用 CocoIndex 构建实时上下文
CocoIndex为转换管道的每个步骤提供记忆,只重新处理文档中发生变化的部分。索引随源数据的变更保持最新,每段内容都可以追溯到产生它的完整步骤链。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
AI应用不是凭记忆回答问题的。它从你的文档中检索段落,将它们输入语言模型。模型基于这些段落进行推理并生成答案。答案的质量取决于它接收到的段落质量。当你问"苹果上季度披露了哪些网络安全风险?"时,系统必须从数千份SEC文件中找到正确的段落,而不是任何提到网络安全的段落。
在生产环境中,这种上下文会以三种方式失效。
一位合规官在SEC文件中搜索"GDPR合规"。系统返回关于"数据隐私法规"和"欧洲消费者保护"的段落。含义接近,但没有一段按名称提到GDPR。她将搜索范围缩小到过去一年的文件。系统无视了这个条件。向量没有时间的概念。
一家公司在周二撤回了一项风险披露。索引在周三、周四和周五仍然提供它。一位客户打来电话询问一个不再存在的风险。重新处理任务要到周日才运行。
一个AI回答泄露了一位客户的电话号码。团队将段落追溯至源文件,但文件已被清洗。是清洗器的正则表达式遗漏了这种格式,还是分块器将区号与号码拆开了?系统丢弃了所有中间结果。无人能判断。
CocoIndex和VeloDB构成了一个双层上下文栈,解决了以上三个问题。
1、CocoIndex + VeloDB的架构
架构分为两层。CocoIndex是托管上下文层:它拥有转换管道,跟踪变更,决定重新处理什么,并记录每个输出是如何产生的。VeloDB是检索层:它存储结果,跨所有信号类型建立索引,并实时提供查询服务。
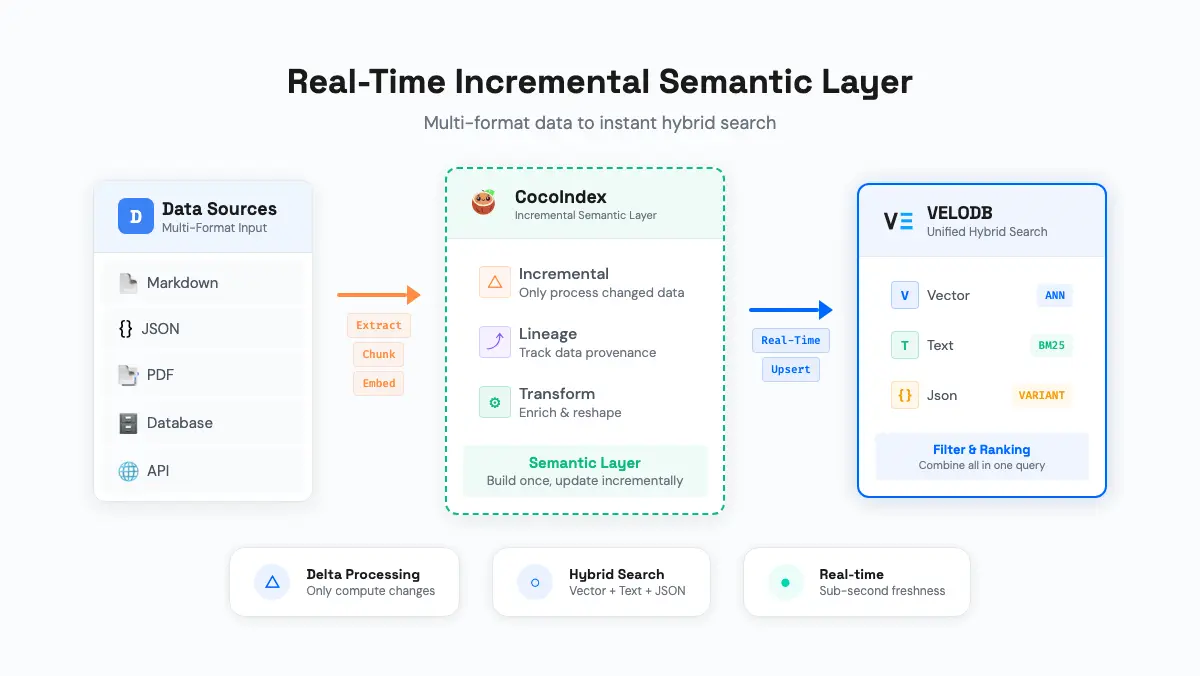
这两层通过三项能力解决了三种失效问题。
在一次查询中结合关键词、日期和类别搜索。 VeloDB在单次SQL过程中评估语义相似性、关键词匹配、结构化过滤和JSON路径查询。所有信号一起排名,而非事后合并。搜索"过去一年文件文档中的GDPR合规",得到的就是精确结果,而不是近似的语义匹配。
上下文在几秒内更新,而非几天。 CocoIndex为转换管道提供每步记忆:每步的输入和输出与函数逻辑的指纹一起存储。只重新处理变更的文档。只重新运行受影响的步骤。Doris接收增量数据并在一秒内使其可查询。
逐步追溯任何段落到其来源。 同样的每步记忆将每次转换的输入和输出记录为管道的结构属性。当某个段落返回意外结果时,沿链向后追溯:嵌入、分块、清洗文本、原始来源。CocoInsight使其可视化:点击任意字段,以蓝色查看上游依赖,以绿色查看下游输出。
每项能力在底层是如何工作的?
2、任意规模下按语义、关键词、日期和类别查询
向量搜索仅捕获精确查询所需四种信号中的一种。嵌入将段落转换为代表其大致含义的数字列表。相似主题产生相似的数字。
一个384维向量可以捕获某段内容涉及"监管合规"。它不会分别编码该段落具体提到"GDPR"、它是2024年提交的、或它被归类为风险披露。数字空间将所有这些细节扁平化为与一般主题相同的表示。
