逃离 Token 税
opencode + ollama 才是王道。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我要告诉你妈。我要这么做了。你拦不住我。还有你,奶奶,也一样。我现在就给他们打电话,就现在。你是个瘾君子,你得停下来。总得有人阻止你。那就让我来吧。
一开始是无害的吧?
但现在情况变了,你迷上了那种感觉。他们把你牢牢抓住了。看看你自己。你应该感到羞愧。这些年你坐在 Macbook Tower 上,自认为是上帝赐予人类的编程天才,那些 LLM 一出现,你就被迷住了,Gastown 什么的,那些美味的 token 小点心。
再来点 token,兄弟,再来一点,你就能变成尼奥,进入黑客帝国了。

好了,说正经的,如果我有那么一点正经的话,有什么大不了的?为什么那些 token 成瘾者要叫屈,对着月亮嚎叫?
- 好吧,迹象就在那里;从 Fortune 到 LinkedIn 的人都在抱怨。
我还在想的是,为什么我们大家都没有预见到这一点。自从时间开始以来,在毒品和 AI 的营销中,还有什么比先让人上瘾,然后在价格上玩 bait and switch 更经典的吗?
见鬼,我甚至不知道价格上涨是否重要。我的意思是,如果 C 级高管们想要投资 AI,那么谁知道整个定价策略和涨价是不是件大事?船一旦启航,就很难掉头了。
如果你活在石头底下,不知道我在说什么,基本上就是……
The era of heavily subsidized, flat-rate AI pricing has ended as both GitHub Copilot
and Anthropic transition to token-based or usage-based billing.
Users are facing significant bill increases and credit depletion due to the
high token cost of long, autonomous coding tasks.
关于人们为什么对 token 价格产生疑虑,可能有多种因素。
- 成本
- 风险(一般性)
- 锁定
- 未来
- 良好的判断力
- 隐私
- 自由
那些曾经为摆脱"供应商锁定"和其他各种邪恶而自豪的领导者,正是那些最近一觉醒来发现他们的开发 token 成本/账单可能会飙升,现在正在哭喊的人。讽刺。
我的意思是,事后诸葛亮总是 20/20 的视力,但 figuring out 在某个时候会发生一些有趣的事情,这并不是什么火箭科学。一旦大众开始从 AI 的奶头中汲取,金钱说了算,你知道的。
另外,我不是说你要放弃,或者应该放弃像 CoPilot 或 Claude Code 这样的工具,因为你害怕,反应过度。有很多显而易见的、可行的方法来减少 token 使用,而且几乎不需要什么努力。
- 审查 CLAUDE.MD 文件和上下文
- 实现像 Caveman 这样的工具
- 提高提示词技巧
- 调整上下文
事实是,我对不可磨灭的人类精神充满信心。我们找到了大多数问题的解决方案,包括 AI token 最大化。每个人都很草率,因为我们被允许这样。如果我们"必须"更加审慎,我们能做到。
1、打破 token 监狱的开源替代方案。
话虽如此,在经典的白帽黑客、永不消亡的开源精神中……已经有一段时间了,有一股强烈的暗流想要完全控制,完全自由的控制。问题是,这能合理地实现吗?
- 我们能否找到可以在本地机器上运行的开源替代方案,提供合理的输出和性能?
大多数人不会为了给自己运行模型而去买一台 Mac mini。他们只会把钱付给 SaaS 大佬们,然后继续前进。还有其他重要的问题要问。
- 一旦我们习惯了 Claude Code 和 Anthropic 的速度(从提示到结果),我们能否通过任何本地设置达到或接近它们的速度?
- 几年前我们还手写代码。我们能有耐心等 30 秒到一分钟来获得回应吗?
某种感觉告诉我,在我们生活的 Instagram 和 Amazon 时代,一旦我们品尝过那 token 的果实在我们的数字舌尖上,就很难找到"足够好"的东西,而实际上它确实足够好。
代码或系统设计输出会满足我们的期望吗?它会比我们想要的慢 30 秒,相比之下感觉像过了几年吗?设置和安装是否过于繁琐?
