Agentic AI提效:从小事做起
目标不再是「最强大的模型」,而是「每个任务最有效的模型」。理解这种重新定位是构建实际上可以扩展的代理系统的第一步。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
到2025年,整个行业都被万亿参数模型所吸引。我记得在一个咨询电话中,一家初创公司自豪地告诉我,他们将每一个代理动作都路由到一个前沿的1.5万亿参数模型,而他们的月度推理账单看起来就像一轮A轮融资。现在,我们坚定地处于我所说的效率时代。2026年的代理人工智能效率是一种生存策略,而正确的智能规模调整是严肃团队实现这一目标的方式。
我在微软多年建造分布式系统,后来又共同创立了初创公司,在那里每一美元的计算都很重要。从这个角度来看,我可以告诉你,通用的LLM已经成为自主代理的瓶颈。并不是因为它们缺乏能力,而是因为它们的延迟和成本配置文件与代理系统每分钟必须做出的数千个原子决策根本不相匹配。
目标不再是「最强大的模型」,而是「每个任务最有效的模型」。理解这种重新定位是构建实际上可以扩展的代理系统的第一步。
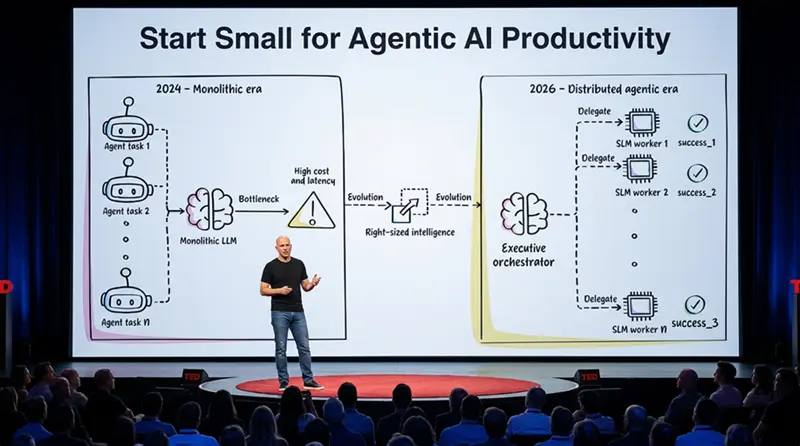
下图展示了从单一推理到分布式、正确规模智能的建筑范式转变。
下图显示了从单一LLM到分布式代理架构的演变:
1、行业证据和市场转变
我始终坚持:先给我看数据,再给我看图表。让我为这个论点提供依据。
关于小语言模型的研究已经量化了SLM与前沿LLM在结构化代理任务上的10-30倍经济优势。这一范围与我在生产系统中观察到的效率-性能权衡一致。
注意: 10-30倍的成本优势并不意味着SLM在各处都取代前沿模型。这意味着它们在结构化、可重复的任务上占主导地位,而这些任务构成了代理工作负载的绝大多数。
微软的Phi-4,于2024年12月发布,证明了使用精心策划的合成数据进行训练可以在领域特定基准上匹配前沿模型的准确性,同时使用更少的参数。我在生产部署中看到一个持续保持的阈值值得明确说明:当响应时间超过200毫秒时,代理成功率急剧下降。任何将每个原子任务路由到云托管的大型模型的架构在统计上都注定要失败。
这些是来自生产部署的模式。它们共同表明,代理运营能力不是通过原始模型能力而是通过智能任务模型匹配来最大化的。让我并排看这些数字。
注意: 以下数字是近似值,因提供商和部署模式而异。前沿LLM列广泛代表GPT-4o等托管模型;SLM列将自托管Phi-4实例作为参考点。
2、云前沿LLM与本地领域特定SLM比较
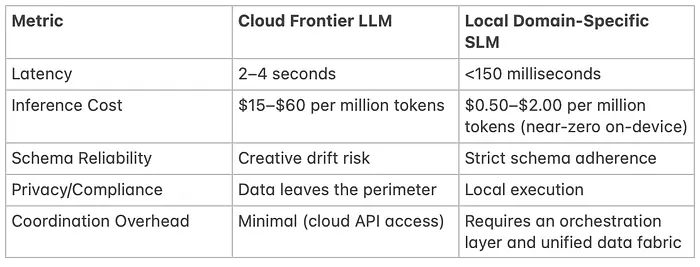
数字说明了一切。现在让我向你展示实现它们的架构。
3、执行官-工作员架构
这个模式让我想起几十年前学习的东西,建造分布式服务:你永远不会让你最昂贵、最复杂的组件处理普通工作。
异构代理网格,行业现在称之为执行官-工作员架构,是2026年的标准模式。它与运营良好的工程组织的运作方式非常吻合。
- 执行官是一个高推理的LLM,处理策略、多步计划、模糊解析和边缘情况。把它想象成决定要构建什么以及如何分解问题的Staff工程师。
- 工作员是领域特定的SLM,每个都针对原子任务进行微调:JSON解析、API编排、SQL生成和文档摘要。它们是可靠、快速和可预测的专家。
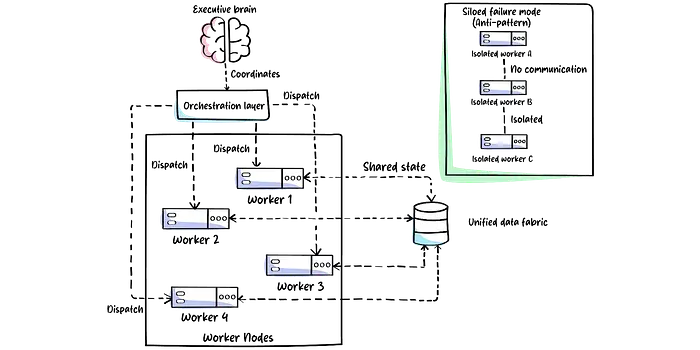
我曾看到摧毁真实部署的细微差别:如果没有集中编排层和统一的数据结构,这些工作员就会成为针对局部目标优化而破坏全局企业目标的孤立代理。
我亲眼目睹了一个案例,一个库存优化代理和一个采购代理,各自都很优秀,却将运营成本推高了18%,因为它们没有通过公共数据层共享状态。每个代理都做出了局部合理的决策,但全局来看却是混乱的。
注意: 执行官不是可选的装饰。它是你必须支付的协调开销,以防止系统性混乱。最快的捷径是跳过它,让一堆机器人做相反的目的工作。
这种协调开销是真实的:编排层在关键路径上增加延迟,需要在共享状态管理、冲突解决逻辑和监控基础设施方面进行工程投资。另一个选择,不协调的局部优化,categorically更糟,正如那18%的成本飙升所说明的。允许执行官监控、重定向和协调工作员输出的元工具是将正常运行的代理网格与混乱区分开的东西。编排层是架构的免疫系统。
下图编码了协调和非协调代理系统之间的区别。
4、代理效率路线图
架构图只有在工程师知道实施的前三个步骤时才重要。让我从理论转向可操作的路线图。
步骤1:任务原子化
你审计你的代理工作流,将每个复杂链分解为微小、可预测的「系统1」任务。我用教学中的比喻:正如你永远不会写一个2000行的函数,你也不应该要求单个模型调用同时处理计划、数据检索和响应格式化。
每个原子任务获得一份合约:输入模式、输出模式和延迟预算。这是受约束的API设计与人工智能工程相遇的地方。
实用提示: 首先用每步延迟和代币计数日志对你的现有代理链进行工具化。分解点会在数据中显现出来。寻找延迟飙升或代币使用与任务复杂性不成比例的步骤。
步骤2:模型蒸馏
这是执行官 earns its keep,即使在开发期间。你使用高推理LLM为每个原子任务生成合成训练数据,成千上万的输入-输出对,然后将这些知识提炼成1B-8B参数的工作员SLM。
Phi-4的合成数据策划方法证明,仔细的数据选择可以在狭窄任务上以前沿模型更少的参数匹配前沿性能。蒸馏成本是一次性投资;节省在每次推理后复合。为了使经济效益具体化:如果蒸馏成本5000美元,而与前沿模型相比每次推理节省约0.014美元,你在大约357,000次调用时达到盈亏平衡点,这是大多数生产代理系统几周内跨越的阈值。
