探索智能体工程的 5 个教训
看到人们为了"Agentic 智能"而放弃人类专业知识,这让人感到遗憾。我觉得社会正在走向《蠢蛋进化论》和《瓦力》那样的漫画式反乌托邦。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
去年12月,我在玩 Ollama 和 Gemini API,试图创建一个能运行类似 DND(龙与地下城)文字冒险游戏的 Agent。我最终放弃了,因为状态管理对 Ollama 来说太难了,甚至对 Gemini 2.0-flash 来说也太困难。我最终放弃了创建一个可用的 DND 模拟器,转而做了一个简单的计数器,附带一个旁白来解释用户的更新操作。
在那次尝试结束时,我得出的结论是:
"让 LLM 更新状态,就好比让詹姆斯·乔伊斯帮你报税一样离谱。"
然而,在那之后的几个月里,我收回了自己说的话。Claude Code、OpenClaw 以及最近几个月涌现的一系列 Agentic 程序,集体震撼了整个科技行业。我第一次使用 Claude Code 是在二月中旬,用来完成 BetaZero UI 的构建。其速度、体量和编码能力远远超越了我之前从 Agentic 编码工具中体验到的任何东西。
所以,带着这个背景……
项目 1:James Joyce,税务助手
https://github.com/EvanMcCormick37/mvp-james-joyce
这是我要谈到的项目中的第一个。我用了 2 天时间完成了它,作为丹佛一家公司第三轮面试的作品(我走完了全部四轮面试,但遗憾地未能获得实习机会)。
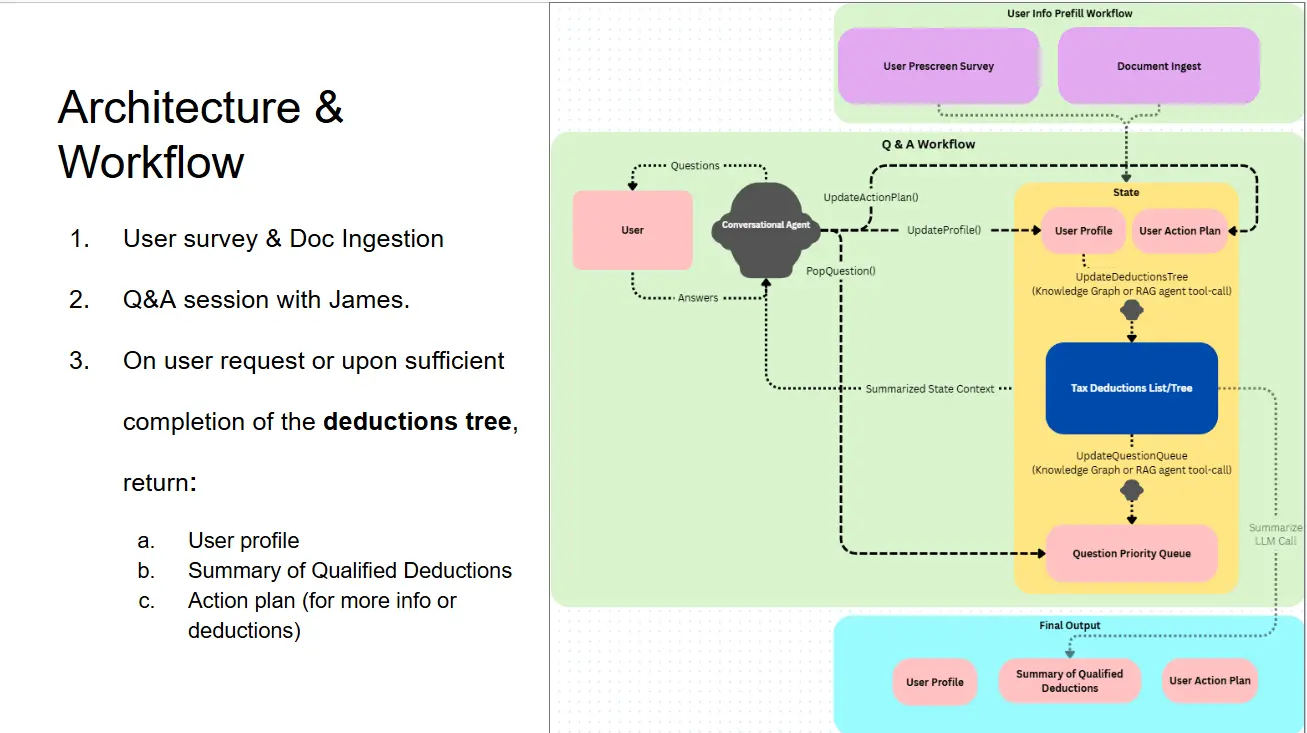
我花了大约一个小时确定了最初的概念。一个能引导你了解税务状况、帮你列出可能有资格获得的扣除项的 Agent,同时还会构建一个行动计划,帮助你获得最大可能的税务扣除。
教训 1:快速迭代,手动测试
当我最初有这个想法时,工作流看起来与上面的图表完全不同。我最初设想模型是一个 Agentic Graph-RAG 问答系统,使用基于当年官方 IRS 出版物构建的知识图谱和向量数据库。我想象用户提出一个问题,模型提供一个有据可查、带来源的答案,同时附带 1-2 个相关问题,帮助确定用户的扣除资格。
我考虑了架构,起草了一份 ARCHITECTURE.md,然后用 Claude Code 在不到一小时的时间内完成了一次 one-shot 构建。
但当我实际使用这个应用时,感觉有些不对劲……
