AI驱动的SDLC:从代码生成到编排
代码生成解决的是语法问题。软件工程是一个对齐问题。早在编写一行生产代码之前,大量的工程资本就花在了导航团队和制品之间的鸿沟上。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
在过去的两年里,AI主导了软件工程的对话——而行业的集体关注点一直瞄准一个指标:更快地生成代码。
开发者常规地使用AI来快速创建函数、生成单元测试、跳过样板代码、以及搭建整个应用程序。工程组织竞相计算以前所未有的速度编写语法所带来的生产力提升。
但在构建和实验AI辅助开发工作流程的过程中,我获得了一个深刻的认识:
大多数软件项目的失败不是因为工程师代码写得不够快。它们因为模糊性而失败。
代码生成解决的是语法问题。软件工程是一个对齐问题。早在编写一行生产代码之前,大量的工程资本就花在了导航团队和制品之间的鸿沟上:
- 产品经理和工程师对需求的解读不同。
- 系统架构独立于实现而演进。
- API契约不断漂移,打破团队之间的依赖关系。
- 前端和后端团队做出平行的、孤立的假设,这些假设从未被正式协调。
当手触到键盘时,多个相互冲突版本的"真相"已经存在于PRD、架构图和设计文件中。
在这种环境下更快地生成更多代码并不能解决核心问题——它加速了不一致性。它让我们以两倍的速度构建错误的东西。
1. 速度的幻觉:欢迎来到制品漂移
当我最初开始在软件工程中实验AI时,我陷入了大多数开发者都有的模式。我打开ChatGPT、Claude和GitHub Copilot,把它们当作超快的技术写手。
起初,结果感觉像魔法。在几分钟内,我生成了架构概述、OpenAPI契约和实现计划,这些通常需要几天的专注手动工作。
然后现实到来了。
随着项目范围的扩大,一个微妙但极具破坏性的问题出现了。根本问题不是制品生成——而是制品对齐。
因为我把AI当作一系列断开的提示词会话,输出开始分裂:
- 系统架构中的一个关键转向从未反映在API契约中。
- 对API规范的细化从未更新实现计划。
- 前端假设与后端数据模型默默偏离。
- 数据库模式完全与事件驱动消息的形状不同步。
每个文档看起来各自完整。作为一个有凝聚力的生态系统来看,它们是破碎的。
讽刺的是,AI的速度使这种情况更糟。它成为不一致性的力量倍增器——我生成不对齐的规范的速度比手动协调它们的速度还快。
工程管理的真正挑战不是产生更多文档。而是在整个交付生命周期中维持对齐。
软件工程通过一系列相互关联的制品链移动:
Business Requirements → System Architecture → Data Models → API Contracts → Implementation Plans → Code
每个制品影响并约束下一个。当AI被视为一组孤立的提示词会话时,这个链条就断裂了。早期引入的小不一致会向下游传播,最终成为架构漂移、返工和交付摩擦。
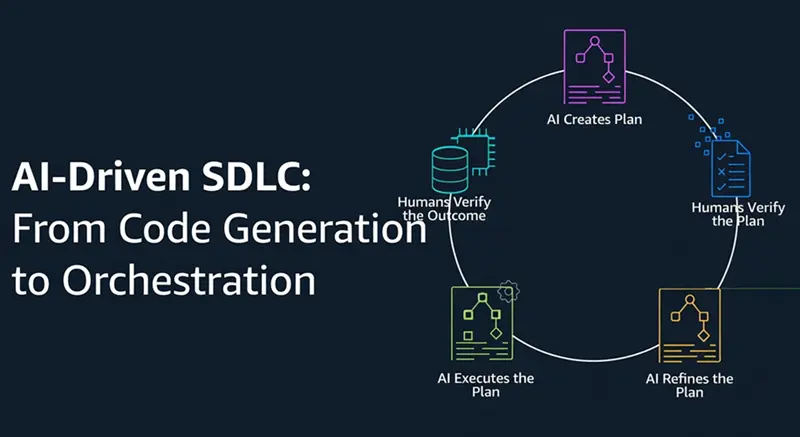
2. 治理驱动的AI框架
一旦我确定了制品漂移是核心问题,我的本能和几乎每个工程师一样:写更好的提示词。
每当输出漂移时,我调整系统提示词——添加上下文、新约束、更严格的格式规则。一段时间内,这有效。但随着复杂性扩展,提示词开始变异。
2.1 提示词单体
一个简单的架构生成提示词很快膨胀成几百行文本。提示词积累了格式规则、编码风格例外、框架选择和治理约束。
不久,我无意中重新创造了一个经典的反模式:单体——但是是针对AI编排的。所有规则都在一个地方,但系统变得脆弱、不可维护,越来越容易受到指令冲突的影响。
2.2 提示词→代理→技能模型
修复方法是将我们在软件中使用的相同架构原则应用到我们的AI编排中。如果我们重视关注点分离和单一职责原则在我们的代码中,为什么在AI系统中放弃它们?
