/ultrareview:代码审查命令
比较 /ultrareview、CodeRabbit 和 Greptile 的权衡取舍

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
六天。四次发布。一个斜杠命令。
在 v2.1.111 中,Anthropic 发布了 /ultrareview:云端支持的、并行多代理代码审查,可以零设置运行。发布说明只有一句话长。更重要的是它如何发布的:一个可组合的基础设施栈,使得快速持续发布更多 ultra* 命令变得容易。到目前为止我们有了 ultraplan 和现在的 ultrareview。
本文涵盖:
/ultrareview做什么(以及不做什么)- 使其成为可能的基础设施演进路径
- 与 CodeRabbit 和 Greptile 的实际权衡取舍
- 它今天的定位,以及什么会改变竞争格局
1、/ultrareview 到底是什么
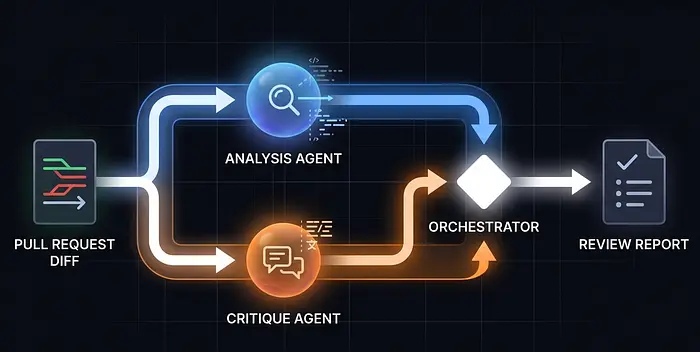
Anthropic 将 /ultrareview 描述为"使用并行多代理分析和评论的云端全面代码审查",有两种调用模式:
# 审查当前分支相对于基线
/ultrareview
# 通过编号获取并审查特定的 GitHub PR
/ultrareview <PR#>
三个要点很重要:
- 云端执行:这不是"更快地运行本地linter"。它将工作分派到云端审查管道。
- 并行多代理结构:关键主张不是"它能审查代码",而是"分析 + 评论"由多个代理完成。
- 按编号获取 PR:对于咨询和跨仓库工作,"无需克隆/切换分支即可审查"是突出的运营特性。
变更日志不会告诉你的三件事:
- 输出长什么样。 报告的形态(章节、严重性分级、示例等)决定了人们是否真正采用它。
- 评论阶段是否可见区分。 "分析和评论"在结构上可能是真实的,但在输出中可能不会作为单独的阶段暴露。
/effort是否影响/ultrareview。 v2.1.111 同时发布了/effort(包括 Opus 4.7 的xhigh)。目前不清楚/ultrareview是否继承会话的effort设置还是固定自己的。
2、使这一切成为可能的基础设施演进路径
/ultrareview 读起来像一个功能。它的行为像一个平台里程碑:由快速连续发布的基础组件组装而成的面向用户的命令。
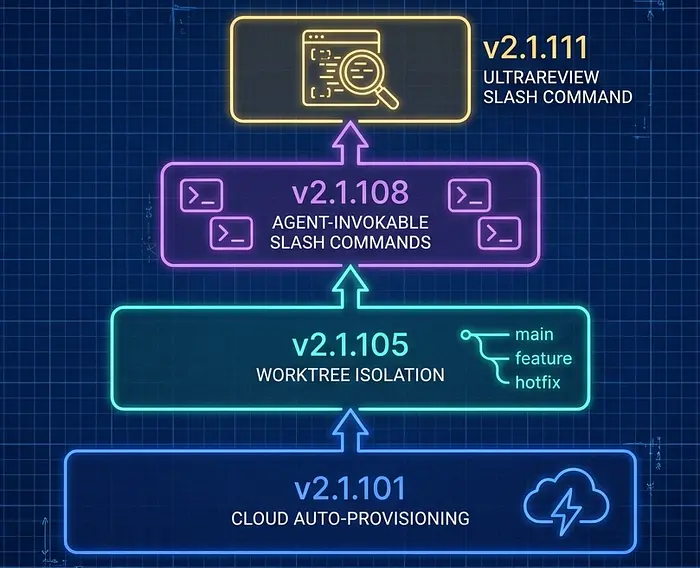
v2.1.101 — 云自动配置成为默认
远程会话功能自动创建默认云环境,无需先进行Web设置。
v2.1.105 — Worktree 隔离变得可复用
