3个主流大模型微调框架对比
我今年在所有三个框架上都运行过QLoRA任务。每个解决了不同的问题。没有一个解决了所有问题。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
你打开GitHub想选一个微调框架,结果发现三个工具各有数万颗星、三个Reddit帖子说了三种不同的看法、十二篇Medium文章互相矛盾。一个帖子发誓Unsloth是唯一理智的选择。另一个说LLaMA-Factory的Web UI是最快路径。第三个坚持Axolotl是唯一能在规模上工作的。三个小时后你关掉了所有标签页,倒了第二杯咖啡,却比开始时知道的更少了。
你的团队已经决定微调是正确的选择:基础模型在你的领域数据上产生幻觉,提示工程在72%的准确率上碰了壁,而RAG对你的分类任务来说大材小用了。我们几周前已经讨论过[什么时候微调有意义]。
我今年在所有三个框架上都运行过QLoRA任务。每个解决了不同的问题。没有一个解决了所有问题。
1、我们在比较什么?
微调框架位于你和原始PyTorch训练循环之间。它们处理管道工作:加载模型权重、应用参数高效方法如LoRA、管理GPU内存、格式化数据集、导出结果。替代方案是你自己用原始HuggingFace Transformers、PEFT和TRL来连接:每次实验200多行样板代码,没有内置数据集格式化,没有显存优化,每个超参数都要手动设置。
范围界定: 我们在比较本地/自托管训练的前3个开源微调框架。我们不涉及托管微调API(OpenAI、Together AI、Anyscale)、托管平台(AWS SageMaker、Vertex AI)或这些框架构建于其上的底层HuggingFace库(PEFT、TRL)。如果你使用API提供商的微调端点,这个比较不适合你。

⚠️ 混淆警报: "微调框架"与"微调方法"。LoRA、QLoRA和全量微调是方法(你如何更新权重)。Unsloth、Axolotl和LLaMA-Factory是框架(实现这些方法的工具)。这里的每个框架都支持多种方法。框架选择关乎工作流、速度和规模。方法选择关乎显存和质量的权衡。
评估框架: 在选择微调框架时,决策归结为4个因素:
- 训练速度(每秒token数,挂钟时间完成)
- 显存效率(你能否在你拥有的GPU上训练你需要的模型?)
- 灵活性(模型覆盖、训练方法、多GPU、多模态)
- 易用性(从零到首次训练运行的时间)
GitHub星数、Reddit情绪和"谁在使用"的营销页面不在本列表中。下面的每个工具都根据这四个维度进行评估。
2、正面对比
工具按简单到复杂排序。
2.1 LLaMA-Factory
一句话总结: 让微调感觉像填表的框架,拥有生态系统中最广泛的模型覆盖。
- 速度 ●●●○(使用Unsloth后端时快)
- 显存 ●●●○
- 灵活性 ●●●●(最多模型)
- 易用性 ●●●●
👍 优点:
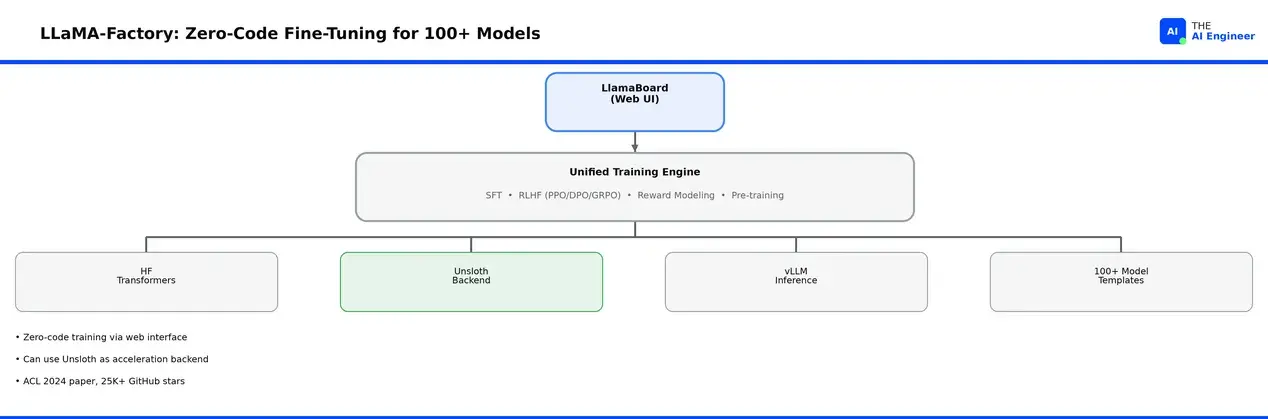
- 类别中最低的入门门槛。 内置Web UI LlamaBoard让你选择模型、上传数据集、选择训练方法,然后点击"开始"。无需YAML、无需Python、无需配置文件。该框架通过同一界面支持SFT、DPO、PPO、GRPO、奖励建模和预训练,有ACL 2024论文背书。
- 开箱即用100+模型模板。 Llama 4、Qwen 3、DeepSeek、Gemma、GPT-OSS、Phi-4、Mistral、GLM:如果一个模型存在于HuggingFace上,LLaMA-Factory很可能有它的模板。每个模板处理分词器特性、聊天格式化和特殊token——这些东西否则需要你花一个下午来调试。
- Unsloth作为可选后端。 LLaMA-Factory可以使用Unsloth的优化内核作为训练后端。在基准测试中,这将LLaMA-Factory的训练时间带到原生Unsloth的6%以内(在A100 40GB上对Llama-3.1 8B QLoRA为3.4小时vs 3.2小时),同时保留LLaMA-Factory的所有UI和模型管理功能。
👎 缺点:
- 抽象隐藏了调试。 当训练出错时,LLaMA-Factory的错误消息指向内部框架代码,而不是你的配置错误。Web UI不暴露梯度累积步数或预热比率等高级超参数,所以你最终还是得编辑配置文件。
- 多GPU支持存在但滞后。 通过CLI配置支持FSDP和DeepSpeed,但Web UI无法配置分布式训练。一旦你需要跨4+GPU的序列并行或张量并行,你就要编写绕过LlamaBoard的CLI命令。
快速上手(3条命令到首次训练):
pip install llamafactory
llamafactory-cli webui # 在localhost:7860启动LlamaBoard
# 选择模型 → 上传数据集 → 点击"开始" → 完成。
🎯 最适合: 个人实践者、小团队,或任何重视模型支持广度和首次训练运行速度胜过精细控制的人。
⚠️ 天花板: 当你需要自定义训练循环、高级分布式训练策略(序列并行、张量并行),或调试抽象所花的时间超过它们节省的时间时,迁移到其他框架。
📡 实践者信号: LLaMA-Factory论文被ACL 2024接收,该仓库已被用于训练NovaSky的Sky-T1推理模型等模型。
2.2 Unsloth
一句话总结: 从头重写GPU内核使单GPU微调极其快速和节省内存的速度恶魔。
- 速度 ●●●●(最快)
- 显存 ●●●●(最低)
- 灵活性 ●●●○(专注单GPU)
- 易用性 ●●●○

👍 优点:
- 2倍更快的训练,70%更少的显存。 Unsloth为注意力机制、MLP层和RoPE嵌入编写自定义Triton内核,完全绕过标准HuggingFace Transformers路径。在Llama-3.1 8B QLoRA基准测试上(rank 32,A100 40GB),Unsloth在3.2小时内完成。Axolotl在相同硬件上花费5.8小时。