我将职责分离到三个独立的、解耦的层:
1. 提示词(入口点) 刻意保持最小化。它的唯一工作是捕获用户的即时意图、解析执行范围并加载高层上下文。声明式的,而非过程式的。
2. 代理(编排器) 定义运行时行为和执行策略。它确定如何解析上下文、需要哪些专门能力、哪些治理规则必须活跃、以及输出应该如何优化。
3. 技能(可复用的执行块) 原子的、专门的、完全可复用的。每个技能封装一个特定的技术领域,带有严格的输入/输出验证模式、治理策略和标准化模板。一个GenerateOpenAPISpec技能可以被整个生态系统中多个不同的代理调用,而无需一行重复。
这种分离同时解决了三个企业级问题:
- 真正的可复用性——同一个架构验证技能在完全不同的项目生命周期中工作。
- 有保障的治理——架构约束作为验证门硬编码在技能层。AI无法绕过它们。
- 确定性演进——更新工程标准(例如,从REST切换到GraphQL)只需要更新特定技能。每个继承它的代理立即更新。
3. 制品管道
有了编排模型,下一个挑战是确定框架应该生成什么——以及以什么顺序。
生产级交付从根本上是一个制品驱动的过程。每个实现决策之前都有上游约束。后端服务不会凭空出现;它由数据模型塑造、受API契约约束、由工程标准治理、并由业务需求触发。
软件交付不是一系列独立的输出。它是一个不可变的依赖链。
4.1 SDLC依赖图
我建模了制品之间的精确关系路径——一个顺序管道,其中每个阶段既是前一阶段的结构化输出,也是下一阶段的严格输入。
关键原则:**具体的制品不如它们之间的关系重要。**组织可能会添加威胁建模、领域建模、安全审查或部署架构。目标不是强制执行一个僵化的序列——而是显式地建模依赖关系,让每个制品都理解它的上游输入和下游影响。
在我的实验中,完整可追溯性的最小集是:
因为管道是顺序流动的,上游更改以编程方式决定下游输出。当业务需求演进时,框架精确标记哪些下游制品受到影响。当架构边界更改时,受影响的API契约和实现任务被系统地重新生成。
框架停止生成任意文档。它开始生成受治理的、合规的软件制品,具有完全的架构可追溯性。
4. 前端设计提取
即使有了受治理的系统架构和坚实的API契约,仍然有一个出了名的脆弱的交接点:设计意图很少能从Figma存活到生产代码的旅程。
开发人员经常被留下来解读静态布局、逆向工程微交互、并对响应式行为、无障碍要求、状态管理模式做出平行的假设。
我最初的尝试将视觉布局输入到多模态LLM中。输出是描述性的,但对工程来说从根本上没用——知道一个屏幕"包含一个数据表、一个过滤面板和一个顶部工具栏"并不能告诉前端工程师应该映射哪些设计系统组件、响应式断点应该如何表现、或者需要什么ARIA属性。
4.1 屏幕上下文制品
为了弥合这个差距,我在管道中引入了一个中间节点:
Figma Screen → Screen Context Artifact → Frontend Implementation
框架不是直接从视觉资产跳到原始组件模板,而是首先生成一个结构化的屏幕上下文制品——将视觉意图转化为明确的工程意图:
### Screen Context: User Management Dashboard
- **Business intent:** Centralized admin boundary for multi-tenant user provisioning
- **Component mapping:** mat-table with async MatTableDataSource, binding to IdentityModule endpoints
- **Responsive behavior:** CSS Grid transitioning to single-column flex below 768px
- **Accessibility (A11y):** aria-live regions for dynamic status updates; explicit tabindex for keyboard nav
- **Interaction states:** Loading overlays, structural empty-state variants, error lifecycle states
就像后端管道一样,屏幕上下文生成受一个专门的前端治理技能约束,该技能强制执行设计系统组件指南、无障碍政策和Angular Material约定。
4.2 一个关键发现:上下文优于代码
这个阶段产生了整个项目中最出乎意料的教训之一:AI最高杠杆的使用是上下文生成,而不是代码生成。
当AI直接从Figma资产编写原始Angular组件时,输出是不一致的——混乱的CSS覆盖、非标准结构。当框架先生成屏幕上下文制品时,工程结果显著改善。有了明确的、受治理的规范,人类开发者和下游代码生成工作流程都以近乎零的不确定性执行。
5. 后端实现
为了证明框架在实时环境中的价值,我选择了一个非平凡的试验场:一个身份和访问管理模块。
开发不是急于生成样板代码,而是严格从制品管道的起源开始。到编码开始时,业务需求已经定义了认证能力,系统架构已经建立了模块边界,数据架构已经建模了Users/Roles/Credentials/Sessions,API契约已经锁定了请求/响应负载。