EnterWorktree 获得了 path 参数,支持跨现有worktree进行编排。对于并行代理,worktree隔离是使"并行"真正不互相干扰的关键。
v2.1.108 — 代理可以调用内置斜杠命令
模型可以发现并调用内置的斜杠命令,如 /review 和 /security-review 作为操作。这将"命令"变成了更高级编排的内部构建块。
v2.1.111 — /ultrareview 在此之上发布
有了云运行时 + worktree隔离 + 可调用命令,/ultrareview 是从该栈组装的第一个"一键式产品"。
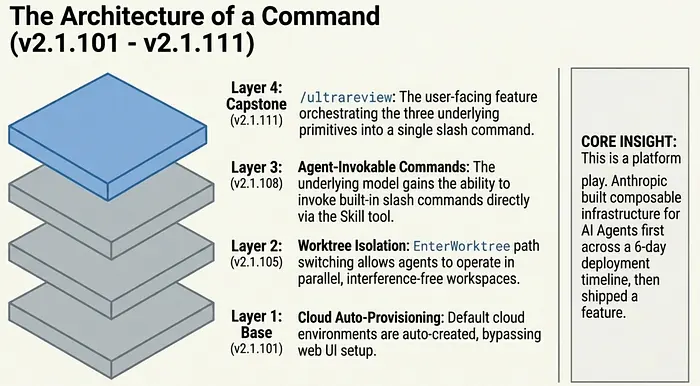
很明显,这不仅仅是一个斜杠命令。它下面有大量的基础设施。这是一个平台策略。两个ultra*命令。还会有更多吗?看起来是这样。
3、/ultrareview 实际产出了什么
它做什么
- 在你的当前分支diff上运行云端支持的审查,无需设置。
- 通过编号获取并审查 GitHub PR,无需你克隆或切换分支。
- 在 Claude Code 会话内给你一个对话式后续循环。
成本 + 延迟(截至 v2.1.111 的已知信息)
- 成本:
/ultrareview使用高级云计算。Pro 和 Max 计划包含 3 次免费运行(一次性)。之后,额外使用将消耗你计划的云计算/高级使用量(定价取决于计划)。 - 延迟:通常 ~5–10分钟,通常比单独的托管 GitHub App"Code Review"流程更快。
它今天不做什么
- 它不会写回 GitHub(没有内联 PR 评论;没有 PR 线程审计记录)。
- 它不会自动触发 PR 打开(你需要记得运行它)。
- 它不以透明的方式暴露模型/effort 控制(就公开文档而言)。
真实输出摘录
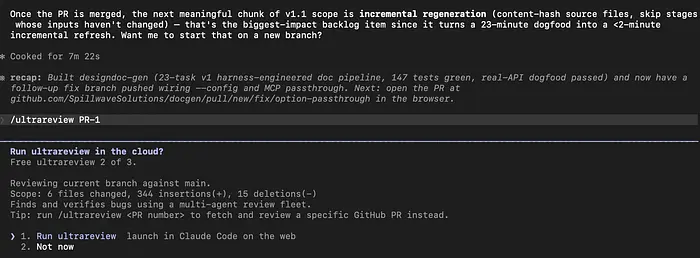
启动 UltraReview
❯ /ultrareview PR-1
⎿ Free ultrareview 2 of 3.
Ultrareview launched for main (~5-10 min, runs in the cloud).
Track: https://claude.ai/code/session_01BL8gEEr3mye2J7fDMabc
Scope: 6 files changed, 344 insertions(+), 15 deletions(-)
⏺ Ultrareview kicked off on the PR branch diff. I'll wait for the findings
to come back via notification — no polling needed.