- 消费级GPU变得可行。 融合内核节省的显存意味着7B模型可以在单个RTX 4090(24GB)上以QLoRA运行,70B模型可以在单个A100 80GB上运行。在Unsloth之前,两者都需要多GPU设置或160GB+聚合内存的云实例。
- 消费级硬件上的GRPO推理训练。 GRPO通过比较多个输出来训练模型生成思维链推理,而不是使用PPO的独立评论家网络来评分每一个。没有评论家意味着大约一半的显存。Unsloth支持1B到70B参数模型的GRPO。
- MoE微调。 混合专家模型将每个输入路由到专家层的子集而不是激活每个参数。这使得推理更便宜但更难训练。
👎 缺点:
多GPU需要付费。 Unsloth的速度来自按操作编写的自定义Triton内核。这些内核针对单GPU执行路径。将它们分发到多个GPU意味着重写内存管理和通信层,这就是为什么多GPU存在于付费的Unsloth Pro层级和Unsloth Studio中,而不是开源仓库。如果你需要跨8个GPU的FSDP,你该看Axolotl。
新架构会延迟到达。 每个模型系列有不同的注意力模式、激活函数和张量布局。Unsloth的内核是按架构手工优化的,所以新模型系列意味着新的内核工作。主流模型(Llama、Qwen、Mistral)快速到达。具有不寻常路由或注意力模式的小众架构可能比LLaMA-Factory落后数周,后者封装标准HuggingFace Transformers并自动继承模型支持。
快速上手(5行代码到训练好的模型):
from unsloth import FastModel
model, tokenizer = FastModel.from_pretrained(
"unsloth/Llama-3.1-8B-Instruct",
max_seq_length=2048, load_in_4bit=True
)
# 添加LoRA适配器,加载数据集,训练。完整notebook:unsloth.ai/docs
🎯 最适合: 个人研究者、GPU预算有限的创业公司,任何需要在一两个GPU上快速训练而不租集群的人。
⚠️ 天花板: 当你需要多节点分布式训练、带奖励模型的复杂RLHF流水线,或团队需要跨不同集群配置的可重复训练时,迁移到其他框架(或用Axolotl补充)。
📡 实践者信号: NVIDIA将Unsloth作为RTX AI PC和DGX Spark的首选框架,Red Hat将其作为企业Training Hub产品的后端。
2.3 Axolotl
一句话总结: YAML配置的强力工具,为需要完整ML训练流水线的团队构建:多GPU分发、RLHF、多模态和序列并行。
- 速度 ●●○○(单GPU较慢)
- 显存 ●●○○
- 灵活性 ●●●●(最完整)