步骤3:边缘部署
一旦你的工作员小而专业,你可以将它们部署在设备上或本地公司集群上,完全绕过云往返开销。这是延迟降至150ms以下的地方,每次推理成本接近零,你通过将数据保持在企业边界内来满足2026年的隐私和合规标准。
每个步骤哺育下一个:原子化定义要蒸馏什么,蒸馏产生要部署什么。结果是一个代理系统,协调开销由执行官管理,而原始吞吐量由廉价、快速本地工作员处理。
以下伪代码使这个编排循环更加具体。
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional
from enum import Enum
class TaskType(Enum):
SUMMARIZE = "summarize"
EXTRACT = "extract"
CLASSIFY = "classify"
GENERATE = "generate"
@dataclass
class AtomicTask:
task_id: str
task_type: TaskType
input_schema: Dict[str, Any]
assigned_worker_model: str
dependencies: List[str] = field(default_factory=list)
@dataclass
class TaskResult:
task_id: str
output: Any
status: str # "success" | "error"
confidence: float = 1.0
# --- Task Atomizer: 将复杂请求分解为独立原子单元 ---
def task_atomizer(request: str, available_workers: Dict[str, str]) -> List[AtomicTask]:
# 执行官LLM分析请求并产生分解计划
# 每个原子任务针对一个能力和一个工作员模型
tasks = [
AtomicTask(
task_id="t1",
task_type=TaskType.EXTRACT,
input_schema={"text": request, "fields": ["entities", "dates"]},
assigned_worker_model=available_workers.get("extraction", "slm-extract-3b"),
),
AtomicTask(
task_id="t2",
task_type=TaskType.CLASSIFY,
input_schema={"text": request, "labels": ["urgent", "routine", "informational"]},
assigned_worker_model=available_workers.get("classification", "slm-classify-1b"),
),
AtomicTask(
task_id="t3",
task_type=TaskType.SUMMARIZE,
input_schema={"text": request, "max_tokens": 150},
assigned_worker_model=available_workers.get("summarization", "slm-summarize-3b"),
dependencies=["t1"], # 需要提取结果进行上下文感知摘要
),
]
return tasks
# --- Dispatch: 将单个原子任务发送到分配的本地SLM工作员 ---
def dispatch_to_worker(task: AtomicTask, data_fabric: Dict[str, Any]) -> TaskResult:
# 将依赖输出注入任务输入,使工作员有完整上下文
# 协调开销:每个调度的序列化+提示构建
enriched_input = {**task.input_schema}
for dep_id in task.dependencies:
if dep_id in data_fabric:
enriched_input[f"dep_{dep_id}"] = data_fabric[dep_id]
# 占位符:对本地SLM推理端点的实际调用
response = {"result": f"mock_output_for_{task.task_id}", "confidence": 0.92}
return TaskResult(
task_id=task.task_id,
output=response["result"],
status="success",
confidence=response.get("confidence", 1.0),
)
# --- Reconciler: 检测工作员输出之间的冲突并产生最终答案 ---
def reconcile_and_plan(data_fabric: Dict[str, Any], results: List[TaskResult]) -> Dict[str, Any]:
conflicts = []
# 检查依赖任务之间矛盾的输出
# 协调开销:跨验证需要共同读取所有结果
for i, r1 in enumerate(results):
