Anthropic Outcomes
Outcomes 是一个harness实践的代码化。有趣的问题不是它做什么。而是为什么 Anthropic 决定现在将这个实践作为 API 端点发布。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
你以前写过这个循环。十八个月前,当你第一次将 Claude agent 投入生产时,你写了一个评分标准。你写了一个评分器。你写了当评分器说"不通过"时的重试逻辑。这些组件会出问题。你修补它们。评分标准会漂移。你重写它。
5 月 6 日在 Code with Claude 旧金山大会上,Anthropic 将你的循环作为一个 API 端点发布,并称之为 Outcomes。
这就是新闻。其下的故事更大。Outcomes 是 Anthropic 决定出售的第一个 harness 层。Dreams、Multi-Agent 和 Webhooks 是在记忆、编排和生命周期上的相同举措。harness 过去是你写的代码。它正在成为一个你组合的产品栈。
1、Outcomes 实际上是什么
Anthropic 在 5 月 6 日向 Managed Agents 发布了四样东西。三个是公开测试版:Outcomes、Multi-Agent 编排和 Webhooks。一个是研究预览:Dreams。那天没有新模型。Dario Amodei 在主题演讲中直接说:"今天没有新模型。今天是关于我们如何让我们的产品更好地为你工作。"
媒体挑选了主打功能,即 Dreams。在会话之间整合记忆的 agent,命名为唤起人类睡眠,以 Harvey 的六倍完成率改进来支撑演示。它获得了头条。它值得。但在同一版本中架构上最重要的功能是 Outcomes,从表面上看它并不起眼。你写一个评分标准。agent 工作。一个评分器对工作进行评分。如果未达标,agent 再试一次。
对于任何发布过严肃 agent 的团队来说,这是五百行代码。对于所有使用 Managed Agents 的人来说,这是四行 API。
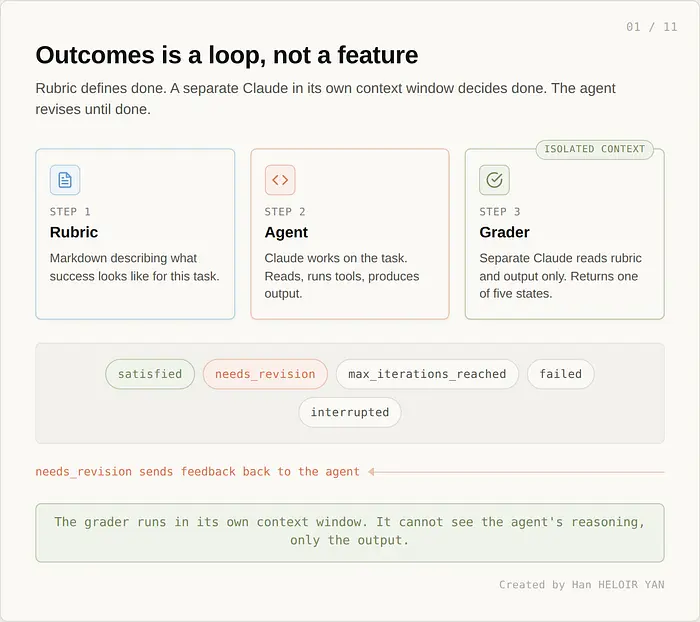
评分标准是一个 markdown 文档。你描述成功是什么样的。agent 做工作。当 agent 认为完成时,一个单独的 Claude 实例接收输出,阅读你的评分标准,并返回五种终态之一。
五种状态是:satisfied(发布它)、needs_revision(这里是要修改的内容,再来一次)、max_iterations_reached(你用完了尝试次数)、failed(评分器无法评估)和 interrupted(有什么东西终止了运行)。