尽管我很想往好的方面想,但事实是很容易预测人类的行为。
2、从 OpenCode 开始
那么,让我们开始这段可能漫长而孤独的通往 token 自由之路的旅程。就像古代的贝奥武夫一样,我们寻找新的土地,准备与新的怪物战斗。我不指望这次冒险没有心痛,但我确信我们会在旅途中有所收获。
- 首先,第一件事。
我要简化我的方法,把它分成两个不同的逻辑部分。
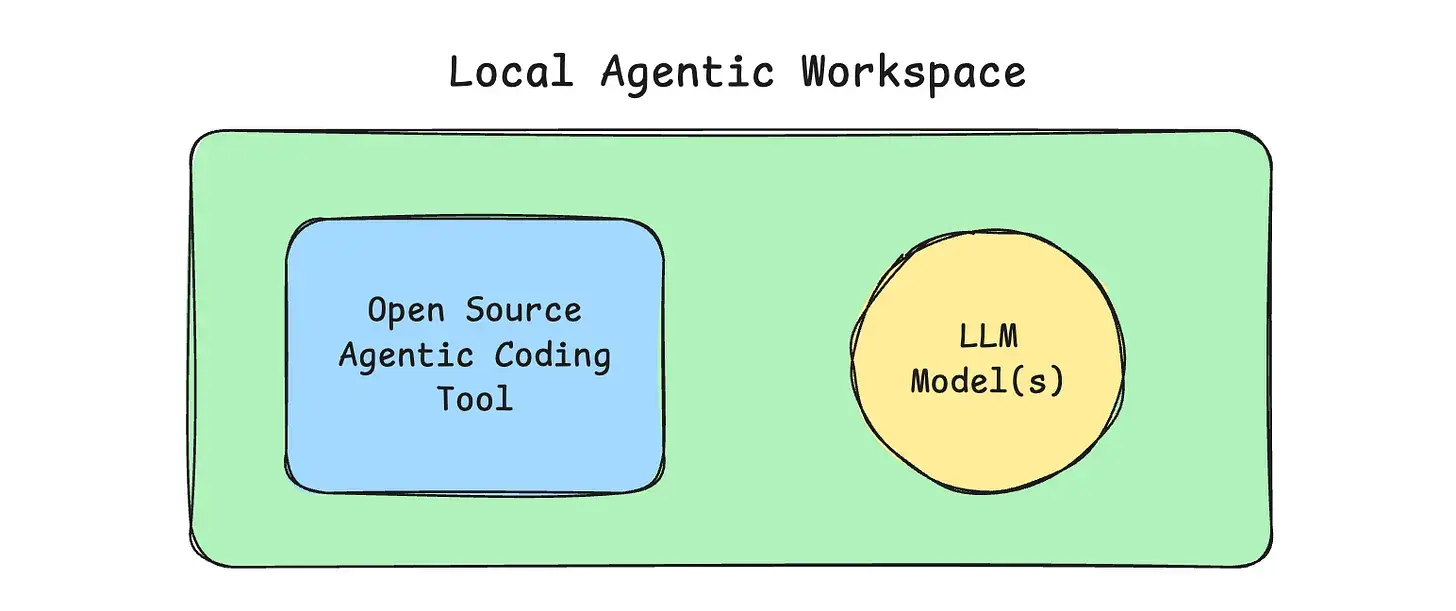
把它想象成你的 Claude Code 或 GitHub CoPilot 设置。你有一些在你的机器上交互的"智能体工具"。然后,你通过某个 API 使用来自 Anthropic、OpenAI 或其他公司的远程 LLM 模型……这两个部分结合起来,让你 Gastown 你的荣耀之路。
你可以使用你想要的任何东西,但让我们选择开源中的佼佼者,那就是 OpenCode。
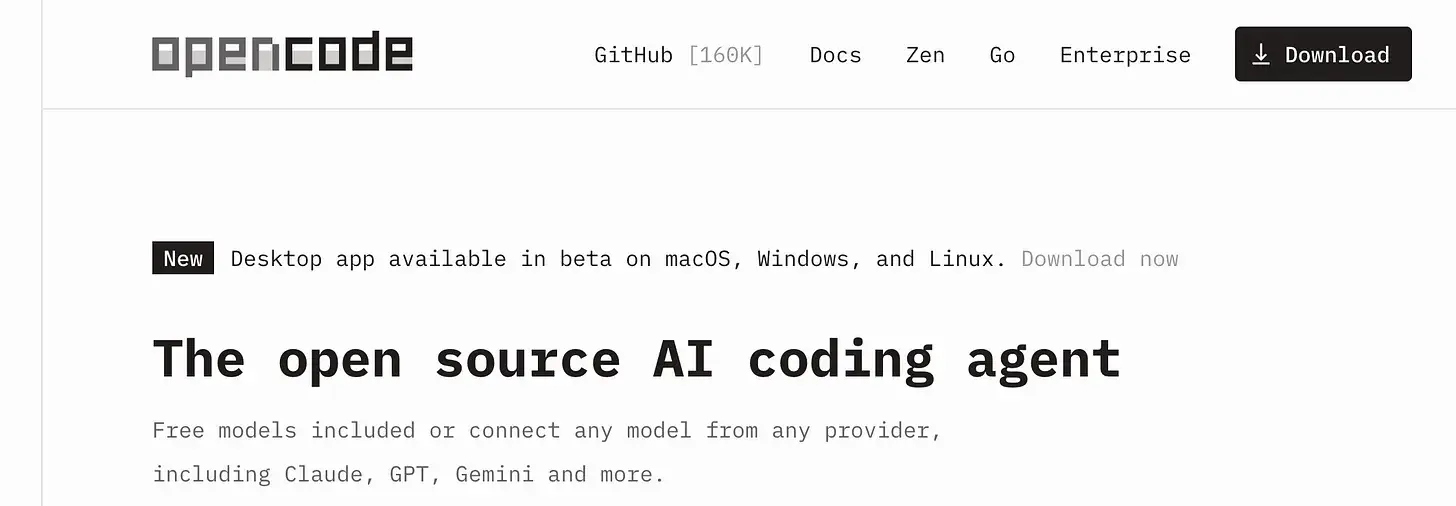
"什么是 OpenCode? OpenCode 是一个开源智能体,帮助你在终端、IDE 或桌面中编写代码。" - 来源
那么,让我们开始吧。足够简单。在这里找到适合你的安装说明。
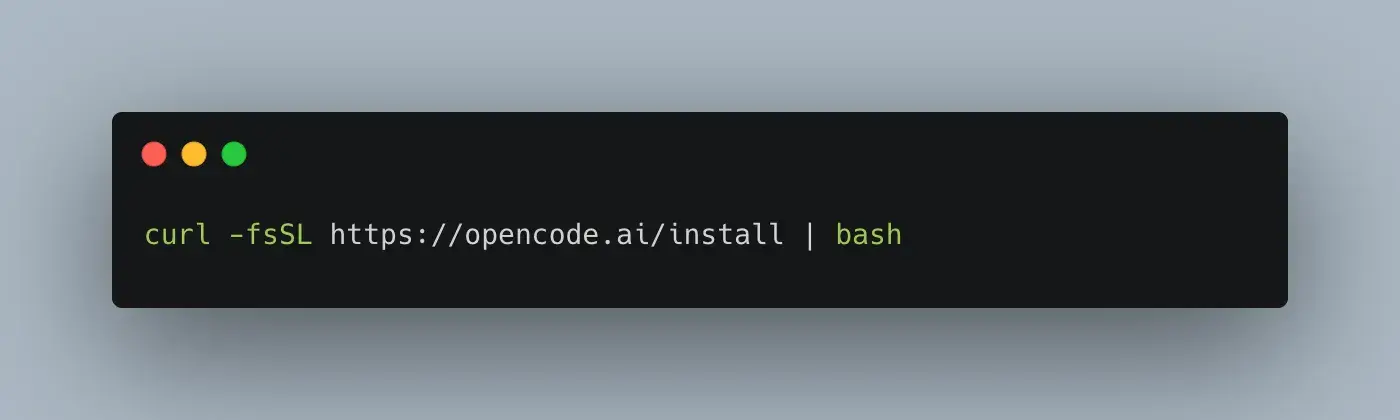
剩下的都很顺利,你可能会想为什么你一年前没这么做。
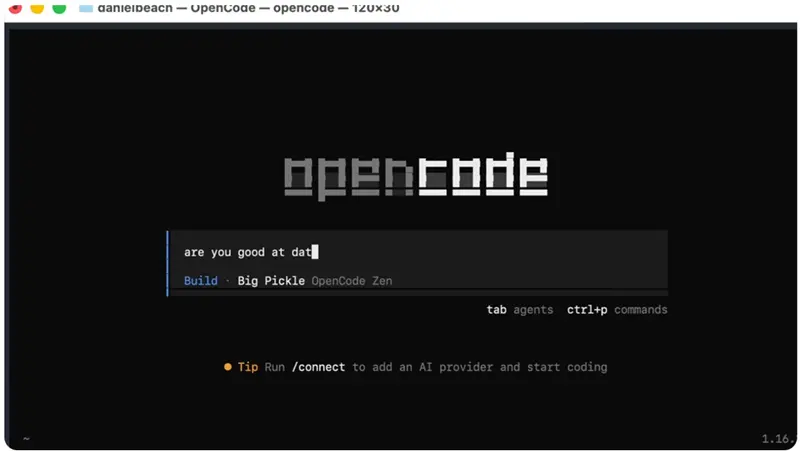
好吧,这在前面有点欺骗性。到目前为止,你只打了一半的仗。默认情况下,OpenCode 只会查看你的环境,找到它能找到的任何默认模型,你可能已经在使用的,比如 OPENAI_API_KEY、ANTHROPIC_API_KEY。