- 易用性 ●●○○
👍 优点:
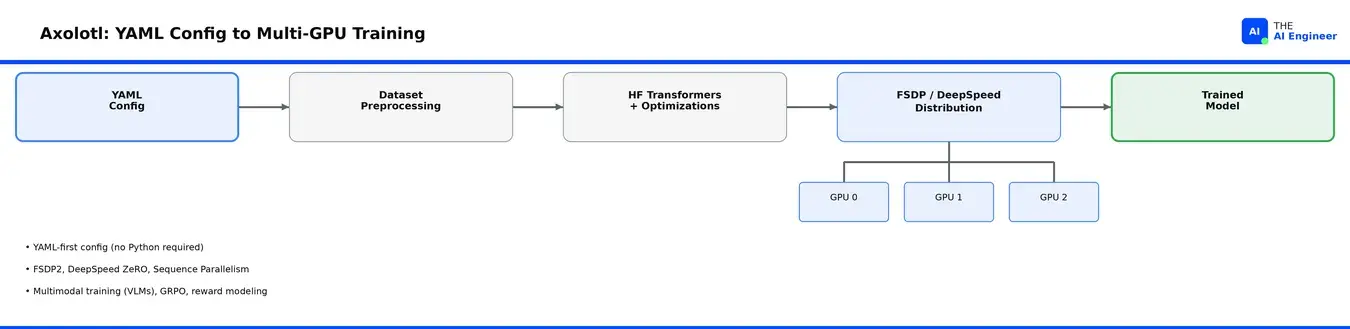
- 最完整的多GPU方案。 当模型放不进一个GPU时,你需要一个跨多个GPU分割它的策略。FSDP2将模型参数分片到GPU上,每个持有一部分权重。DeepSpeed ZeRO做同样的事但还分片优化器状态和梯度,释放更多内存。序列并行将长输入序列分割到GPU上,这就是Axolotl处理超过32K token上下文长度的方式。Axolotl支持所有三种,加上在节点内和跨节点组合它们的ND并行。
- 一个工具中的完整RLHF流水线。 大多数微调项目从SFT开始(在示例上监督微调),然后添加DPO或PPO来使用排序的输出对将模型与人类偏好对齐。在一个框架中运行SFT而在另一个中运行DPO意味着转换检查点、重新格式化数据集、调试两个配置系统。Axolotl以相同的YAML配置格式运行SFT、DPO、PPO、GRPO、奖励建模和过程奖励建模,因此两阶段的SFT-然后-DPO工作流共享单一数据管道和检查点格式。
- 成熟的多模态支持。 视觉语言模型同时处理图像和文本,这意味着微调框架需要处理两种不同的分词路径、将图像块与文本token对齐、管理图像编码器的额外显存。Axolotl支持LLaMA-Vision、Qwen2-VL、Pixtral、LLaVA、Gemma 3n、InternVL 3.5和音频模型Voxtral。
- 样本打包提升吞吐量。 Axolotl将多个短训练样本打包到单个序列中,减少浪费的填充token并增加有效吞吐量。在具有变长示例的数据集上(在指令微调中很常见),这可以将训练时间减少20-30%。
👎 缺点:
- 单GPU上较慢。 Axolotl用额外的抽象层包装HuggingFace Transformers用于配置解析、数据集预处理和分布式训练设置。这些层即使你在单个GPU上也会运行,增加了Unsloth直接到内核方法完全跳过的开销。在相同的Llama-3.1 8B QLoRA基准测试(A100 40GB)上,Axolotl花了5.8小时vs Unsloth的3.2小时。在多GPU集群上,开销被分摊到各GPU上,几乎不影响。
- 配置复杂性。 一个完整的Axolotl RLHF配置可能有100多行YAML。失败模式是静默的错误配置:一个拼写错误的字段名不会报错,而是被忽略,你在不知不觉中用默认超参数训练。调试需要将你的配置与框架源代码中的默认值进行diff。
- 任务内部日志中断。 Axolotl将训练包装在捕获stdout的Task对象中。这些对象内部的标准print和logging调用并不总是输出到你的终端,所以你无法看到训练进度或调试中间输出。
快速上手(YAML配置到训练运行):
# lora-8b.yml
base_model: meta-llama/Llama-3.1-8B-Instruct