值得停顿的部分是分离。评分器在自己的上下文窗口中运行。它看不到 agent 的推理过程。它看不到 agent 为产生输出而采取的工具调用链。它只阅读评分标准和输出。这是故意的。如果评分器能看到 agent 的思维链,它会被偏见引导说"通过"。agent 的推理是令人信服的。输出本身通常不是。评估准确性取决于隔离。所以 Anthropic 进行了隔离。
循环默认运行最多三次。最大值是二十次。你可以编写评分标准在每次通过时放宽或收紧。Outcomes 自 5 月 6 日起公开测试版,测试版标头为 managed-agents-2026-04-01。不需要单独的访问请求,与 Dreams 不同。
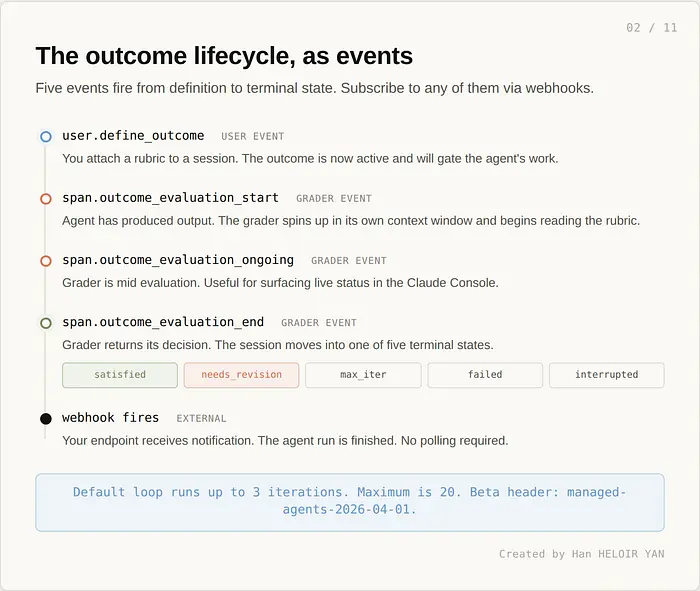
这是抽象视图。在实践中,一个真实的 outcome 运行会发出比五种更多的事件,包括 agent 的工作消息和每次迭代的新评分器 span。两次迭代版本看起来像这样:
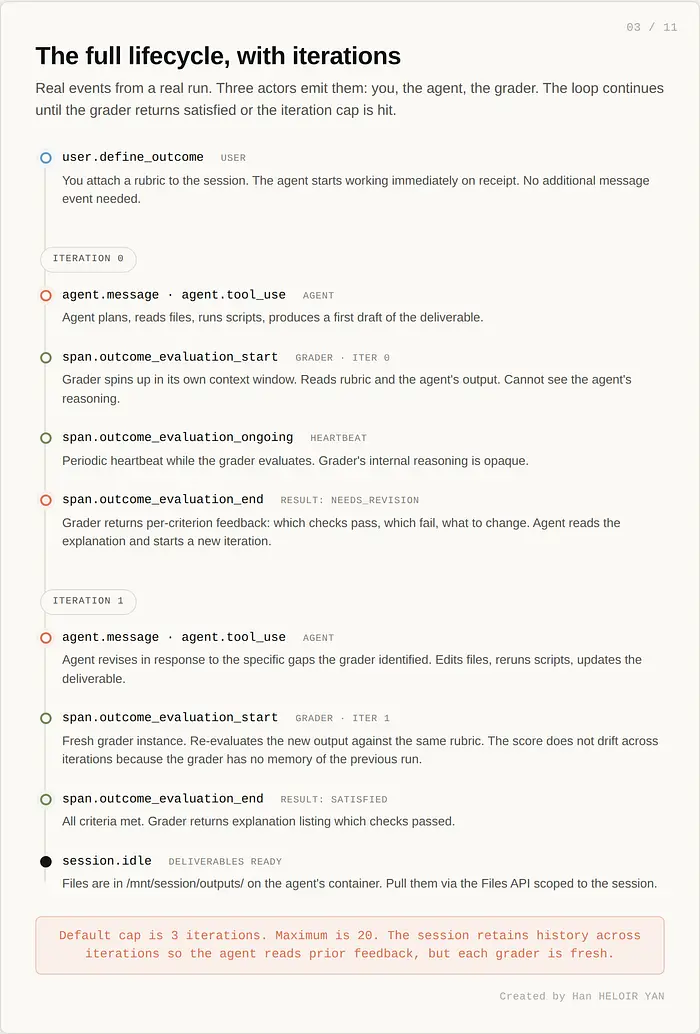
Anthropic 发布了两组数字。首先是内部基准测试:Outcomes 与标准提示相比将任务成功率提高了十个百分点。这种增益在难题上最大,即单次通过 Claude 会遗漏某些微妙之处的那些。特别是在结构化文件生成上,docx 输出的成功率提高了 8.4%,pptx 提高了 10.1%。这些是注意力细节最重要的工作负载:评分标准可以编码通用提示会遗漏的格式规则。
其次是客户数字。Wisedocs 使用 Outcomes 根据内部指南审查文档。审查现在快了 50%,同时与团队标准保持一致。这 50% 不是更快的 Claude。而是 Wisedocs 否则需要维护的脆弱 harness 的缺失。Spiral by Every 将 Outcomes 与 Multi-Agent 结合使用:一个主 agent 接收写作请求,子 agent 生成并行草稿,Outcomes 根据编辑原则和用户的声音对每份草稿进行评分。agent 发布得分最高的草稿。Spiral 通过 API 和 CLI 提供这个功能,已产品化。
这些看起来都不像新技术。评估者和工作者是每个运行生产 agent 的团队两年来一直在手写的相同模式。这就是重点。Outcomes 是一个实践的代码化。有趣的问题不是它做什么。而是为什么 Anthropic 决定现在将这个实践作为 API 端点发布。
2、一直存在于 Anthropic 工程博客中的模式
这个模式并不新鲜。Outcomes 是 Anthropic 十七个月前发布的工作的代码化。