这种限制超越了关键词:合规官需要过去一年的结果,但向量没有时间的概念;研究人员需要风险披露而非收益讨论,但两者产生相似的向量。
一个引擎必须在单次检索中一起评估所有信号。VeloDB就是那个引擎。
典型的替代方案是将向量数据库链接到搜索引擎再到关系存储,由应用代码合并结果。
VeloDB消除了那个集成层。作为HSAP系统(混合搜索分析处理),它在相同的段文件中存储向量、倒排索引和列式数据,共享预写日志、段构建器和刷写操作。搜索不是附加到分析数据库上的独立系统。它是在查询执行期间评估的原生SQL谓词。
对"过去一年文件文档中的网络安全风险"的查询变成一条SQL语句:
WITH
semantic AS (
SELECT chunk_id, text, filing_date,
ROW_NUMBER() OVER (
ORDER BY l2_distance(embedding, @query_vector)
) AS sem_rank
FROM filing_chunks
WHERE filing_date > DATE_SUB(NOW(), INTERVAL 12 MONTH)
AND source_type = 'filing'
AND json_contains(topics, '"RISK:CYBER"')
LIMIT 100
),
lexical AS (
SELECT chunk_id,
ROW_NUMBER() OVER (
ORDER BY SCORE() DESC
) AS lex_rank
FROM filing_chunks
WHERE text MATCH_ANY 'cybersecurity risks breach'
AND filing_date > DATE_SUB(NOW(), INTERVAL 12 MONTH)
AND source_type = 'filing'
AND json_contains(topics, '"RISK:CYBER"')
LIMIT 100
)
SELECT s.chunk_id, s.text, s.filing_date,
1.0/(60 + s.sem_rank) + 1.0/(60 + l.lex_rank) AS rrf_score
FROM semantic s JOIN lexical l ON s.chunk_id = l.chunk_id
ORDER BY rrf_score DESC
LIMIT 20;
1/(60 + rank)公式是倒数排名融合(RRF),一种合并两个排名的方法,不需要可比的分数。在语义相关性和关键词出现两方面都排名靠前的文档会上升到顶部。无需调整权重。
每个WHERE子句解决了仅靠向量搜索无法填补的空白。
MATCH_ANY按名称查找提到"cybersecurity"的段落,而非仅语义相关的段落。filing_date > ...将范围限制在过去一年。
source_type = 'filing'排除JSON元数据和PDF附件。
json_contains(topics, '"RISK:CYBER"')筛选在摄取期间被标记为网络安全风险的分块。四种信号类型,一个引擎,一次排名。
这条查询对一张表评估四种信号。当该表有十亿行时会发生什么?