adapter: lora
lora_r: 32
lora_alpha: 16
datasets:
- path: your_data.jsonl
type: sharegpt
micro_batch_size: 2
num_epochs: 3
optimizer: adamw_bnb_8bit
axolotl train lora-8b.yml
🎯 最适合: 拥有多GPU集群的团队,需要RLHF/DPO对齐流水线的项目,多模态微调,或使用超长上下文窗口的训练。
⚠️ 天花板: 你可能不会超出Axolotl的范畴。你会超出YAML配置方法,直接在PyTorch中编写自定义训练脚本。那就是Torchtune变得有趣的时候。
📡 实践者信号: 无服务器GPU平台Modal维护官方Axolotl集成,并推荐为初学者的默认选择:"如果你是初学者:使用Axolotl。如果你的GPU资源有限:使用Unsloth。"
3、决策流程图
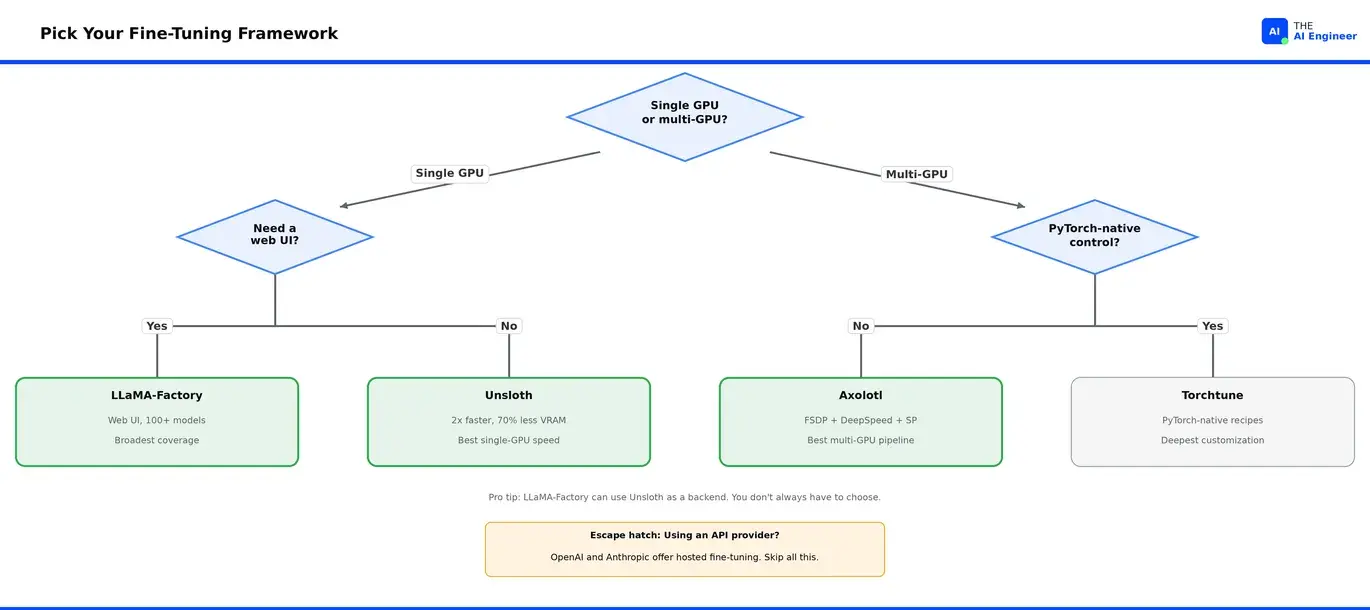
流程图捕捉了两个关键决策点:
决策1:单GPU还是多GPU? 这立刻消除了一半选项。如果你在单GPU上(大多数刚开始的人),你在Unsloth的速度和LLaMA-Factory的广度之间选择。如果你运行集群,Axolotl和Torchtune是你的竞争者。
决策2:你需要Web UI吗?/你需要PyTorch原生控制吗? 在每个分支内,这按理念区分工具。LLaMA-Factory的UI是为了快速首次运行。Unsloth的notebook优先方法是为了快速到训练好的模型。Axolotl的YAML是为了团队可重复性。Torchtune的recipe是为了想要修改循环的研究者。
底部的逃生舱很重要:如果你使用OpenAI或Anthropic的API且不需要自托管,它们的托管微调端点完全跳过了所有这些。没有GPU管理,没有框架选择,没有显存计算。权衡是规模化的成本和对训练过程的较少控制。
4、比较表
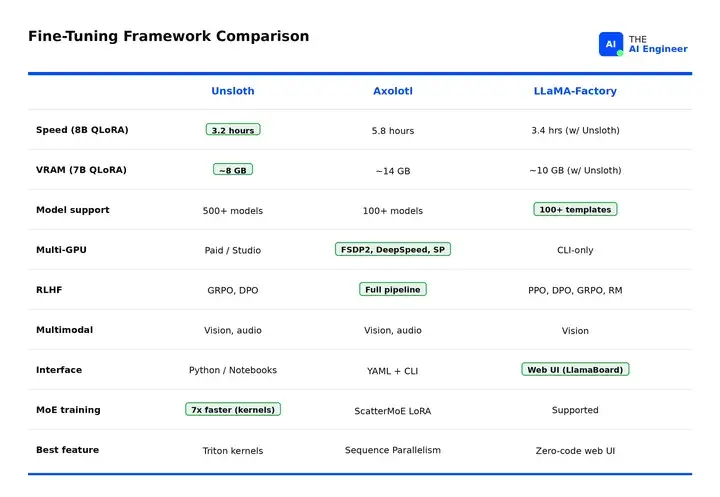
以下所有基准测试均使用Llama-3.1 8B QLoRA(rank 32)在A100 40GB上(除非另有说明)。
5、诚实的看法
你不必只选一个。 使用Unsloth后端的LLaMA-Factory给你最广泛的模型覆盖和Web UI,加上Unsloth的内核级速度。训练时间惩罚仅比原生Unsloth慢~6%。对于多阶段项目,Unsloth处理SFT(计算密集,最受益于内核速度),然后Axolotl处理DPO/RLHF对齐(需要参考模型与训练模型并行,显存翻倍,这正是多GPU分发发挥优势的地方)。
这个类别已经自我赶上了。 2024年,Unsloth不支持GRPO,Axolotl没有序列并行,LLaMA-Factory不能用Unsloth作为后端。那些差距迫使你选择框架。到2026年,三个都支持LoRA、QLoRA、全量微调、GRPO、DPO和视觉模型。不同的是工作流:你如何配置、调试和分发训练。