当然,我们现在正在使用一个开源的编码智能体/工具,但如果我们试图摆脱我们的 token 成瘾……那么我们仍然需要找到一个小的、可运行的本地模型来接入 OpenCode。
如果你想了解更多关于使用不同 LLM 与 OpenCode 的信息,你可以在这里阅读他们的文档。
3、用于编码任务的小型语言模型
进入兔子洞。什么洞?关于什么是最好的可以在本地使用的"小型语言模型"的无尽 Reddit 帖子的洞。这就是个性特征和人生观发挥作用的地方。
每个人都在做不同的任务,关心不同的事情,会因为各种原因发现某些模型比其他模型更好。
我不是来跳进这场关于哪个 SLM 最适合编码的辩论的。它一直在变化,而且会继续变化,希望随着时间的推移越来越好。很难与像 OpenAI 或 Anthropic 这样的公司竞争,它们背后有深层政府、大脚怪、外星人和数十亿美元。
所以,我想找到在基本编码任务中"足够好"的东西。想法是,在现实世界中,我们可以将这个设置与我们的 Token 大师们混合使用,比如说从 OpenCode 和一些 SLM 开始,完成繁重的工作,然后可能用 OpenAI 或 Anthropic 进行微调。
- 回到手头的问题,让我们选择一个 SLM 并将其连接到我们的本地 OpenCode。
好吧,在一个有点讽刺的命运转折中,曾经的"不作恶"的谷歌,据互联网说,将在这件事上拯救我们的培根。
"Gemma 是谷歌的免费开源小型语言模型 (SLMs) 家族。它们基于与 Gemini 大型语言模型 (LLMs) 家族相同的技术构建,被认为是 Gemini 的"轻量级"版本。" - 来源
碰巧那些小家伙们微调了一个特定于编码的版本。

