用专有数据训练小型语言模型
我们如何微调一个4B参数模型达到95%准确率。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我们在Neurometric进行的研究主要关注如何为特定任务自动生成SLM。在评估了各种模型的测试时计算策略并发布了我们的排行榜后,我们将目光投向了SLM。AI界存在一个日益增长的假设:越大越好。更多参数、更多算力、更多一切。但如果一个参数少于60亿的模型,在真实企业任务上能够与比它大10倍或20倍的模型一较高下呢?
1、实验设置:以CRMArena为试验场
CRMArena是一个围绕真实Salesforce CRM任务构建的基准测试。涵盖线索资格认定、活动优先级排序——这些是销售运营团队每天都要处理的工作。它使用模拟的Salesforce B2B数据库,模型根据它们能够多准确地完成多步骤Agent工作流并得出正确答案来进行评估。
我们想知道:我们能否微调一个小型语言模型(SLM),使其在这些任务上具有竞争力?不是作为一个玩具实验,而是作为一个在边缘运行强大AI的真实证据——在那些大规模云端模型并不总是实用的场景中。
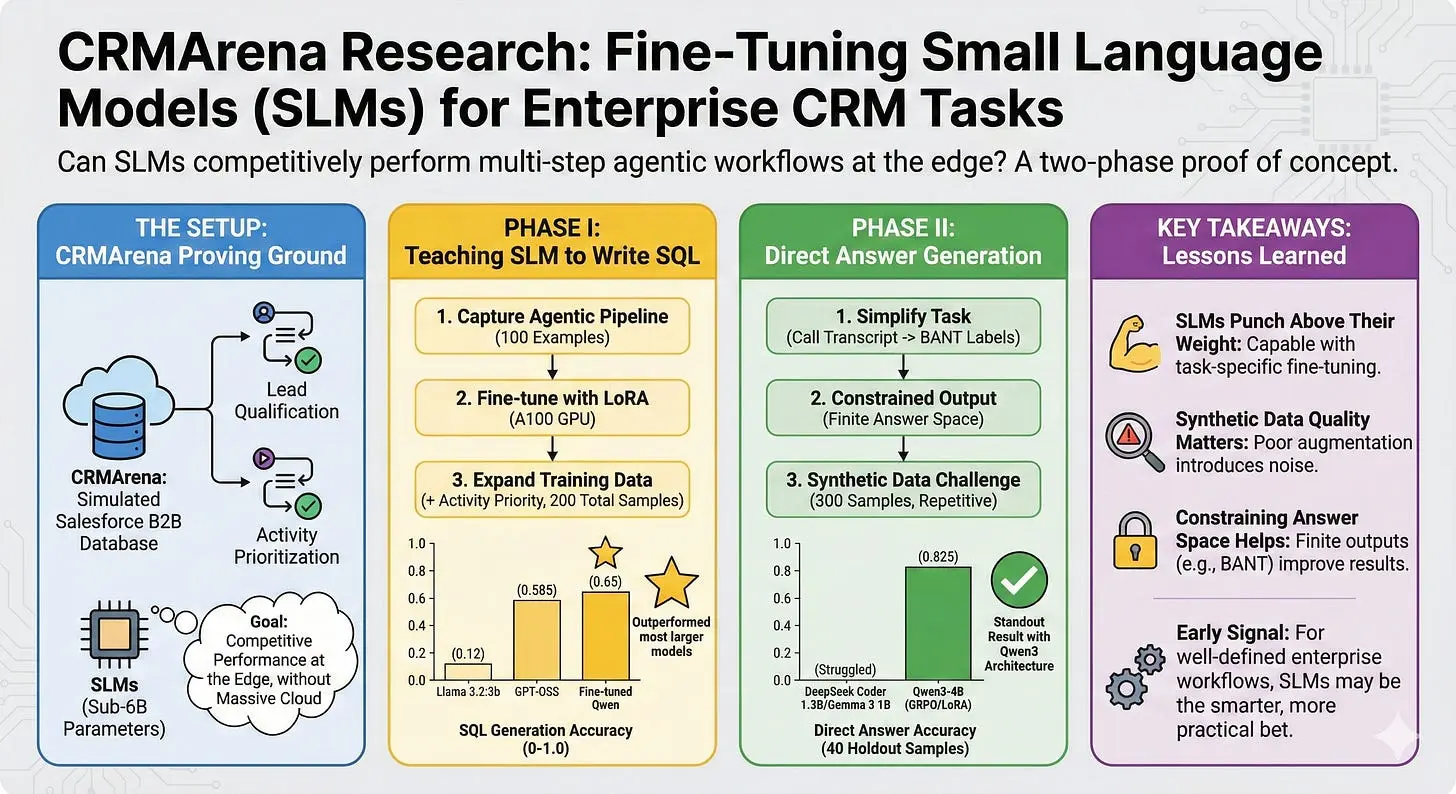
2、教小模型写SQL
我们的首次尝试聚焦于拼图中的一块——生成从Salesforce提取正确数据的SQL查询。我们模拟了CRMArena数据库中所有100个示例的完整Agent流程,捕获了通往有效SQL输出的对话流。然后,我们使用这些数据,在一个A100 GPU上使用LoRA适配器对几个参数小于60亿的模型进行了微调。
早期的结果很粗糙。这些模型难以捕捉Agent工作流背后的推理过程。它们没有学习要生成什么,而是试图复制整个消息交换——产生了不连贯、偏离目标的输出。
但当我们扩展训练数据后,情况有所改善。将第二个任务(活动优先级)的SQL示例与线索资格认定一起添加——即使总共只有200个训练样本——也导致了有效查询生成的显著提升。
