UniAD 自动驾驶基础模型
UniAD是端到端自动驾驶的基础模型。它于2023年4月由OpenDriveLab、武汉大学和商汤科技研究院联合提出,并荣获CVPR 2023最佳论文奖。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
在自动驾驶中,系统从摄像头输入中识别3D边界框,使用运动预测跟踪对象,通过占用估计检测障碍物,并在规划阶段使用规划器确定最优路线。在传统的自动驾驶系统中,感知、预测和规划是作为独立模块实现的。
在端到端自动驾驶中,这些模块相互连接,允许在训练过程中从规划阶段反向传播回感知阶段。这使得每个模块能够学习更丰富的中间表示,并提高整体精度。
此外,传统自动驾驶系统通常依赖预构建的静态点云地图和自定位来确定车辆位置,并基于地图使用虚拟引导进行导航,而UniAD则在线创建地图,消除了对静态地图的需求,实现了无需静态地图的自动驾驶。
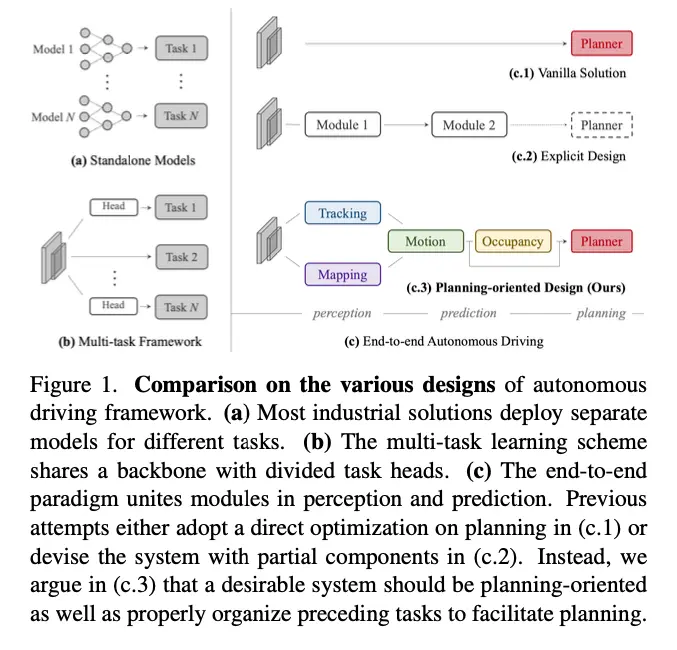
1、架构
UniAD不使用激光雷达,而是处理多视角摄像头图像。这些摄像头图像在BEV(鸟瞰视图)特征空间中处理。在此空间中,UniAD使用TrackFormer生成和跟踪智能体(如迎面车辆和行人),使用MapFormer在线创建地图,使用MotionFormer预测每个智能体的轨迹,使用OccFormer预测占用情况,并使用Planner进行路径规划。