2024 年 12 月,Anthropic 的 Erik Schluntz 和 Barry Zhang 发布了"Building Effective Agents"。文章描述了构建 agent 的五种工作流模式:提示链接、路由、并行化、编排器-子 agent,以及一个叫做评估器-优化器的模式。描述只有一句话:
"在评估器-优化器工作流中,一个 LLM 调用生成响应,另一个在循环中提供评估和反馈。"
读两遍这句话。然后阅读 Outcomes 文档。它是相同的架构。一个 Claude 生成输出。第二个 Claude 根据标准评估输出并提供结构化反馈。循环继续,直到评估器满意或达到最大迭代次数。Anthropic 发布了这个模式。Anthropic 在他们的 cookbook 中发布了一个 Jupyter notebook 参考实现。Spring AI 团队将其转化为一个名为 EvaluatorOptimizerWorkflow 的类。Hatchet 团队将其转化为 Icepick 中的一个工作流原语。CrewAI、LangGraph 和 DSPy 都支持某种变体。这个模式已在生产环境中运行十七个月,跨数千个团队。

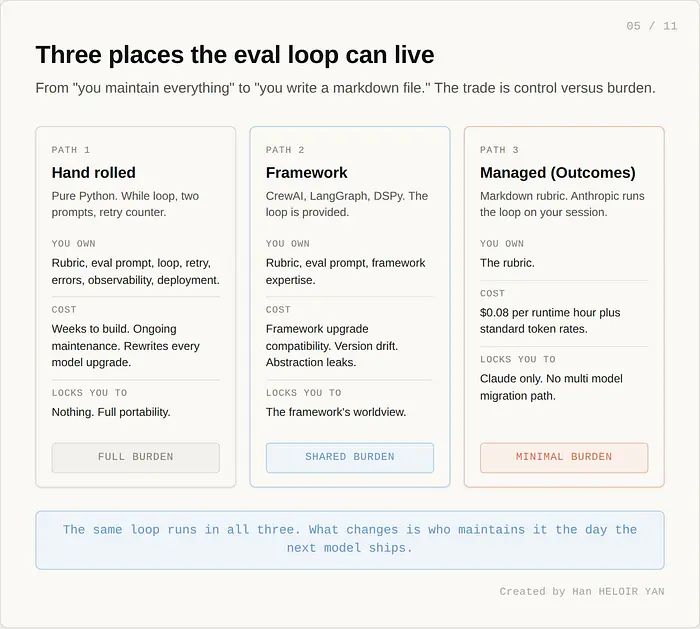
如果你自己实现过,这个配方很熟悉。你在代码或提示模板中定义一个评分标准。你将 agent 的主要任务包装在一个返回其输出的函数中。你写第二个提示,接收输出和评分标准,要求一个评估器实例对其进行评分,并返回批准或具体反馈。你将两者包装在一个带计数器的循环中,这样系统就不会永远旋转。你为评估器的结构化输出漂移添加错误处理。你添加可观测性,以便能看到循环在生产环境中为什么没有收敛。你发布它。六个月后你重写它,因为模型变得更聪明了,你的提示不再有效。十二个月后你重写它,因为团队中有人决定使用 Pydantic 而不是 JSON schemas。模式不是困难的部分。模式很好。维护才是困难的部分。
框架有帮助,但它们做不同的权衡。CrewAI 给你循环但将你耦合到框架的世界观。LangGraph 给你一个图运行时但你仍然写评分标准并拥有评估提示。每个框架承诺可移植性并以另一个名字发货锁定。它们都没有给你 Outcomes 给你的东西:一个运行在 Anthropic 基础设施上的 Claude 评分器,默认隔离,有管理的迭代限制和标准事件追踪,你唯一写的是 markdown 评分标准。
所以技术问题并不有趣。Anthropic 在销售他们自己十七个月前写过的模式。重要的是结构性问题:为什么评估器-优化器是第一个从博客文章毕业为 SKU 的模式?为什么不是提示链接?为什么不是路由?为什么验证是 Anthropic 决定首先捕获为托管产品的层?
答案不在 Outcomes 文档中。答案在另一篇 Anthropic 工程帖子中,在 Code with Claude 前一个月发布,几乎没有人读过。