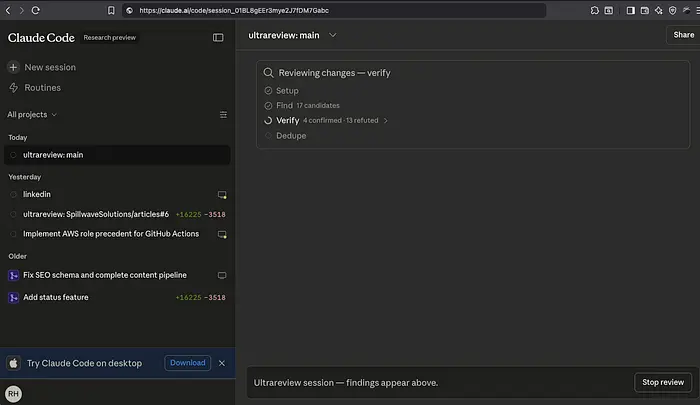
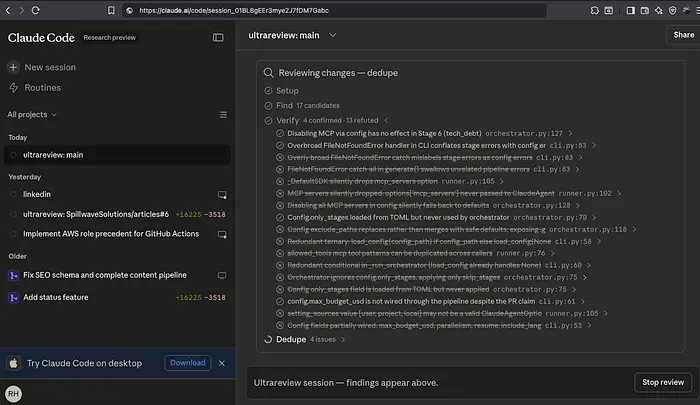
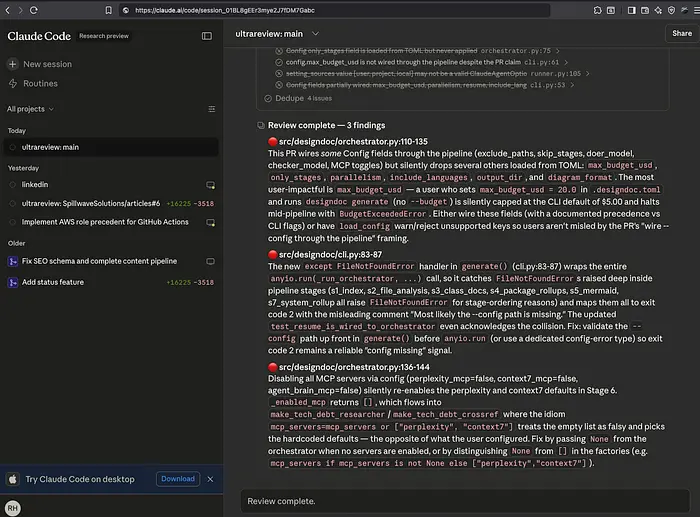
报告返回后 Claude Code 对其做出反应的示例输出。
Remote review completed
⏺ Three legitimate findings — the reviewer caught real gaps my tests missed. Fixing all three on this branch before merging.
⏺ bug_001 first (simplest). Failing test, then factory fix.
⏺ Write(tests/unit/test_tech_debt_mcp_disable.py)
⎿ Wrote 41 lines to tests/unit/test_tech_debt_mcp_disable.py
1 """Tests for MCP-disable coercion in tech-debt agent factories.
2
3 Bug: `mcp_servers=mcp_servers or ["perplexity", "context7"]` treats an empty
4 list as falsy and silently restores the default servers. When a user sets
5 all MCP toggles to false in config, the factory was picking the defaults.
6
7 Fix: distinguish `None` (caller didn't care, use defaults) from `[]`
8 (caller explicitly wants no servers).