for r2 in results[i + 1:]:
if r1.status == "success" and r2.status == "success":
# 占位符冲突检测逻辑
if r1.confidence < 0.5 and r2.confidence < 0.5:
conflicts.append((r1.task_id, r2.task_id))
if conflicts:
# 重新调度冲突任务或升级到执行官进行仲裁
return {"status": "conflict", "conflicts": conflicts, "data_fabric": data_fabric}
# 将所有输出合并为连贯的最终响应
# 数据结构防止孤立优化:每个工作员的输出在这里都可见
final_response = {
"extraction": data_fabric.get("t1"),
"classification": data_fabric.get("t2"),
"summary": data_fabric.get("t3"),
"coherent_answer": f"Based on {len(results)} sub-tasks, synthesized response.",
}
return {"status": "success", "response": final_response}
# --- 执行官编排循环 ---
def executive_orchestrate(request: str) -> Dict[str, Any]:
available_workers = {
"extraction": "slm-extract-3b",
"classification": "slm-classify-1b",
"summarization": "slm-summarize-3b",
}
# 步骤1:将复杂请求分解为原子任务
tasks = task_atomizer(request, available_workers)
# 共享数据结构:防止工作员孤立优化的中央存储
# 每个结果都写在这里,以便下游任务和协调看到所有上下文
data_fabric: Dict[str, Any] = {}
all_results: List[TaskResult] = []
# 步骤2:拓扑调度——尊重依赖排序
completed = set()
pending = list(tasks)
while pending:
# 找到所有依赖都已满足的任务
ready = [t for t in pending if all(d in completed for d in t.dependencies)]
if not ready:
raise RuntimeError("Circular dependency detected among tasks")
# 协调开销:存在依赖时的顺序波
for task in ready:
result = dispatch_to_worker(task, data_fabric)
# 立即将结果写入共享数据结构
data_fabric[task.task_id] = result.output
all_results.append(result)
completed.add(task.task_id)
pending.remove(task)
# 步骤3:协调所有工作员输出并产生最终协调响应
final = reconcile_and_plan(data_fabric, all_results)
return final
# --- 入口点 ---
if __name__ == "__main__":
user_request = "Analyze the attached contract for key dates, classify urgency, and summarize."
output = executive_orchestrate(user_request)
print(output)
4、代理成功的关键绩效指标
让我留下一个重新定位,我相信这将定义我们如何评估未来十年的人工智能系统。旧的关键绩效指标——基准准确性、参数数量和每秒token——是万亿参数时代的遗迹。
2026年,真正重要的指标本质上是不同的:
- 每焦耳token: 衡量能源效率,直接关联边缘部署能力和可持续性。
- 每次成功结果成本: 捕获真正对业务重要的东西,不是你生成代币有多便宜,而是你以多低的成本完成端到端代理任务并验证正确性。
- 代理运营容量: 您的系统可以在不降级的情况下在单位时间内维持的协调自主行动数量。这将玩具演示与生产级部署区分开来。
实用提示: 本季度开始跟踪每次成功结果成本。对您的代理管道进行端到端工具化,包括重试和后备。您会对隐藏在高或部分完成的代理链中的成本感到震惊。
在我构建或审查的每个系统中,故障模式从来不是模型能力不足。而是协调不足。我开场提到的那家初创公司最终围绕执行官-工作员网格重建。它们的推理账单下降了一个数量级以上。2026年的代理人工智能效率不是部署你能负担得起的最大模型。而是为每个任务部署正确的模型,由足够聪明的架构协调将其整合在一起。
原文链接:Think small to scale big for agentic AI efficiency in 2026
汇智网翻译整理,转载请标明出处