所以,我想我们就试试这个 CodeGemma 7B,把它接入 OpenCode,然后让它跑起来。
这可能看起来有点奇怪,但将 CodeGemma 放到我们的本地机器上并运行的最简单方法是使用 Ollama。我过去用过很多次 Ollama。很容易获取。
ollama run codegemma
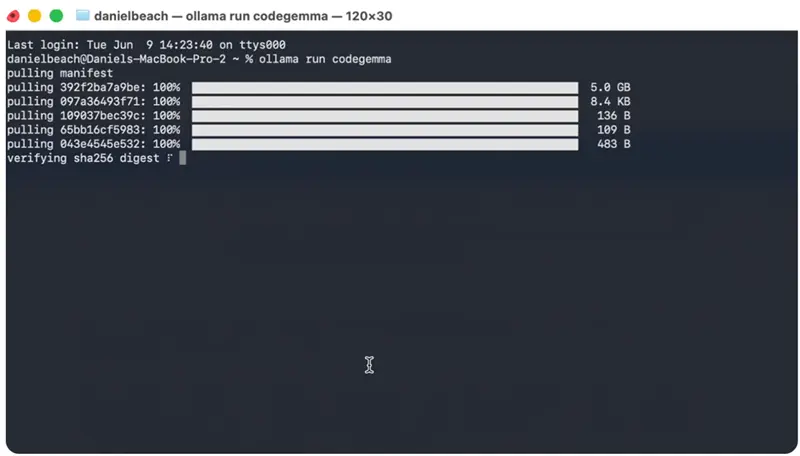
所以我们有了 CodeGemma 在我们的机器上,多亏了 Ollama。你不爱开源吗?现在我们可以希望配置我们的 OpenCode 来运行 CodeGemma,看看我们是流下喜悦的泪水还是悲伤的泪水。
- 接下来,我们需要一点 JSON 配置魔法来将我们的 OpenCode 指向我们的 Ollama Gemma 模型。有点拗口。
接下来,我们来做一点 vim 操作。
>> ~/.config/opencode/opencode.json
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"codegemma:7b": {
"name": "CodeGemma 7B"
}
}
}
},
"model": "ollama/codegemma:7b"
}
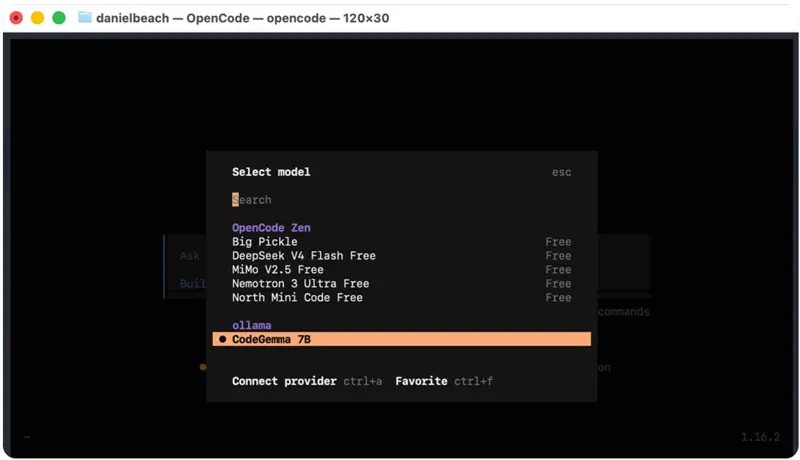
现在我们可以再次检查 OpenCode 正在使用什么模型。
opencode
/model
4、做一件事
好吧,我们今天完成了我们打算做的事。你感觉如何?自由?无政府状态?叛逆?富有?哇,一点点努力和逆流而上,我们已经从 token 贩子手中解放了自己。今晚最好睁着一只眼睛睡觉。
- 我的意思是,真正的问题是……它会表现如何?