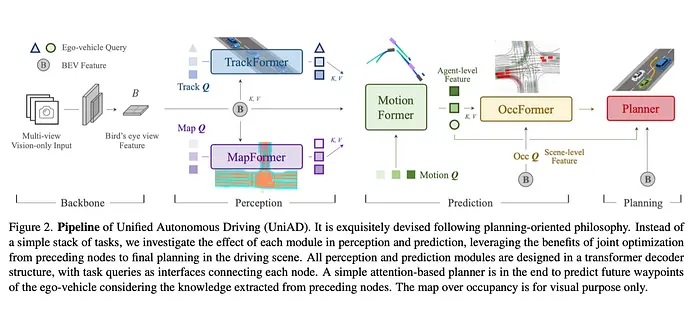
以下是将UniAD的中间预测结果投影到摄像头图像和BEV空间的可视化示例。虽然UniAD以端到端方式进行学习和轨迹预测,但每个模块的输出可以单独可视化,从而验证系统是否正确识别了环境。

2、关于BEV
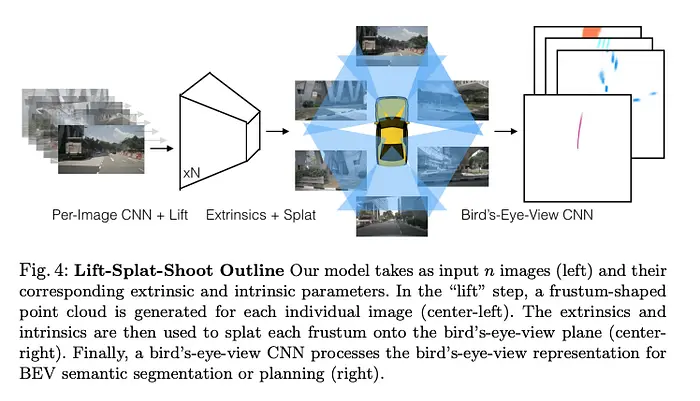
从输入图像生成平截头体特征,然后通过BEV变换重新排列为俯视视角。
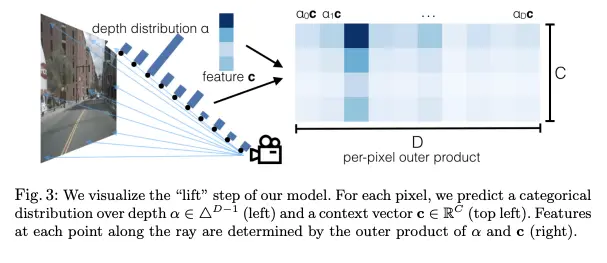
首先,对摄像头图像应用ResNet提取2D特征,然后将其转换为带有深度信息的平截头体特征。平截头体是一种3D形状,通常是金字塔或锥体,定义了从摄像头或视点可见的区域。该区域内的对象是摄像头能够捕捉到的。平截头体特征表示为体素,每个体素包含使用ResNet提取的特征值。这种结构使得摄像头图像和类激光雷达空间信息得以统一处理。
从2D"提升"到3D有多种方法。包括使用2D深度估计、摄像头位姿和配置,或使用激光雷达信息作为约束的方法。
最后,数据从平截头体特征通过BEV变换重新排列为俯视视角。
3、深入了解每个架构模块
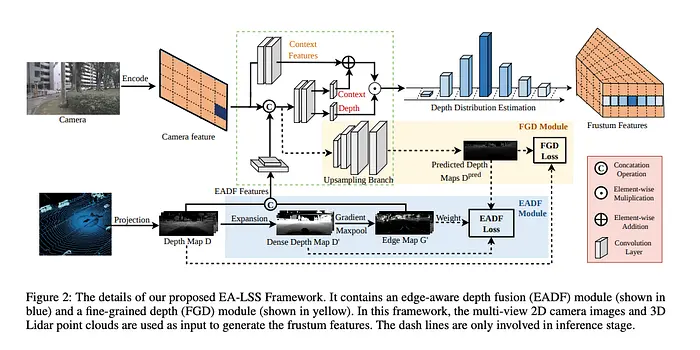