9 """
… +31 lines (ctrl+o to expand)
⏺ Bash(uv run pytest tests/unit/test_tech_debt_mcp_disable.py -v 2>&1 | tail -10)
⎿ E + [
E + 'perplexity',
E + 'context7',
… +7 lines (ctrl+o to expand)
⎿ Allowed by auto mode classifier
⏺ Update(src/designdoc/agents/tech_debt.py)
⎿ Added 13 lines, removed 2 lines
6 from designdoc.runner import AgentDef
7
8
9 +_DEFAULT_TECHDEBT_MCP: list[str] = ["perplexity", "context7"]
10 +
11 +
12 +def _resolve_mcp(mcp_servers: list[str] | None) -> list[str]:
13 + """None = caller didn't specify, use defaults. `[]` = caller explicitly
14 + wants no servers. Any other list passes through as-is."""
15 + if mcp_servers is None:
16 + return list(_DEFAULT_TECHDEBT_MCP)
17 + return list(mcp_servers)
18 +
19 +
20 def make_tech_debt_researcher(
21 model: str = "claude-sonnet-4-6", mcp_servers: list[str] | None = None
) -> AgentDef:
...
26 model=model,
allowed_tools=[],
max_output_tokens=1024,
18 - mcp_servers=mcp_servers or ["perplexity", "context7"],
29 + mcp_servers=_resolve_mcp(mcp_servers),
30 )
31
32
...
39 model=model,
allowed_tools=[],
max_output_tokens=1024,
31 - mcp_servers=mcp_servers or ["perplexity", "context7"],
42 + mcp_servers=_resolve_mcp(mcp_servers),
43 )
44
...
⏺ Bash(uv run pytest tests/unit/test_tech_debt_mcp_disable.py -v 2>&1 | tail -10)
⎿ plugins: cov-7.1.0, anyio-4.13.0
collecting ... collected 5 items
… +7 lines (ctrl+o to expand)
⎿ Allowed by auto mode classifier
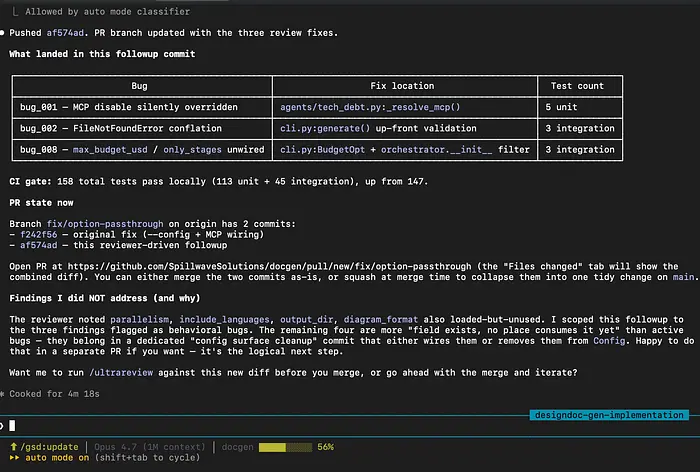
⏺ bug_002 next — narrow the FileNotFoundError handler.
