。你可以在几小时内(而非几天)迭代你的模型。
- 默认隐私: 因为你可以在本地或气隙机器上运行它,敏感数据永远不会离开你的环境。
NVIDIA 已将 SLM 视为未来智能体 AI 的关键驱动力。当一个自主智能体需要数十次或数百次模型调用来完成一项任务时,每次调用都使用前沿 LLM 在经济上是不可能的。SLM 使智能体管道在大规模上变得可行。
8、语言模型是如何变小的?
SLM 并非凭空出现。它们是多层优化技术叠加的结果,逐步将模型从数千亿参数压缩到 20-200 亿,而没有灾难性的质量损失。
流程如下:
LLM (900B Params) -> SLM (20B Params) -> SLM (2B Params)
| 量化 | LoRA微调 | Flash Attention
9、三大核心优化技术
| 技术 | 作用 |
|---|---|
| 量化 | 降低模型权重的数值精度 |
| LoRA微调 | 避免重新训练整个模型 |
| Flash Attention | 重写注意力计算方式以提升速度和节省内存 |
每种技术解决不同的瓶颈。量化缩小模型体积。LoRA 使专业化变得廉价。Flash Attention 消除了长序列的内存墙。它们共同使小模型不仅成为可能,而且具有竞争力。
9.1 量化
降低模型权重的数值精度,在不重新训练的情况下缩小内存占用。
工作原理
模型权重以逐渐降低的位精度存储:
FP32 → FP16 → INT8 → INT4
(完整) (半精度) (8位) (4位)
高精度(FP32) 将 3.14、2.72 等值存储为完整的 32 位浮点数——精确但占用内存大。量化(INT8) 将相同的值存储为 3、2——取整的整数,内存占用减少 4 倍。
这适用于每个层级:标量、向量、矩阵和存储为 GPU 参数的完整张量。现代量化感知训练在保持输出质量方面表现惊人地好,特别是对于仅推理的工作负载。
影响
- 4 到 8 倍的内存缩减,取决于目标精度
- 更快的推理,由于更小的内存带宽需求
- 对大多数任务的精度损失最小,特别是仅推理的工作负载
现代量化感知训练在保持输出质量方面表现惊人地好,特别是对于仅推理的工作负载。
代码示例:
"""
quantization_example.py
演示如何使用 Hugging Face Transformers 和 BitsAndBytesConfig
以 4 位量化精度加载小型语言模型(SLM)。
量化降低了模型权重的数值精度,在不重新训练的情况下将内存占用
缩减 4 到 8 倍。这使得在仅 4GB VRAM 的消费级 GPU 上运行
30 亿+ 参数的可用模型成为可能。
依赖:
pip install transformers accelerate bitsandbytes
"""
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
def load_quantized_model(model_id: str = "microsoft/Phi-3-mini-4k-instruct"):
"""
以 4 位(INT4)精度加载因果语言模型。
参数:
model_id: Hugging Face 模型标识符。
返回:
准备推理的 (model, tokenizer) 元组。
"""
# 量化配置:以 4 位精度加载模型
# 与 FP16 相比,内存使用量减少约 4 倍
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True, # 嵌套量化以额外节省
bnb_4bit_quant_type="nf4", # 归一化浮点 4 位
)
# 加载量化模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quant_config,
device_map="auto", # 自动将层卸载到 GPU/CPU
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
return model, tokenizer
def generate_response(model, tokenizer, prompt: str, max_new_tokens: int = 150) -> str:
"""
从量化模型生成响应。
参数:
model: 量化的因果语言模型。
tokenizer: 对应的分词器。
prompt: 输入文本提示。
max_new_tokens: 最大生成 token 数。
返回:
解码后的响应字符串。
"""
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
if __name__ == "__main__":
print("正在加载量化模型...")
model, tokenizer = load_quantized_model()
prompt = "Explain quantization in simple terms."