MotionFormer接收TrackFormer和MapFormer的输出作为键和值,并将其与BEV特征结合,使用多层感知器(MLP)预测轨迹。
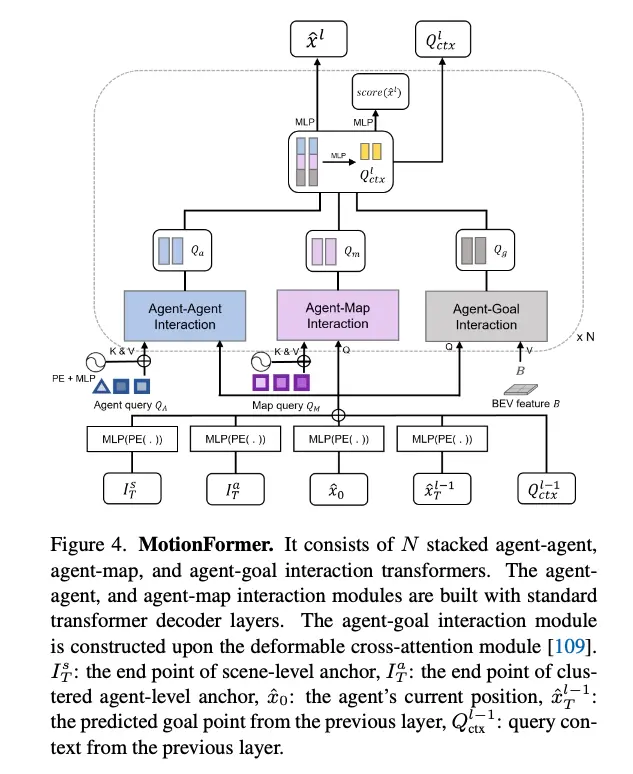
OccFormer采用Transformer结构,使用自注意力和交叉注意力,预测单帧的占用情况。
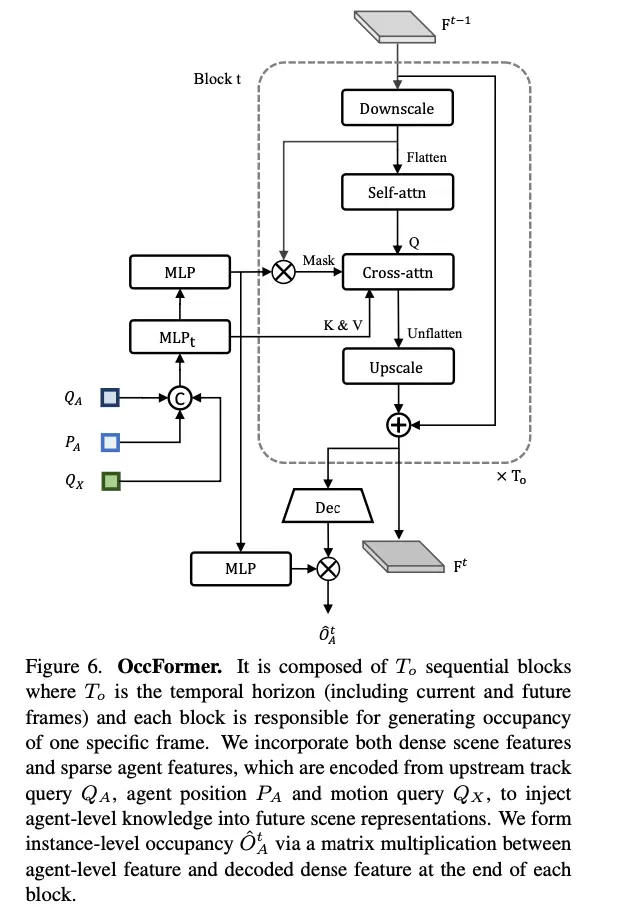
在Planner中,接收来自多帧的占用信息,并使用MLP预测最优轨迹。
4、评估
UniAD已在nuScenes数据集上进行了评估。
虽然UniAD是端到端训练的,但它在目标跟踪等单项任务上达到了接近最优的性能。
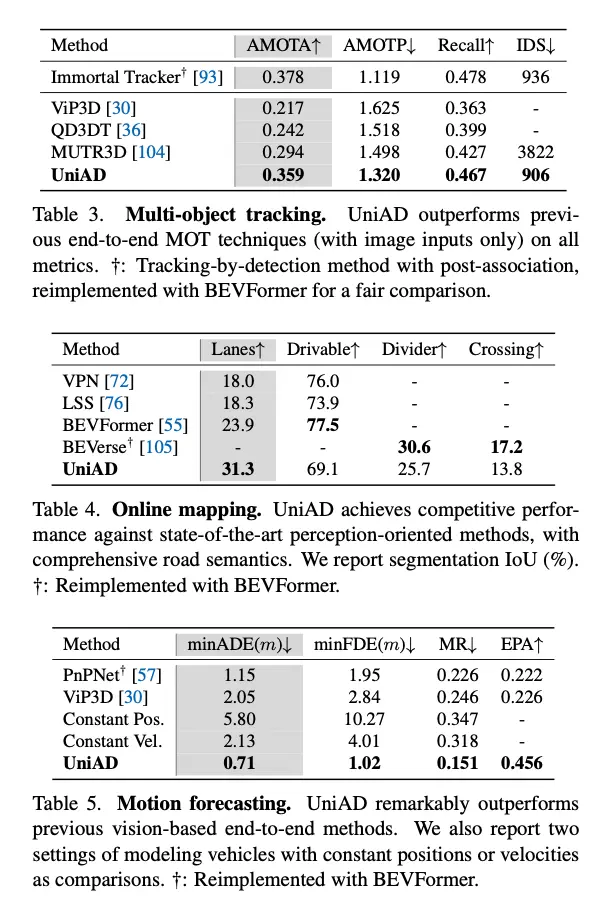
在规划方面,它达到了最先进的性能。
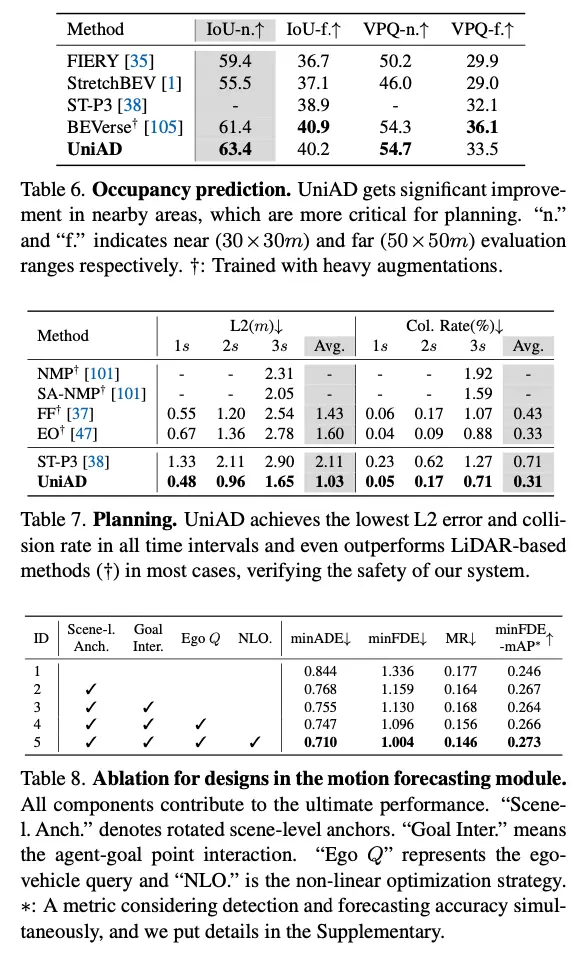
5、计算成本
UniAD提供三种变体:S、M和L。

使用所有模块处理一帧所需的总FLOPS为1.7T FLOPS。

6、结束语
UniAD作为端到端自动驾驶的基础模型,此后已演进到集成激光雷达的FusionAD等模型,被认为是端到端自动驾驶系统发展的基石。
原文链接:UniAD: Foundational Model for End-to-End Autonomous Driving
汇智网翻译整理,转载请标明出处