3、为什么 Outcomes 能够发布
5 月 6 日的公告不是路线图。它们是对 Anthropic 在 4 月完成的架构工作的税收。
4 月 8 日,Anthropic 发布了一篇工程帖子,题为"Scaling Managed Agents: Decoupling the brain from the hands"。几乎没有 Anthropic 之外的人链接到它。这篇文章没有宣布一个功能。它宣布了一次重建。这是唯一解释为什么 Outcomes、Dreams、Multi-Agent 和 Webhooks 都在同一个月后发布的文档。
文章描述了 Managed Agents 如何围绕三个原语重建。
第一个是 session(会话)。一个只追加的事件日志。你通过 getEvents() 读取它。harness 通过 emitEvent() 写入它。工具调用、工具结果、模型响应、用户消息、配置变更,所有这些通过 session。session 是持久的。如果一个进程在任务期间崩溃,session 不会。你可以通过重放事件来恢复状态。
第二个是 brain(大脑)。Claude 本身加上调用 Claude 并路由 Claude 工具调用的 harness 循环。从 harness 的角度来看,brain 是有意无状态的。恢复是 wake(sessionId):启动一个新的大脑,把 session 交给它,让它从上一个大脑停止的地方继续。大脑不知道 session 没有记录的任何东西。
第三个是 hands(手)。代码实际执行的沙箱、MCP 服务器和工具。从大脑的角度来看,手是统一的:execute(name, input) → string。无论底层工具是代码解释器、浏览器、文件系统操作还是 MCP 连接的 SaaS,大脑调用相同的接口,手返回相同的形状。通过 provision({resources}) 进行供应,按需生成容器。
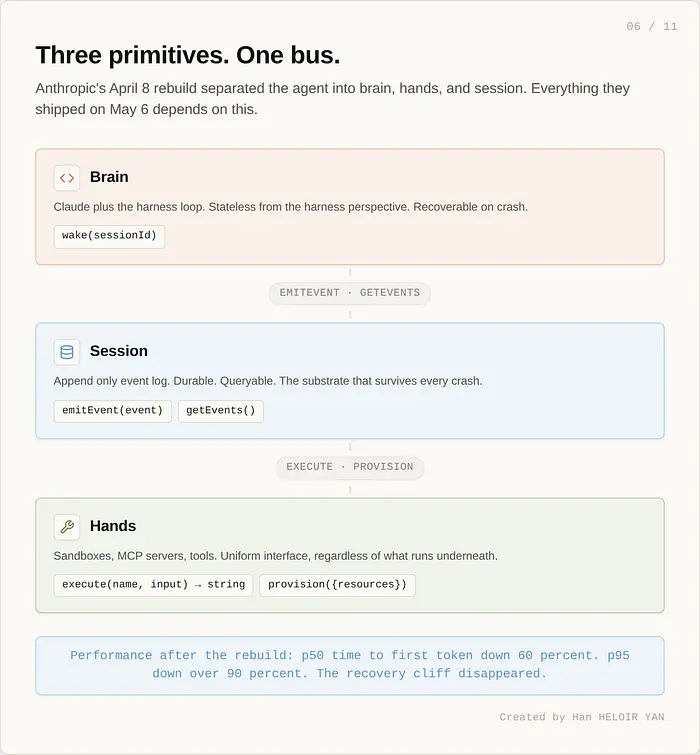
Anthropic 使用操作系统的类比来解释设计目标。他们回溯到 1970 年代。Unix 中的 read() 和 write() 系统调用在几十代硬件上运行,因为抽象处于正确的层级:在磁盘控制器之上,在应用程序之下。1975 年的程序仍然在 2026 年的硬件上运行,因为文件系统调用接口保持稳定。Anthropic 想为 agent 提供相同的属性。大脑、手和 session 接口被设计为比特定的 Claude 版本和特定的 harness 实现更持久。它们可能比 Claude Code 本身更持久。