数据质量主导框架选择。 Databricks在内部代码上微调了Llama 3.1 8B并进行了实时A/B测试:在错误修复上的接受率比GPT-4o高1.4倍,推理延迟低2倍。训练数据是开发者使用现有代码助手时自然生成的交互日志。高质量、特定任务的数据产生了这些数字。框架是Mosaic AI,一个托管服务。这里三个工具在相同数据上都会产生类似结果。
任务定义也很重要。 Stripe微调了一个LLM来生成代码修复。延迟很高,准确率很低。他们将问题重新定义为分类:模型不是生成修复,而是从一组已知修复模式中选择。延迟下降,准确率上升。瓶颈是任务框架,而不是模型或框架。
6、荣誉提名:Torchtune
Torchtune是Meta的PyTorch原生微调库。它是想要对训练循环拥有最大控制权并深度投资PyTorch生态系统的团队的正确选择。
为什么获得提名: PyTorch 2.5编译支持提供大约20-24%的速度提升(在相同8B基准测试上为4.7小时,介于Unsloth的3.2和Axolotl的5.8之间)。使用PyTorch原生分布式启动器的FSDP2多节点训练开箱即用。DoRA(方向优化秩适应)在Llama-3.1 8B上比QLoRA节省8%显存且困惑度不退化。每个训练组件(优化器、损失函数、调度器、数据加载器)都是独立的可组合模块,你可以在不触碰其余管道的情况下替换。
为什么不在主要比较中: 模型覆盖较窄,专注于Meta模型和少数其他模型。每个配置都是Python "recipe"文件而非YAML,所以你需要阅读和修改Python代码来更改训练行为。对于大多数AI工程师,Axolotl以更少的代码提供类似的多GPU能力。
使用Torchtune如果你: 是想要修改训练循环本身的PyTorch开发者,而不仅仅是配置它。你在构建研究原型,需要在代码层面替换优化器、损失函数或调度器。你专门微调Meta模型并想要最紧密的集成。
7、要记住的一件事
你今天选择的框架不会是你两年后使用的框架。Unsloth、Axolotl和LLaMA-Factory都导出标准HuggingFace检查点。你训练好的模型是可移植的。你的数据管道是可移植的。框架是你微调技术栈中最不永久的决策。
选择让你最快到达第一个训练好模型的那个。然后迭代。
🏗️ 工程教训 微调的真正成本不是计算。而是迭代时间。一个训练快2倍的框架不是在一次运行中节省你3小时。它是在20种配置的网格搜索中每次实验都节省3小时。那就是60小时。为实验速度选择,而不是为一次运行的速度选择。
Unsloth为速度,Axolotl为规模,LLaMA-Factory为广度。将工具与你的基础设施匹配。
原文链接: Unsloth vs Axolotl vs LLaMA-Factory
汇智网翻译整理,转载请标明出处