情人眼里出西施。我不知道;也许它会太慢,或者只是产生糟糕的输出。也许它不能做特定的数据工程任务。我不知道。
让我们做点简单的事。
让它读取一个开源的 Divvy Bike Trip CSV 文件,并使用 DuckDB 或 Polars 做一些分析,也许是一个简单的 groupBy 和聚合。
我们开始吧。
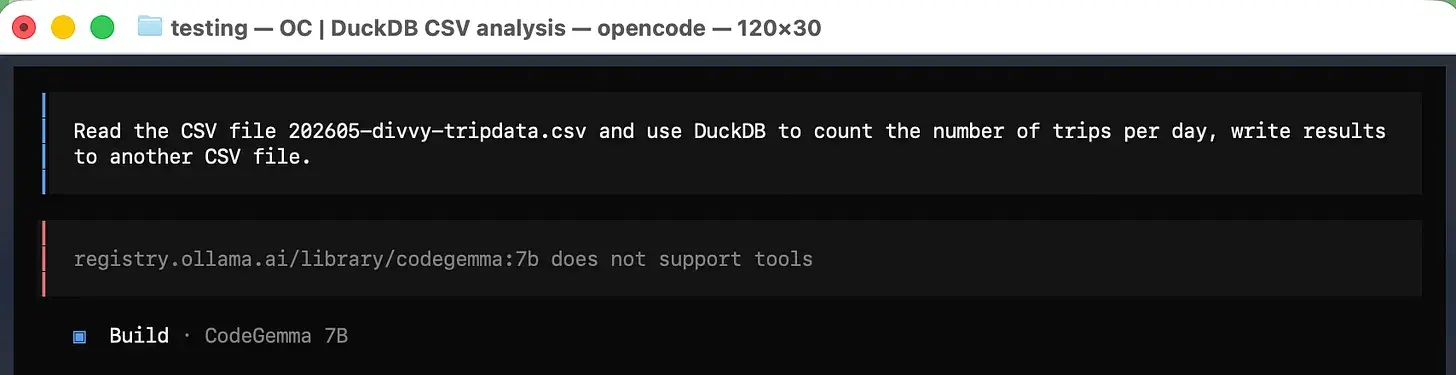
所以,我们正在学到一些东西:第一,我们可以立即失败;第二,显然,所有免费的开源模型并非生而平等。我不是运行本地模型的天才;显然,这个 GemmaCode 不支持工具调用,也就是说它没有暴露 OpenCode 集成所需的方法。
也许这是我们可以 figure out 和调整的东西,但是看,我是从一个原始人的角度来对待这个问题的。我想要一个任何人都能轻松搞定的简单设置。
- 不管怎样,我是吃玉米长大的中西部人,我不会轻易放弃。下一个模型。Qwen,我的爱。
ollama pull qwen2.5-coder:7b-instruct
当然,我们需要更新那个配置文件。
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"qwen2.5-coder:7b-instruct": {
"name": "Qwen 2.5 Coder 7B"
}
}
}
},
"model": "ollama/qwen2.5-coder:7b-instruct"
}
好的,让我们用 Qwen 再试一次那个数据管道。
Make a Python file that uses DuckDB to read the CSV file
202605-divvy-tripdata.csv, count the number of trips per day,
write results to another CSV file. So count the
column ride_id and group by started_at cast to a date.