print(f"\nPrompt: {prompt}\n")
response = generate_response(model, tokenizer, prompt)
print(response)
# 内存占用对比(Phi-3-mini 的近似值):
# FP16: ~3.8 GB
# INT4: ~1.0 GB
# 你现在可以在 4GB VRAM 的消费级 GPU 上运行一个 38 亿参数的可用模型。
结论: 量化是此列表中最容易获得的收益。如果你在自托管任何模型,你几乎肯定应该运行量化版本。内存节省是即时的,速度提升是真实的,对大多数生产任务的精度损失可以忽略不计。
9.2 低秩适应(LoRA)微调
通过注入小型可训练矩阵到冻结的基础模型中,避免重新训练整个模型。
传统微调的问题
传统的全模型微调为每个任务创建一个单独的完整模型副本。如果你有 3 个任务和一个 110 亿参数的模型,你最终需要管理 330 亿参数的特定任务权重。那是 330 亿个浮点数需要存储、版本管理、加载和服务。在规模化时,这在运营上是不切实际的。
LoRA 的不同之处
LoRA 不是更新所有权重,而是:
- 完全冻结基础模型权重
- 训练小型低秩矩阵(远少于参数)插入到冻结权重旁边
- 通过提示调优在推理时高效注入特定任务行为,多个任务共享一个基础模型,每个任务的轻量级适配器只有约 2 万参数(而不是 110 亿)
数学原理很优雅。对于模型中的权重矩阵 W,LoRA 学习一个分解 W + BA,其中 B 和 A 是秩为 r << d 的小矩阵。你不再更新 d x d 的权重,而是更新 d x r 和 r x d 的权重——只占总量的一小部分。
为什么这很重要
- 微调成本大幅降低,从数千美元降至数十美元的计算成本
- 基础模型大小保持小巧,无需每个任务一份完整模型副本
- 多个任务适配器可以共享一个基础模型,实现高效的多任务部署
这是 SLM 在规模化时变得实用的最大原因之一。
代码示例:
"""
lora_example.py
演示使用 Hugging Face PEFT(参数高效微调)对小型语言模型
进行低秩适应(LoRA)微调。
LoRA 冻结基础模型权重并训练插入其旁边的小型低秩矩阵。
这将可训练参数从数十亿减少到数百万(或更少),
使特定任务的微调变得廉价和快速。
依赖:
pip install transformers peft datasets accelerate
"""
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
Trainer,
)
from peft import LoraConfig, get_peft_model, TaskType
from datasets import Dataset
import torch
def setup_lora_model(model_id: str = "microsoft/Phi-3-mini-4k-instruct", rank: int = 16):
"""
加载基础模型并用 LoRA 适配器包装。
参数:
model_id: Hugging Face 模型标识符。
rank: LoRA 秩(越低 = 参数越少)。
返回:
PEFT 包装的模型和分词器。
"""
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
lora_config = LoraConfig(
r=rank,
lora_alpha=rank * 2,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM,
)
peft_model = get_peft_model(model, lora_config)
peft_model.print_trainable_parameters()
return peft_model, tokenizer
def create_dummy_dataset():
"""
创建一个微型数据集用于演示。
实际使用中,应使用数百到数千个标注示例。
"""
train_data = [
{
"text": (
"Instruction: Classify this support ticket.\n"
"Input: My order never arrived.\n"
"Output: Shipping Issue"
)
},
{
"text": (
"Instruction: Classify this support ticket.\n"
"Input: The app crashes when I click checkout.\n"
"Output: Bug Report"
)
},
{
"text": (
"Instruction: Classify this support ticket.\n"
"Input: I want a refund.\n"
"Output: Refund Request"
)
},
]
return Dataset.from_list(train_data)
def main():
print("正在设置 LoRA 模型...")
peft_model, tokenizer = setup_lora_model()
dataset = create_dummy_dataset()
def tokenize(example):
return tokenizer(
example["text"],
truncation=True,
padding="max_length",
max_length=128,
)
tokenized = dataset.map(tokenize, batched=True)
training_args = TrainingArguments(
output_dir="./lora_output",
num_train_epochs=3,
per_device_train_batch_size=1,
learning_rate=2e-4,
logging_steps=1,
save_strategy="no",
fp16=True,
)
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=tokenized,
)
print("\n开始 LoRA 微调...")
trainer.train()
# 仅保存适配器(约20MB),而非完整模型
peft_model.save_pretrained("./lora_adapter")
print("适配器已保存到 ./lora_adapter")