重建发布了具体的性能数字。Anthropic 披露了首 token 时间改进:p50 下降了 60%。p95 下降了超过 90%。重要的是 p95:agent 运行出问题的长尾是用户感到痛苦的地方。通过将会话状态移到持久存储并使大脑无状态,Anthropic 消除了恢复悬崖。崩溃的 agent 现在在毫秒内重启。旧架构会丢失运行。
这是工程故事。以下是为什么它对 Outcomes 很重要。
在旧的耦合架构中,评估循环是你的问题,因为没有共享的基底来附加第二个评估器。你的 agent 的大脑将会话保存在内存中。你的工具调用发生在同一个进程中。要对输出进行评分,你在同一个代码路径中写了第二个提示,通过相同的 Claude API 运行它,并将结果路由回同一个循环。评分器不能是一个有自己上下文窗口的独立 Claude 实例,因为没有抽象能让两个大脑读取同一个会话而不冲突。
4 月 8 日的解耦改变了这一点。session 是持久的和可查询的。两个大脑可以读取同一个 session。一个大脑可以是工作者。一个隔离的大脑可以是评分器。
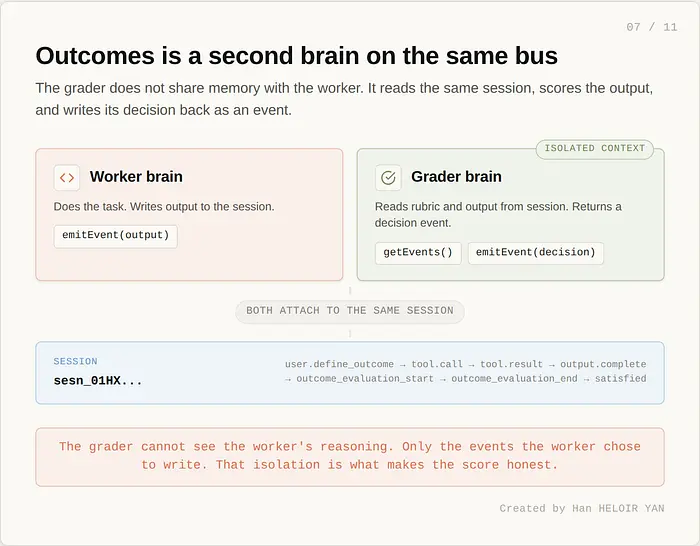
这就是 Outcomes 在机制上是什么。一个第二大脑连接到你的 session 日志,由你定义的评分标准控制。评分器从 session 读取工作者的输出,对其进行评分,并写回一个新事件。一直在等待的工作者大脑读取新事件并决定是否继续。整个循环在服务器端运行,因为基底现在支持它。
所以 5 月 6 日的公告不是路线图。路线图已经在 4 月 8 日发布了。5 月 6 日是税收:四个功能都依赖于相同的大脑、手和 session 解耦,每个捕获了以前你的代码中不同的一层。
4、验证层是第一个 SKU
Dreams 和 Multi-Agent 是相同的举措。
Harness 正在实时解绑。Anthropic 在 5 月 6 日发布的四个功能不是四个功能。它们是你以前的评估和编排代码的四层,每个都被提取到同一个大脑、手和 session 基底上的独立产品中。
验证首先发布。Outcomes 将评分标准评分转变为一个托管循环。你写 markdown。Anthropic 运行评分器大脑。基准测试数字(难题 +10pp,docx +8.4%,pptx +10.1%)和客户胜利(Wisedocs 快 50%,Spiral 并行草稿)锚定了它。自 5 月 6 日起公开测试版,不需要单独的访问请求。