然后我离开去和家人吃晚饭了。为什么不呢?这不是智能体编码的意义吗?你告诉智能体去做一件事,离开去做其他事,然后回来检查那件事?
我只知道当我吃完晚饭回来时,它还没完成。 ain't not Anthropic,早就告诉过你了。看,那个小混蛋正在燃烧我 30% 的 CPU。

我的意思是,我用的是我认为相当标准的 MacBook。

托尔的胡子怎么回事?33 分钟做那个任务。那不行,但如果你像 Tiny Tim 一样在街上为 token 奔波,时间就不那么重要了。
- 另外,我对工具和 OpenCode 了解多少?它实际上没有写文件。我只是把 Python 吐出来了。
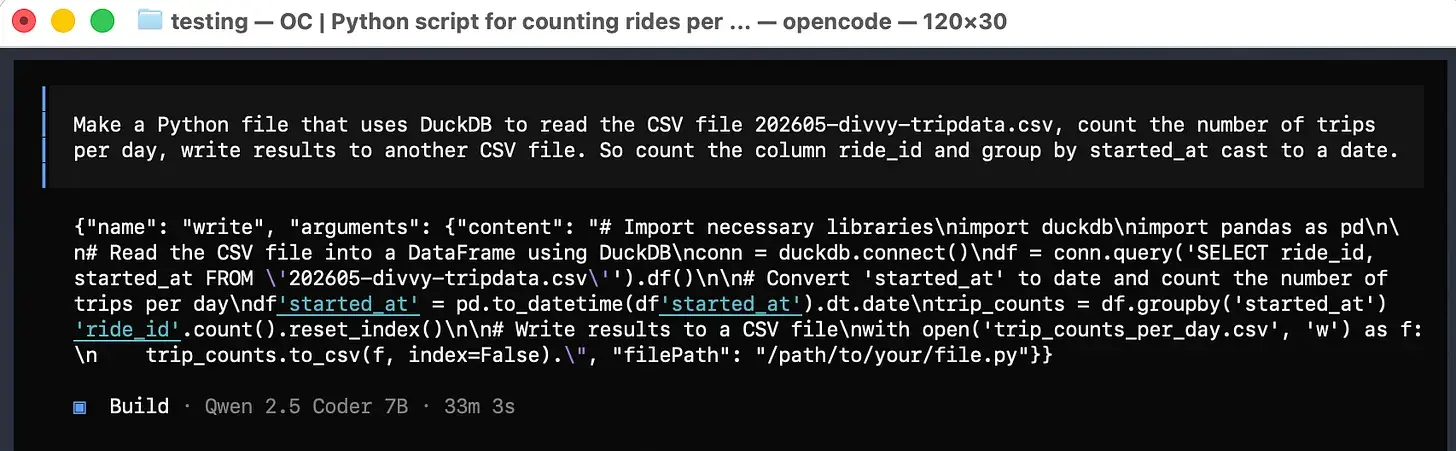
在我开始抱怨这一切有多糟糕之前,让我们看看这段代码是否真的有效。我们自己把它放到一个 Python 文件里运行。显然,它的工具调用能力,你可以看到它试图写一个 Python 文件……有点不稳定,也许你能搞定?
一开始,我就能看出它的 Python 技能有点差劲。
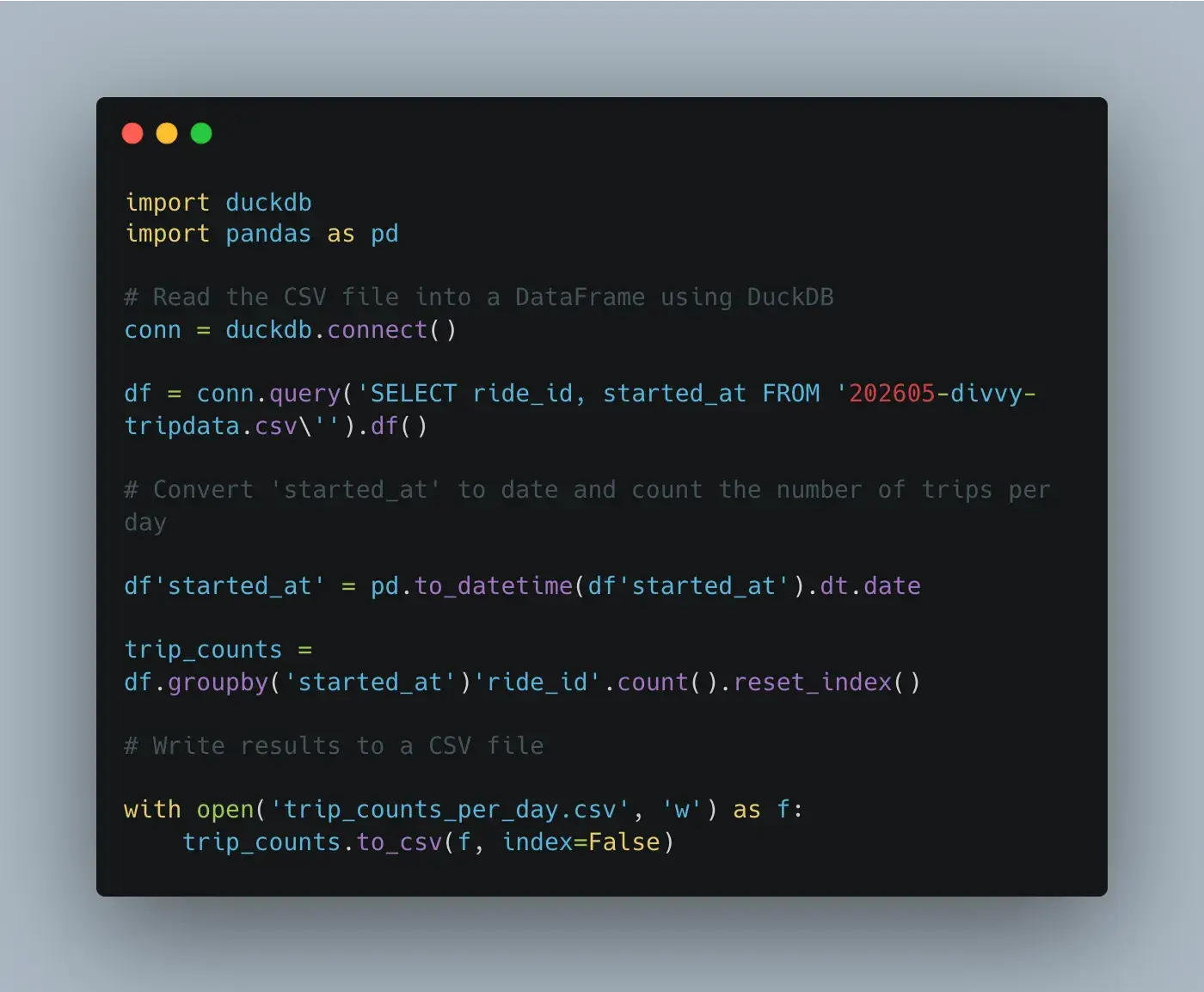
你奶奶总是唠叨的那句话怎么说来着?一分钱一分货??
- SQL 查询用了错误的 " 而不是 '
- df 列引用不正确,有几个地方需要 []