问题出在问答工作流上。用户的每条陈述和问题都会收到一大段文字回复,末尾附带一个询问财务历史中某个随机方面的问题。这既不是优雅的对话,也不是节省时间的应用。事实证明,标准的 RAG 文档问答工作流在这个用例中根本行不通。
于是我尝试了别的方法。我直接和 Gemini 聊了聊我可能获得的扣除项,然后想象如何改进这个体验。
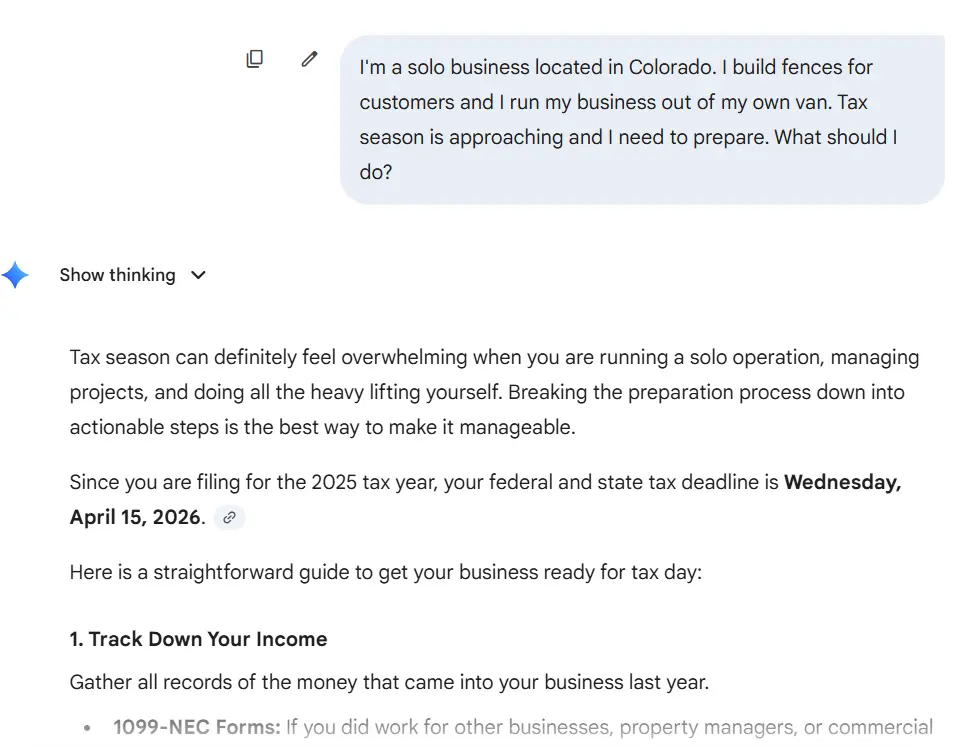
在原始基础模型上测试工作流。
Gemini 的强项在于其对话性。它清晰地回答了每个问题,给了我探索的方向,而且从不让人觉得它在强行推销某个话题。这就是对话式 Agentic 应用的优势所在。
我重新调整了设计,优化对话流程而非数据组织。我大幅简化了上下文工程:我用一个 YAML 文件替代了整个 Graph-RAG 系统,将 IRS 个人扣除指南转换后作为系统提示的上下文。模型使用 tool-calling 来更新三个输出文件:user-profile.yaml、deductions-tree.yaml 和 action-plan.yaml。我没有让模型试图用无尽的引用来回答用户问题,而是告诉它专注于提出正确的问题:我让它把对话当作一场"20个问题"的游戏,尽量用最少的对话轮次确定用户的所有扣除资格。
教训 2:能用一个 Agent 解决的,就不要用两个
这一点应该不言自明。在设计应用架构时,我最初考虑使用一个 Agent 与用户对话,另一个来更新状态。同时,确定用户的税务扣除资格要么使用 Agentic Graph-RAG + 推理模型,要么使用一个"税务引擎"(一个 DAG,每个节点包含一个计算或决策。想想杂志上那些"你的男性名人偶像是谁?"的性格测试题,只不过问题变成了"你有资格获得哪些税务扣除?")。但关键在于:多个 Agent 意味着多个"上下文"。"状态更新"Agent 需要了解多少对话内容才能正确更新状态?它的上下文每次都一样吗,还是随每次函数调用而修改?Agent 之间如何"通信"?它们是开启对话,还是使用"消息"函数互相通信?
你的程序中运行的 Agent 越多,出现误沟通、混乱乃至失败的空间就越大。有趣的是,这也是设计确定性系统时的一个好准则:一个单体服务容器通常比 10 个通过易拉罐和绳子互相通信的微服务更优雅、更容易实现。
教训 3:尊重 KV Cache
在最初构建应用时,我一直在纠结如何向模型提供应用的当前状态(回顾一下:user-profile.yaml、deductions-tree.yaml、action-plan.yaml)。我们的税务助手必须知道应用的当前状态才能提出"最优"问题(即能解决最多未确定扣除项的问题)。但我们应该如何向它提供这些状态呢?如果我们只是在每次用户回答时不断提供新状态,就会在上下文窗口中塞满旧状态的"幽灵"。我们确实需要一种方法让模型识别应用的当前状态,而且仅仅是当前状态。我最初的想法既简单又天真:把状态直接反馈到系统提示中!