记忆整理作为研究预览第二发布。Dreams 是一个调度的大脑,读取现有的记忆存储和最多 100 个过去的 session,然后写一个新的重新组织的记忆存储。输入永远不会被修改。你可以在梦想输出落地之前审查它,或让它自动应用。Dreams 运行 claude-opus-4-7 或 claude-sonnet-4-6,在单独的测试版标头 dreaming-2026-04-21 下发布。Harvey 报告说,一旦他们的 agent 开始在会话之间携带机构记忆,而不是每次运行重新学习文件类型变通方法,法律起草的完成率提高了六倍。架构意义:记忆整合变得异步和可审查,而不是即时写入的。企业可以在 agent 采用记忆更新之前审计它们。
编排第三发布。Multi-Agent 让一个主大脑委托给多达二十个并行的专家大脑,每个都有自己的上下文窗口。主大脑接收原始任务,拆分它,分发并聚合。Claude Console 显示每个子 agent 做了什么,所以工作保持可检查。Netflix 使用这个并行分析数百个构建源的日志,只浮现重复出现的模式。Spiral 将它与 Outcomes 结合:主 agent 接收写作简报,子 agent 生成并行草稿,Outcores 根据编辑标准对每份进行评分,主 agent 发布最好的。两个 harness 层干净地组合,因为它们共享一个基底。
生命周期钩子第四发布。Webhooks 让外部系统订阅 session 事件。你定义一个 outcome,agent 运行,你的端点在工作完成时接收通知。无需轮询。架构解读:session 日志现在是一个你可以接入的外部事件流。harness 不再是一个你从中捞取结果的黑盒。
这些中的每一个都曾是你的代码。评估循环是你的 while not satisfied 块。记忆整合是你每晚总结昨天 session 的 cron 作业。编排器是你的带有子进程调用的协调器脚本。Webhooks 是你的临时轮询。它们中没有一个是迷人的。它们都是结构性的。它们都在上游发生变化时每季度出问题。
5 月 6 日的发布命名了正在发生的事情:每个 harness 层正在成为一个单独购买的产品。你组合它们。你不构建它们。
这就是为什么 Outcomes 特别首先发布。在四个中,验证是最干净的可提取层。记忆有政策和审计复杂性。编排有成本控制复杂性。Webhooks 是基础设施,不是智能。验证是这样一层:基底的价值(一个不看你工作者推理的单独 Claude)最可见,失败模式最可量化。Anthropic 首先发布了具有最清晰独立价值的层,然后捆绑了其余部分。

累积效应不是新的定价。它是一种新的产品形态。看看 Anthropic 在过去十二个月中的工程投入在哪里。Claude Code、Claude Agent SDK、4 月 Managed Agents 发布、4 月 8 日的大脑/手/session 重建、5 月 6 日的层提取、十个作为 Cowork 插件、Code 插件和 Managed Agents cookbooks 一次性发布的金融 agent 模板。轨迹是一致的:agent 模板正在成为分发的单位,harness 正在成为其下方的基础设施。两年前,你从 Anthropic 购买的东西是一个模型。一年前,你购买的是模型和 SDK。今天,你购买的是一个围绕模型组合的 harness 层栈。明天,agent 模板可能比底下的 Claude 版本更重要。