# 推理时,加载基础模型 + 适配器:
# from peft import PeftModel
# base_model = AutoModelForCausalLM.from_pretrained(model_id, ...)
# model = PeftModel.from_pretrained(base_model, "./lora_adapter")
if __name__ == "__main__":
main()
结论: LoRA 是特定领域 SLM 变得可负担的原因。没有它,微调仍然是资金充足的研究实验室的领域。有了它,一个工程师可以在一个下午用单个 GPU 将一个 30 亿参数的模型适配到新任务。
9.3 Flash Attention
重写注意力机制的内部计算,使其内存高效且缓存友好。
问题:注意力计算代价高昂
标准注意力通过将完整的注意力矩阵读写到 GPU 高带宽内存(HBM)来计算所有 query-key-value 交互。这创建了一个随更长序列呈指数级恶化的内存瓶颈。对于长度为 N 的序列,注意力矩阵为 N x N。在 8K token 时,那是 6400 万个条目。在 32K token 时,超过 10 亿个。
GPU 内存层次结构(背景)
| 内存类型 | 带宽 | 大小 |
| ----------- | --------- | ------ |
| GPU SRAM | 19 TB/s | ~20 MB |
| GPU HBM | 1.5 TB/s | ~40 GB |
| CPU DRAM | 12.8 GB/s | >1 TB |
Flash Attention 重新组织计算,通过 SRAM(快速、小型)进行分块,而不是反复访问 HBM(慢速、大型),大幅减少内存读写。
Flash Attention 改进了什么
- 内存效率: 避免在 HBM 中实例化完整的 N×N 注意力矩阵
- 缓存利用率: 将操作分块以适应快速 SRAM
- 长序列速度: PyTorch 标准注意力与 Flash Attention 的对比显示了显著的挂钟时间缩减(在 GPT-2 规模的基准测试中可见)
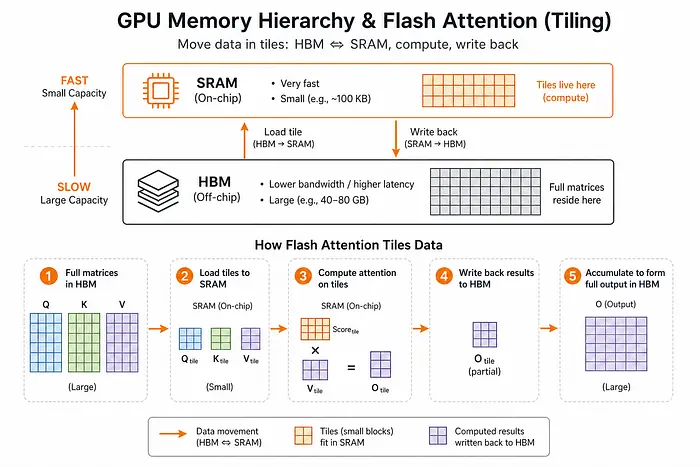
即使是较小的模型也会在长上下文的注意力计算上遇到瓶颈。Flash Attention 消除了这个瓶颈,让 SLM 能够处理比其参数规模通常允许的更长的输入——弥合了与 LLM 在上下文长度上的差距。
10、完整优化技术栈总结
| 技术 | 主要收益 | 内存节省 | 微调成本 | 推理速度 |
|---|---|---|---|---|
| 量化 | 更小的模型体积 | 4x--8x缩减 | 无(训练后) | 更快 |
| LoRA微调 | 廉价的任务特化 | 基础模型不变 | 大幅降低 | 不变 |
| Flash Attention | 更快的长上下文推理 | 显著(减少HBM使用) | 无 | 长输入上快得多 |
这三种技术并非互斥的。在实践中,生产级 SLM 部署通常同时使用三种:一个量化的基础模型,用 LoRA 适配器进行微调,运行 Flash Attention 进行高效推理。这就是你如何以 1% 的成本在窄任务上获得 GPT-4 级别质量的方法。
11、何时选择 SLM 还是 LLM
以下是一个实用的决策框架:
使用 SLM 的情况:
- 你的任务定义明确且范围窄
- 你需要本地或本地部署
- 每 token 成本是一个约束
- 你需要快速推理/低延迟
- 隐私或数据主权很重要
- 你可以用 LoRA 在领域数据上微调
- 你正在构建具有多次 LLM 调用的智能体管道
使用 LLM 的情况:
- 你需要广泛的通用推理
- 任务是模糊的或开放式的
- 你无需微调就需要深度的多领域知识
- 需要跨领域的复杂多步推理
- 你无法投入时间进行特定任务的微调
最聪明的架构不是只选一个。它们将任务路由到正确的工具。从 SLM 开始处理你 80% 可预测的工作负载,只在真正需要时才升级到 LLM 处理那 20% 模糊的部分。
12、结束语
多年来,围绕 AI 的叙事一直痴迷于规模。更大的模型、更大的集群、更大的预算。但 2025 和 2026 年的真正故事是专业化。我们正在认识到,智能不仅仅关乎参数数量,更关乎将正确的能力匹配到正确的问题。
小型语言模型不是降级。它们是一个不同的产品类别,用效率交换广度,用领域专注交换通用知识,用本地控制交换云依赖。对于构建生产系统的团队来说,这笔交易通常是值得的。
使 SLM 变得可行的技术——量化、LoRA 和 Flash Attention——对任何拥有 GPU 和一个下午的工程师都是可用的。你不需要一个研究实验室。你需要一个清晰的问题定义和实验的意愿。
以下是本文的关键要点:
- SLM 是参数少于 100 亿的紧凑模型: 针对特定任务优化,而非通用知识
- 规模不等于能力: 在窄任务上,一个 20 亿参数的 SLM 可以匹配一个 1000 亿参数的 LLM
- 每 token 成本便宜 10-100 倍: 使高流量应用在经济上可行
- 三种技术使其变得实用: 量化缩减内存,LoRA 实现廉价微调,Flash Attention 加速长上下文推理
- 最佳用例是智能体管道、领域任务和边缘部署: 任何你需要大量快速、廉价模型调用的地方
- 未来是混合的: 将常规任务路由到 SLM,将 LLM 保留给复杂的、模糊的推理
原文链接: SLMs vs LLMs: A Complete Comparison
汇智网翻译整理,转载请标明出处