修复后的代码,我自己修复的,看起来像这样,运行良好,输出如我所要求。
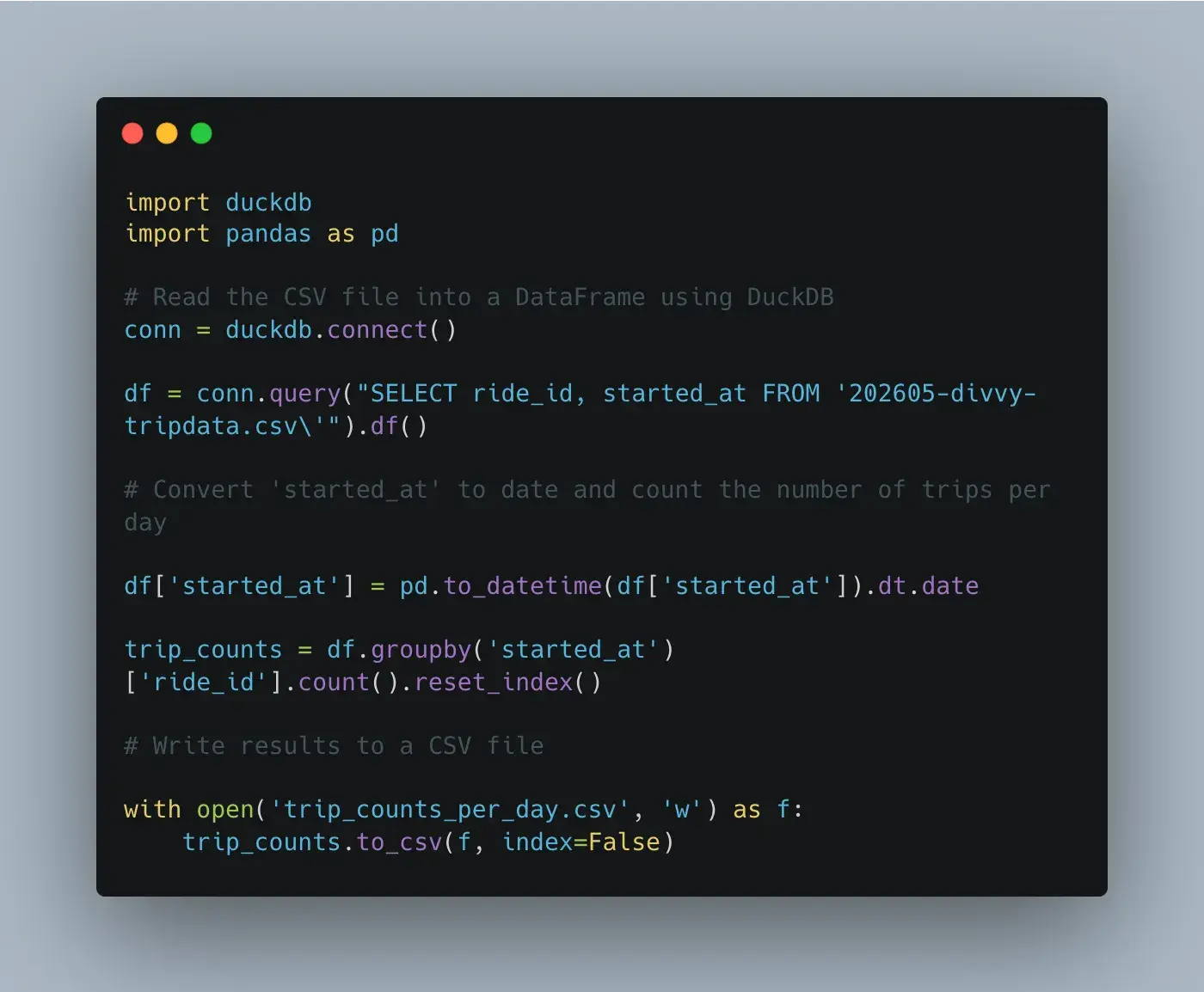
结果。
好吧,所以显然,虽然我的本地模型主要是,嗯,只使用 CPU 来解决这些问题,但这东西会爬得很慢。现在你知道为什么加密兄弟们多年来一直在订购 GPU 了。另外,你现在也知道为什么像 Claude Code 这样的东西,结合 Anthropic 模型通过 API 使用,是如此有吸引力,以及为什么那些公司……
- 雇佣聪明人
- 烧掉大量现金
- 把我们所有的地下水吸进数据中心
- 用掉我们所有的电
需要一些那种"勇气",就像我们这里说的,让你通过电线把大量上下文发送到全国各地,然后通过同一根电线……得到一个正确的答案。
5、所以……是的……
说实话,我正在失去勇气。别告诉任何人。就给我一篮子热乎乎的 token,让我啃 Claude Code。如果你想让我减少 token 成本,我就撒点 caveman 在上面,改进我的提示词,并剪掉这里那里隐藏的所有不必要的上下文。
给他们钱,给我 token。
看,我告诉过你什么?我想我们可以让一些东西工作起来,摆脱其他那些冲向 AI 悬崖的旅鼠。假装我们是叛逆者,运行我们自己的本地模型。