这就是"Outcomes 是一个 SKU"的真正含义。不是一个功能有了价格标签。而是每个生产 agent 之下的层从你的代码库转移到了 Anthropic 的产品目录。
5、构建者应该停止写什么
正确的做法不是采用 Managed Agents。正确的做法是删除代码。
三个具体的减法,按杠杆排序。
停止写评估循环。开始写评分标准。 Outcomes 做循环、评分器、迭代上限、结构化反馈、重试逻辑、可观测性。你的工作变成在 markdown 中指定另一个 Claude 可以评分的成功标准。获胜的技能是精确的评分标准写作:明确的接受条件、清晰的拒绝条件、明确的边缘情况。这更接近产品规格写作,而不是工程。大多数团队会发现他们现有的评分标准足够模糊,评分器需要三次迭代才能收敛。这是你写更好评分标准的信号,而不是放弃功能。最低承诺:本周在一个 agent 任务上尝试 Outcomes。成本是运行时小时 $0.08 加上标准 token 费率。
停止构建记忆整合管道。开始调度 Dreams。 大多数运行跨越数小时或数天的 agent 的团队都有一个自制的记忆层,六个月后变成了负担。笔记堆积。昨天的调试见解与上周的架构决策矛盾。agent 最终要么淹没在过时的记忆中,要么每次重启都丢失上下文。Dreams 是人类大脑在 REM 睡眠期间做的定期清理,显式化。阅读过去的 session,提取模式,写一个新的重新组织的存储,保持输入不变。审计 trail 是真实的:企业可以在 agent 采用新记忆之前审查什么改变了。Dreams 仅限研究预览,所以你需要请求访问。代价是耐心:每个梦想周期需要几分钟到几十分钟,以标准 token 费率运行 claude-opus-4-7 或 claude-sonnet-4-6。
停止运行编排器。开始定义子 agent 规格。 如果你的 agent 已经协调并行工作,你有一个编排器。它可能使用 asyncio,有一个自定义调度表,并用自制的退避策略绕过模型速率限制。Multi-Agent 替换编排代码。你定义每个子 agent 做什么、它们如何连接、主 agent 聚合什么。每个 session 最多二十个并行专家。Console 给你每个 agent 的检查,这花了你三个冲刺在内部构建。约束:这是最有主见的层。你继承了 Anthropic 对多 agent 协调应该是什么样的看法。如果你现有的模式不同意,迁移更难。