目标不再是发现系统应该如何行为。而是执行已经在架构上达成一致的内容。
5.1 模块化单体架构
我选择了一个有条理的模块化单体架构而不是微服务——在逻辑模块边界内隔离业务能力,同时保持清晰的关注点分离:
IdentityAndAccess.Api
│
▼
IdentityAndAccess.Application <── [CQRS & MediatR Core]
│
▼
IdentityAndAccess.Domain
│
▼
IdentityAndAccess.Infrastructure
每层都有一个单一的、明确的职责——分别是HTTP编排、用例逻辑、领域纯粹性和基础设施关注点。
5.2 追踪谱系
以一个标准的会话初始化端点为例:POST /auth/sessions。每个实现决策都追溯到受治理的上游制品:
Business Requirement → Authentication Architecture → Identity Data Model → API Contract → Implementation Plan → POST /auth/sessions
这个谱系消除了实现期间的重新发现。端点不是局部工程假设的结果——它是在整个管道中已经验证的决策的实现。
真正的胜利不是更快的代码生成。而是加速的组织对齐。
6. 有效的部分:诚实的回顾
经过数周的构建、破坏和改进,潜在的教训很清楚:框架的成功与原始代码生成几乎没有关系。它真正的力量是系统地消除模糊性。
对齐的扩展性优于生成。 因为每个制品都从前一个阶段消费结构化上下文并将受治理的参数传递给下一个阶段,矛盾的假设降到了接近零。团队从不可变的、经过验证的制品链中进行推理,而不是从Confluence页面和Slack线程中。
嵌入式治理根除了决策疲劳。 命名约定、微架构边界、API路径格式、组件层次结构——各自微不足道,集体上令人精疲力竭。通过将这些硬编码到技能层,决策变成了自动化约束而不是反复出现的争论。
可复用的技能比可复用的提示词更持久。 我曾假设一个精心设计的提示词库将是系统的核心价值。事实证明恰恰相反。提示词是易变的——不断被重写、破坏和重构。一个设计良好的、经过模式验证的处理OpenAPI验证或系统架构映射的技能可以在完全不同的项目中零修改地复用。
"提示词是临时的。能力是持久的。"
架构可追溯性成为战略资产。 每个实现细节都有可见的、不间断的谱系——从数据库模式的一行回溯到整个依赖图。变更管理发生了转变:当产品经理更改需求时,框架立即映射出哪些下游制品需要重新生成。
7. 不起作用的部分:残酷的现实检验
过度编排是真实的。 一旦提示词→代理→技能模式被证明成功,我开始过度抽象一切。每个小工作流都有一个专门的代理。每个微不足道的解析工具都变成了一个技能。框架开始表现出教科书般的偶然复杂性。不是每个问题都需要一个自主代理循环——治理和编排应该存在于它们创造杠杆的地方,而不是存在于制造仪式的地方。
提示词膨胀不是架构。 每当输出漂移时,我的本能是添加更多指令。提示词膨胀成文字墙,上下文窗口堵塞,模型行为变得非确定性。冗长的、超详细的提示词是一个信号,表明底层架构缺失——而不是解决方案。
Token成本是真实的。 同时加载全局工程标准、历史架构上下文、Figma矢量模式和OpenAPI验证规则会产生爆炸性的token足迹。直到我停止从头重新生成整个管道并构建有针对性的差异更新范围,框架才变得在经济上可行。
完全自治是一个危险的目标。 AI在结构化元数据、强制执行代码规范和维持可追溯性方面非常有效。它在导航组织政治、解决冲突的利益相关者优先级、挑战有缺陷的假设、或在不确定环境中做出微妙的权衡方面,从根本上是无能为力的。
每个管道节点之间的审批门是不可谈判的。架构需要人工审查。契约需要工程签字。实现决策需要人类拥有权。框架加速决策。它不替代人类判断。
8. 下一步走向哪里
当前框架是一个基础。前方有三个清晰的视野:
- 架构感知的代码合成——从实现计划转向实际生成。有了完美无歧义的上游上下文,第一次尝试就能生成匹配组织风格的生产就绪代码块变得可实现。
- 自动化影响分析——使用依赖图进行结构性预测检查。后端领域模型的更改应该在提交被推送之前自动追溯到API端点、前端屏幕和测试场景的影响。
- 持续依赖跟踪——将活跃的代码更改桥接回上游规范,以便热修复更改自动纠正文档以维持完全对齐。
9. 结论:做出更少的不一致决策
企业软件工程中最难的问题几乎从来不是纯技术的——它们是对齐问题。再多的快速代码生成也无法弥补模糊的需求。
将AI集成到SDLC中的最大价值不是教模型以极速速度输出语法。真正的机会在上游:使用智能编排来构建一个清晰的、可追溯的、严格治理的交付制品管道。
软件工程的未来不是AI简单地写更多代码的世界。而是一个AI帮助团队做出更少的不一致决策的世界。
通过将AI从本地化的代码生成助手转变为受治理的交付编排伙伴,我们终于可以停止优化打字速度——开始优化工程质量。
原文链接: AI-Driven SDLC: Beyond Code Generation to Delivery Orchestration
汇智网翻译整理,转载请标明出处
