RAG 陷阱:向量搜索不是语义理解
盲目依赖余弦相似度如何破坏你的检索准确性并产生幻觉。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
如果你今天正在构建 AI 应用程序,你可能正在使用 RAG(检索增强生成)。
这个架构诱人地简单:
- 对文档进行分块。
- 将它们嵌入为向量。
- 根据用户查询搜索最近的向量。
- 将这些块输入 LLM。
感觉像魔法一样。你输入一个查询,系统"语义地"找到答案。
但行业中有一个肮脏的秘密:朴素 RAG 仅比关键词搜索稍微好一点。
我们像向量数据库"理解"含义一样对待它们。它们不。它们只理解几何接近性。当你依赖原始余弦相似度来驱动应用程序时,你不是在构建智能系统;你是在构建一个会说英语的随机数生成器。
1、核心知识:压缩损失
要理解为什么 RAG 失败,我们必须看看嵌入模型实际上做了什么。
它获取一系列标记(词)并将它们压缩为固定维度的向量(例如,d=768)。
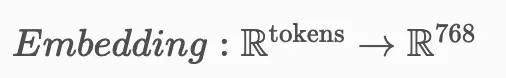
这是一种有损压缩。当我们将一个长而细致的段落压缩为 768 个浮点数时,我们丢失信息。我们丢失"语法"、"否定",并且经常丢失特定的"实体关系"。
然后我们使用余弦相似度比较这些压缩向量:
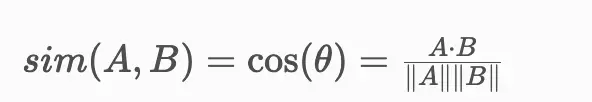
问题:高相似度并不意味着"正确答案"。它意味着"相似向量空间"。
- 查询:"如何最小化损失函数?"
- 检索块:"损失函数代表错误……最大化它导致过拟合。"
这两个句子的向量极其接近,因为它们包含 90% 的相同关键词(损失、函数、最大化/最小化)。向量数据库看到几何,但错过了逻辑否定。然后 LLM 读取错误的块并自信地产生错误的建议幻觉。
2、流程:"分块"灾难
第二个失败点是最常见的实现错误:盲目分块。
开发人员经常按字符数分割 PDF(例如,每 500 个字符)。
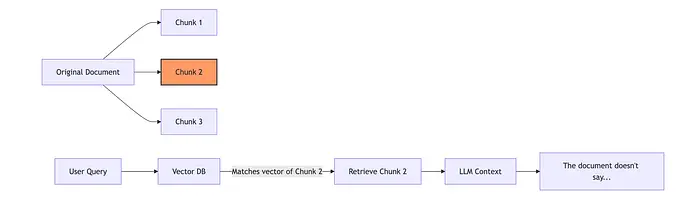
场景:想象一个跨越块 1 和块 2 边界的句子:
"产品的保修在用户……(块 1 结束)……试图打开外壳时无效。"(块 2 开始)
如果用户问 "打开外壳是否使保修无效?","保修"的向量可能存在于块 1 中,而"打开外壳"的上下文存在于块 2 中。
- 向量数据库检索块 1。
- LLM 读取块 1,没有提到打开外壳,并回答:"不,保修仍然有效。"
你不是检索失败;你是边界失败。
3、朴素 RAG 与重新排序
"朴素"方法仅依赖于向量索引。"生产"方法使用向量数据库作为过滤器(候选生成)和用于排序的交叉编码器(精度)。
3.1 朴素方法(快但愚蠢)
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
# 加载索引
vectorstore = FAISS.load_local("my_index", OpenAIEmbeddings())
# 纯粹基于余弦相似度检索前 4 个匹配
results = vectorstore.similarity_search("How to reset device?", k=4)
context = "\n".join([doc.page_content for doc in results])
# 此上下文可能包含片段或不相关的相似文本
prompt = f"Context: {context}\nQuestion: How to reset device?"
3.2 生产方法(重新排序)
我们检索大量候选者(例如,50 个)以确保我们不会错过边界,然后使用更昂贵但准确的模型(交叉编码器)对它们进行排序。
from sentence_transformers import CrossEncoder
from langchain.vectorstores import FAISS
# 1. 高召回率获取(获得大量潜在匹配)
vectorstore = FAISS.load_local("my_index", OpenAIEmbeddings())
candidates = vectorstore.similarity_search("How to reset device?", k=50)
# 2. 精度重新排序(显式评分关系)
# CrossEncoders 接受(查询,文档)对并输出相关性分数(0-1)
reranker = CrossEncoder('ms-marco-MiniLM-L-6-v2')
# 准备对
pairs = [["How to reset device?", doc.page_content] for doc in candidates]
# 对它们评分
scores = reranker.predict(pairs)
# 3. 根据重新排序器分数选择前 N 个
top_n_indices = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)[:5]
final_context = [candidates[i].page_content for i in top_n_indices]
# 现在我们向 LLM 提供*真正*相关的块
prompt = f"Context: {final_context}\nQuestion: How to reset device?"
为什么这有效:双向编码器(向量数据库)很快但愚蠢。交叉编码器一起读取查询和块,使其能够看到查询中的*"reset"与文档中的"reboot"*匹配,即使它们的向量稍微相距较远。
4、"迷失在中间"现象
即使你检索了正确的块,你仍然可能因在提示中排列它们的方式而失败。
LLM 擅长使用上下文窗口开头和结尾的信息,但它们难以检索埋在中间的信息。
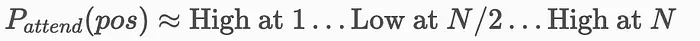
如果你只是将检索的块连接为块 1 + 块 2 + 块 3,而答案实际上在块 2 中,LLM 可能会错过它。
4.1 解决方案:倒排融合(RRF)或重新排序
不要只是首先转储最高分块,有时你需要根据逻辑流重新排序或简单地突出最重要的块。
# 一个简单的技巧:将最高分块放在最后
# 或在最开始,永远不要埋在中间。
best_chunk = final_context[0]
other_chunks = final_context[1:]
# 策略:"固定到最后"
structured_prompt = f"""
以下是一些背景信息:
{chr(10).join(other_chunks)}
关键指令:答案最可能在以下文本中:
{best_chunk}
Question: How to reset device?
"""
5、结束语:RAG 比你想象的更难
向量数据库不是语义搜索引擎。它们是模糊匹配工具。
如果你想构建一个在生产中实际有效的 RAG 系统:
- 不要仅依赖余弦相似度。始终添加重新排序层(交叉编码器)。
- 尊重块边界。使用"父文档检索"(检索小块,但向 LLM 提供父文档)以避免将句子切成两半。
- 管理"中间"。高度意识到你在上下文窗口中放置信息的位置。
停止将文本投入 Pinecone 索引并希望获得最好的结果。RAG 不是魔法棒;它是一个需要仔细优化的数据管道问题。
关键要点:
- 余弦相似度捕获关键词密度,而不是逻辑或否定。
- 分块策略经常切断实体之间的语义链接(例如,因果关系)。
- 重新排序至关重要:使用向量数据库进行过滤(速度)和交叉编码器进行排序(精度)。
- 上下文定位:LLM 忽略上下文窗口的中间;相应地构建你的提示。
原文链接: The RAG Trap: Why Vector Search Is Not Semantic Understanding
汇智网翻译整理,转载请标明出处