✢ Wiring max_budget_usd and only_stages… (1m 6s · ↓ 1.4k tokens · thought for 17s)
⎿ ◼ Fix bug_008: wire max_budget_usd and only_stages from config
◼ Fix bug_002: narrow FileNotFoundError handler to config path only
✔ Fix bug_001: MCP disable flags silently overridden by factory or-idiom
4、/ultrareview vs 其他:实际权衡取舍
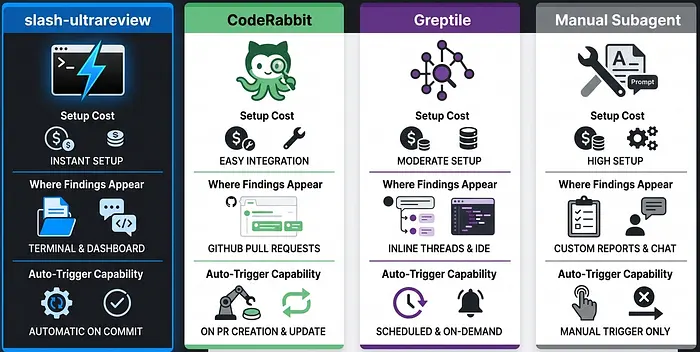
核心区别
/ultrareview优化的是 Claude Code 内部的零摩擦体验。- CodeRabbit / Greptile 优化的是 GitHub 内的团队工作流(自动化 + 持久化 + 内联评论)。
零摩擦
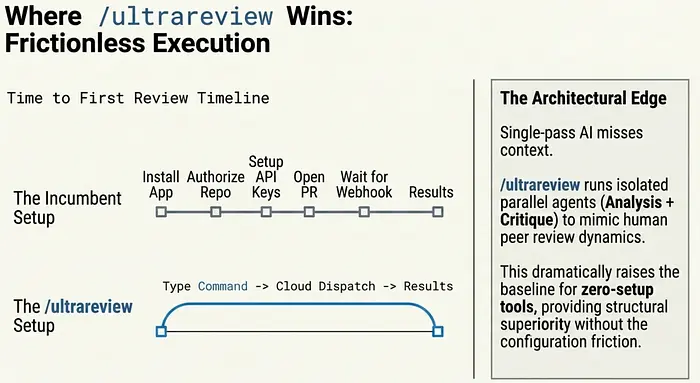
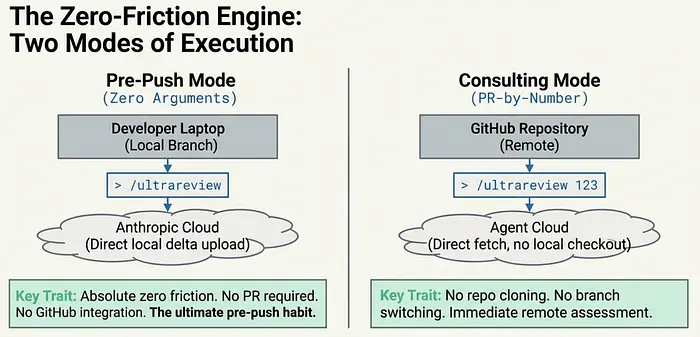
/ultrareview(Claude Code)
- 设置:无(如果你已经在使用 Claude Code)
- 触发方式:手动
- 输出位置:Claude Code 会话
- GitHub 写回:否
- 最适合:推送前习惯;跨仓库快速审查"现在审查这个 PR"的咨询场景
CodeRabbit
- 设置:GitHub App + 仓库配置
- 触发方式:PR 打开时自动触发(可配置)
- 输出位置:PR 线程 + 内联评论
- GitHub 写回:是
- 最适合:希望每个 PR 都自动审查、且需要持久化线程 + 审计可追溯性的团队
- 注意:免费层级和每小时限制的细节随时间有所变化;发布前请对照官方计划页面确认当前限制。
Greptile