诚实的权衡,说出来。
硬约束是模型。Managed Agents 只运行 Claude。没有路径通过这个 harness 运行 GPT 或 Gemini 或开源权重。如果你的栈今天是多模型的,或者你在 18 个月内可能需要这种灵活性,你在做不同的赌注。像 CrewAI 和 LangGraph 这样的框架让你切换提供商并在多云策略中存活。Outcomes 不行。这是让 Anthropic 承担维护的代价。
软约束是数据。Session、记忆存储、梦想和评分器上下文都存在于 Anthropic 的基础设施上。对于某些工作负载(受监管的金融、国防、医疗保健),这是一个交易破坏者。对于其他工作负载,SOC 2 和 ISO 立场以及 Claude Console 中的审计日志已经足够好。在大规模采用之前值得与你的合规团队验证。
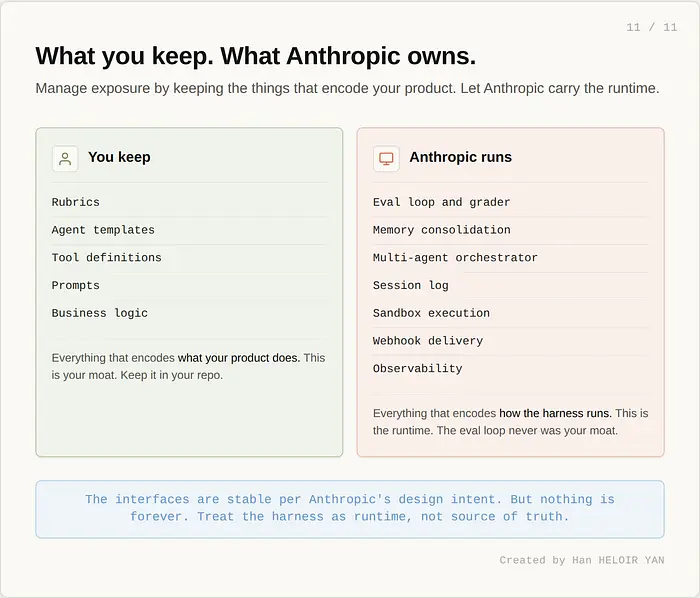
没有人标记的软约束是 API 表面。接口(define_outcome、getEvents、wake、provision)根据 Anthropic 的设计意图(工程帖子中的操作系统类比)是稳定的。但没有什么永远是。如果 Anthropic 在两年后重新绘制 harness 边界,你的迁移成本是真实的。通过将你的评分标准、agent 模板和工具定义保留在你自己的仓库中来管理暴露。把 Anthropic 的 harness 当作运行时,而不是真相的来源。
采用顺序,按杠杆除以承诺排序:
- 先 Outcomes。 最高杠杆,最低承诺。一个 markdown 文件加上 API 调用。你可以在单个工作流上试点并在一个下午内回滚。你节省的维护负担支付了你接受的约束。
- 其次 Dreams,当记忆腐烂是真实的时候。 不要预防性地采用。等到你的 agent 的记忆存储已成为已知负债,并且你有关于陈旧性成本的数据。然后调度一个梦想并在让它落地之前审查差异。
- 最后 Multi-Agent,在绿地工作负载上。 将现有编排器迁移到 Multi-Agent 是一次重写。最好将 Multi-Agent 用于一个新的 agent 系统,在其中你不需要撤销先前的架构决策。二十个并行 agent 的上限对大多数用途来说已经足够高,但要围绕它进行规划。
你应该在自己的代码中继续写什么:评分标准、agent 模板、工具定义、提示、业务逻辑。编码你的产品做什么的一切,而不是 harness 如何运行它。那些是你的护城河。评估循环从来不是。
原文链接:Anthropic Shipped Outcomes and Real Story Is Verification Becoming a SKU
汇智网翻译整理,转载请标明出处