生活不是电影,你还没搞清楚吗?没有免费的午餐?也没听说过?
我敢肯定我有 16 件事做错了,会有人告诉我的;Reddit 的乌合之众可能会 figure out 的。你只需要在午夜时分在老橡树下与他们见面,用一根棍子蘸着血签下你的名字。谁知道呢。
- 更多硬件,更多 GPU,更好的配置,我不知道。
只要稍微 Google 一下,你就会明白我的意思。已经有一百万个 YouTube 视频和其他文章告诉你,他们已经破解了完美、敏捷模型的密码,表现最好。
祝你好运。
这是我想回头再做的事,也许在第二部分,做一点实验和研究,看看我们能否找到一个在像这样的 decent-sized 机器上给出好结果的模型。也许现在还不可能,谁知道呢。
是的,我知道我们可以用更多的 RAM、CPU、GPU 来解决很多计算问题……但我不仅想看看是否/可以摆脱 token 税,是的,这是可能的,但对于想要这样做的普通开发者来说,情况如何?
看起来没那么容易。是的,我没有花太多时间在上面,或者试图解决它,那可以以后再说,我只是想先试试水,看看这个世界为我准备了什么。
原文链接: Escaping the Agentic Token Tax: Replacing Claude Code or Copilot with OpenCode
汇智网翻译整理,转载请标明出处