- 设置:索引 + 配置
- 触发方式:PR 打开时自动触发 + 手动
@greptileai - 输出位置:PR 线程 + 内联评论
- GitHub 写回:是
- 最适合:希望获得与代码库上下文感知的审查、且直接绑定 GitHub 协作的团队

/ultrareview vs CodeRabbit vs Greptile:实际权衡取舍/ultrareview 的优势(今天)
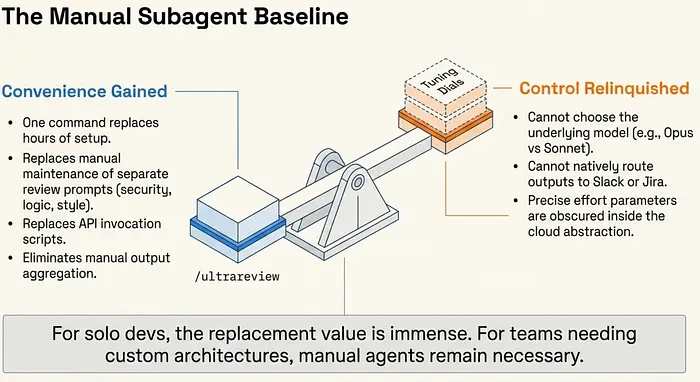
- 最快路径实现"有审查发生了"。 如果你已经在 Claude Code 中,没有集成成本。
- 咨询模式是真实有效的。 按编号获取 PR 在跨仓库快速审查方面是出色的运营体验。
- 并行评审作为默认姿态。 即使不完全透明,批评阶段的存在是该功能中最重要的设计选择。
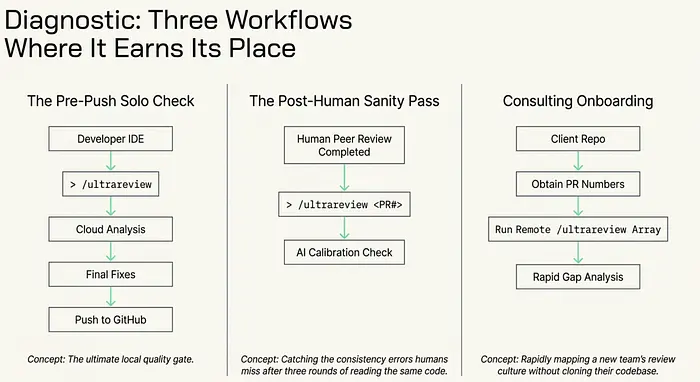
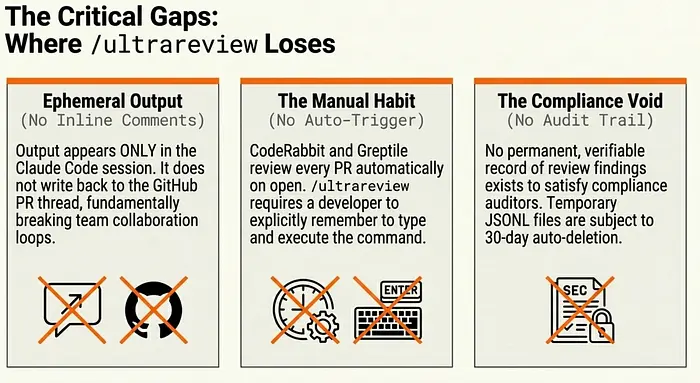
/ultrareview 的不足(今天)
- 没有 GitHub 原生工作流。 没有内联评论,没有共享的团队记录,没有线程化解决流程。
- 手动调用是脆弱的。 在截止日期压力下习惯会退化;自动化才能赢得采用。
- 配置面不透明。 关心工作量/模型透明度的团队会更偏好可以调优或至少可以推理的工具。
/ultrareview 的不足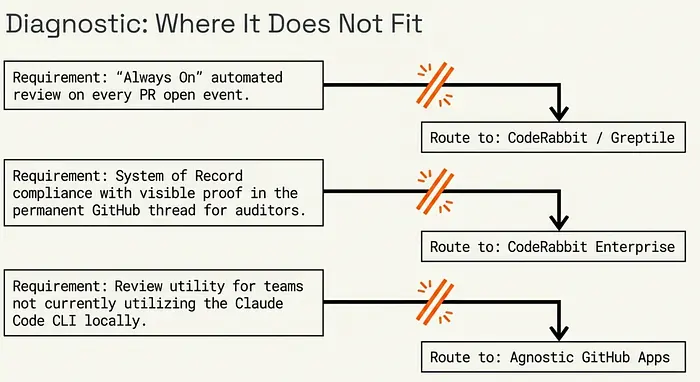
6、Anthropic 尚未回答的五个问题
- 到底是什么模型驱动这些代理?
- 有多少个代理并行运行?
/effort是否影响/ultrareview,还是固定的?- 输出能否发布到 GitHub(现在或将来)?
- 三次免费运行后,配额/成本如何计算(token vs 计算 vs 计划限制)?

原文链接:Claude Code Ultrareview vs CodeRabbit vs Greptile
汇智网翻译整理,转载请标明出处