这是一个重大失误。
LLM 有一个叫做 KV Cache 的特性。它保存了与之前生成文本关联的已计算推理值。因此,在每个生成步骤中,模型只计算最近生成 token 的关联。这意味着:1) 模型的运行成本显著降低,2) 它的扩展是线性的而非二次的(尤其适用于长上下文窗口),3) 你永远不应该修改上下文窗口开头的 token。
如果你确实编辑了模型上下文窗口开头的上下文,就会迫使它重新计算你编辑之后每个 token 的 KV 对。这非常昂贵。我第一次运行 James Joyce 的"上下文注入"实现时,一次 20 轮的对话就在 Anthropic API 上花了 1.50 美元。
我最终采用的解决方案是将当前状态作为用户当前问题的前缀注入,并在每次新的对话步骤中,从用户之前的问题中剥离过时的状态。如果让我回头改进这个项目,我会尝试在每个用户查询中保留所有状态视图。
项目 2:Scathach Agentic 导师
https://github.com/EvanMcCormick37/scathach-tutor
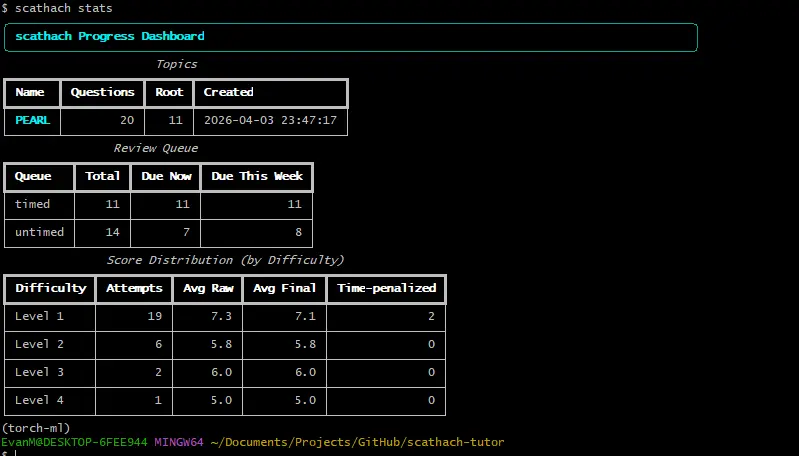
我在 Scathach 上的当前"统计"页面
这个项目与我的个人经历更近一些。过去一年我读了很多东西:研究报告、独立文章、研究论文、博客文章等等。然而,我经常担心自己并没有真正从所读的内容中学到东西,或者这些知识在几个月没有深入接触后已经淡忘了。
LLM 帮助我发展和测试对所读论文的理解。它们让我能立即与一个了解相关话题的实体进行对话。它们还可以创建测试题,让我能在惊人的深度上测试自己对某个话题的理解。但我希望这些对话能在我脑海中留下持久的印象。
为了解决这个问题,我构建了 Scathach。它本质上就是"阅读文章 -> 回答关于该文章的小测验"的工作流,封装成了一个 Python 包。除了基本的测验功能外,它还将所有已回答的问题存储在配备了 FSRS 算法的数据库中,这样随着越来越多的文档被导入系统,用户可以选择性地复习他们最不擅长的文档。它目前可以作为 Python 包安装在你的本地 Python 环境中。
教训 4:警惕范围蔓延
在迭代 Scathach 和 James Joyce 时,我最初用 React 前端 + REST API + FastAPI 后端构建了 MVP。为什么不呢?反正编码整个东西也只花了 15 分钟。