有趣的地方来了。当我们把我们最好的微调Qwen模型放回完整的线索资格认定Agent流水线中时,它得分0.65。作为对比,在同一测试集上,未微调模型的得分范围从0.12(Llama 3.2:3b)到0.585(GPT-OSS)。我们微调后的SLM超过了除两个较大通用模型之外的所有模型——并且比它自己的基础Qwen变体高了20个点。
3、直接得出答案
受到第一阶段的鼓舞,我们转变了策略。如果不生成SQL,而是让模型直接跳到最终答案呢?
对于线索资格认定,答案空间是有限的:预算、权限、需求和时间线(BANT框架)的任意组合,或"无"。这种受约束的输出使其成为直接答案生成的强有力候选。
我们去掉了冗长的数据库Schema指令,用简洁的任务描述取而代之。模型的任务很简单:读取通话记录数据,返回正确的BANT标签。
我们还解决了数据稀缺问题。只有100个原始示例,我们使用GPT生成了300个额外的合成训练样本。事后看来,这些合成示例过于重复,没有忠实代表原始任务——这是一个关于数据质量优于数量的教训。
尽管存在这个限制,使用GRPO和LoRA的训练产生了突出的结果。Qwen3-4B模型在40个保留样本上取得了0.825的评估分数。其他模型(DeepSeek Coder 1.3B、Gemma 3 1B)表现不佳——有些试图生成叙述性回答,有些则幻觉出更多SQL查询——但Qwen3架构似乎特别适合受约束的答案生成。
4、我们的收获
这项工作有三点突出之处。首先,当在特定任务数据上进行微调时,小型模型可以发挥远超其体量的能力——即使训练样本非常有限。第二,合成数据生成是一把双刃剑;它可以扩展数据集,但低质量的增强会引入噪声,如果没有严格的验证就很难发现。第三,约束答案空间至关重要。有限的BANT标签集几乎可以肯定地促成了第二阶段的强劲结果,但这种方法是否能推广到更具开放性的输出任务仍然是一个悬而未决的问题。
我们正在继续探索其他CRMArena任务中的这些问题。但早期的信号是清晰的:对于定义明确的企业工作流,小型语言模型不仅是可行的——它们可能是更明智的选择。
原文链接: Training A Small Language Model To Outperform Frontier Models On CRM-Arena
汇智网翻译整理,转载请标明出处