事实证明,即使有 Agentic 编码工具,范围蔓延也是非常真实的。重构往往比初始构建更棘手,而且当你 vibe coding——抱歉,"Agentic 工程化"——时,你一开始并不会对架构有深入的理解。
我很快发现自己更喜欢在没有"全栈"架构的情况下开发这两个应用。当我开始设计和构建这些应用时,我对想要什么和用例是什么有一个粗略的想法,但对工作流会是什么样子并没有清晰的愿景。我发现这个简单的设计周期在快速迭代和改进产品设计方面非常强大:
设计 -> 实现 -> 手动测试
一旦我对 Scathach 的工作流感到满意,我可能会把它构建成可执行文件或云应用。不过目前,我满足于继续用我那个精巧的 Python 模块进行迭代。
教训 5:领域知识永远重要
所以……我确实尝试过把 Scathach 构建成可执行文件。更准确地说,我让 Claude Code 把 Scathach 构建成可执行文件。我想把它移植成一种我爸爸(他不太懂技术)能使用的格式。它构建了完整的前端和 API,将后端编译成二进制文件,并使用一个 Rust 库将所有内容打包成一个可以安装到用户电脑上的 .exe 文件。
那么,我对 Rust、Tauri 或者将应用编译成二进制 .exe 文件了解多少?一窍不通。但 Claude 了解,所以应该没问题。嗯,如果我有这些方面的经验,可能确实没问题。
实际发生的是,我花了一个小时搞清楚为什么 npm 构建脚本不工作,然后又为 Tauri 二进制文件查找和格式化图标,最后顺利安装了 .exe……结果安装后的程序打不开。
当然,我肯定只是犯了某个初学者错误。在 Tauri+Rust 二进制编译方面更有经验的人会立刻修好它。而且我相信如果给那个人 Claude Code 的使用权,他们会构建一个好 10 倍的应用版本,而且会抱怨说"这不是我自己写的"。但从某种意义上说,他们确实写了。即使在依赖"专家 Agent"的时候……
……人类专业知识仍然很重要。
这也是我暂时把这个应用保留为 Python 脚本的另一个原因。只要我理解它,我就能智能地继续更新它。
看到人们为了"Agentic 智能"而放弃人类专业知识,这让人感到遗憾。我觉得社会正在走向《蠢蛋进化论》和《瓦力》那样的漫画式反乌托邦。但即使在智能 AI 系统的时代,那句老话依然适用:垃圾进,垃圾出(Garbage In, Garbage Out)。
就这些了,各位!如果你想试试 Scathach,只需按照 README 上的安装说明操作即可。
原文链接: 5 Lessons Learned Exploring Agentic Engineering
汇智网翻译整理,转载请标明出处