对于具有深度嵌套数据的应用,VeloDB提供了VARIANT类型。JSON字段会自动提取为列式子列。像user.id这样的路径变成独立的BIGINT列,而稀疏字段保持压缩的二进制格式。这使得JSON分析速度比MongoDB快160倍,比PostgreSQL快1000倍,无需单独的扁平化管道。
在生产规模下,问题从"混合搜索是否有效?"转向"它能否扩展到我的数据规模?"字节跳动在十亿级向量搜索中面临了这个挑战。他们为十亿个768维向量建立的HNSW索引最初需要大约10TB内存,分布在20到30台服务器上。使用IVPQ压缩(倒排文件+乘积量化),他们将内存减少到单台服务器的500GB,内存减少了20倍,同时保持92%的召回率和400ms的p95延迟。
查询和摄取性能同步扩展。VeloDB在百万级向量基准测试中实现了超过97%召回率的989 QPS,并维持10 GB/s的摄取吞吐量,写入到查询的延迟在亚秒级。跨集群节点的并行HNSW构建使摄取速度随表增长保持恒定:拥有1000万向量的表以与100万向量的表相同的速度摄取新批次。
VeloDB可以在不到一秒内摄取新数据,但这种速度只有在供给它的管道知道什么发生了变化时才有意义。这就是CocoIndex解决的问题。
3、变更文档在几秒内同步
为了更新几百个文档而重新处理整个语料库浪费了超过99%的计算。一个知识库有100,000份文档和大约200万个已索引段落。今天,200份文档发生了变化。管道重新处理所有100,000份。每份文档从第一步重新进入链。每个嵌入都重新生成。
高效的响应应该是精准的:只有200份变更的文档进入管道,在链内,只有输入发生变化的步骤重新运行。这需要每步记忆:记录每次转换在上次运行中生成了什么,以便系统可以将每步的当前输入与上次输入进行比较,决定是重新处理还是复用。
大多数管道不存储中间结果。它们从头到尾处理文档,丢弃除最终输出之外的所有内容。没有每步记忆,成本与总语料库成正比,而不是与变化率成正比。团队每周重新处理。在两次运行之间,索引漂移。周二更新的文档返回周一的内容,直到周日运行。陈旧和成本相互强化,一个没有良好均衡的循环。
CocoIndex打破了这个循环。它将管道从无状态脚本转换为有状态系统。当文档发生变化时,只有该文档进入管道。在管道内,只有输入发生变化的步骤重新运行。200份变更的文档生成大约4,000个新嵌入,而不是200万个。计算成本与变化率成正比,索引在几分钟内更新。
CocoIndex通过缓存转换实现这一点。管道中的每个函数都用缓存指令装饰:
@cocoindex.op.function(cache=True, behavior_version=1)
def scrub_pii(text: str) -> str:
"""Remove personally identifiable information."""
# ... scrubbing logic ...
cache=True将函数的输出与其输入的指纹一起存储。在下一次运行中,如果输入没有变化,缓存的结果将被返回而无需重新执行函数。behavior_version跟踪逻辑本身。当你更改函数行为时,增加版本号,CocoIndex会自动重新计算所有受影响的输出。版本升级会触发该步骤和所有下游步骤的所有文档的重新处理——同样的定向重算,应用于逻辑变更而非数据变更。
这不是应用级缓存。它是内置于管道执行模型中的每步记忆。系统知道每次转换在上次运行中生成了什么,与当前输入进行比较,并做出精确决定:重新处理还是复用。
删除同样精确。当从仍然存在的文档中删除一个段落时,从该段落派生的分块从索引中消失,而文档其余部分的条目保留。CocoIndex的跟踪记录将每个索引条目映射回产生它的具体内容。没有孤立的向量。没有残留到下次运行的幽灵数据。
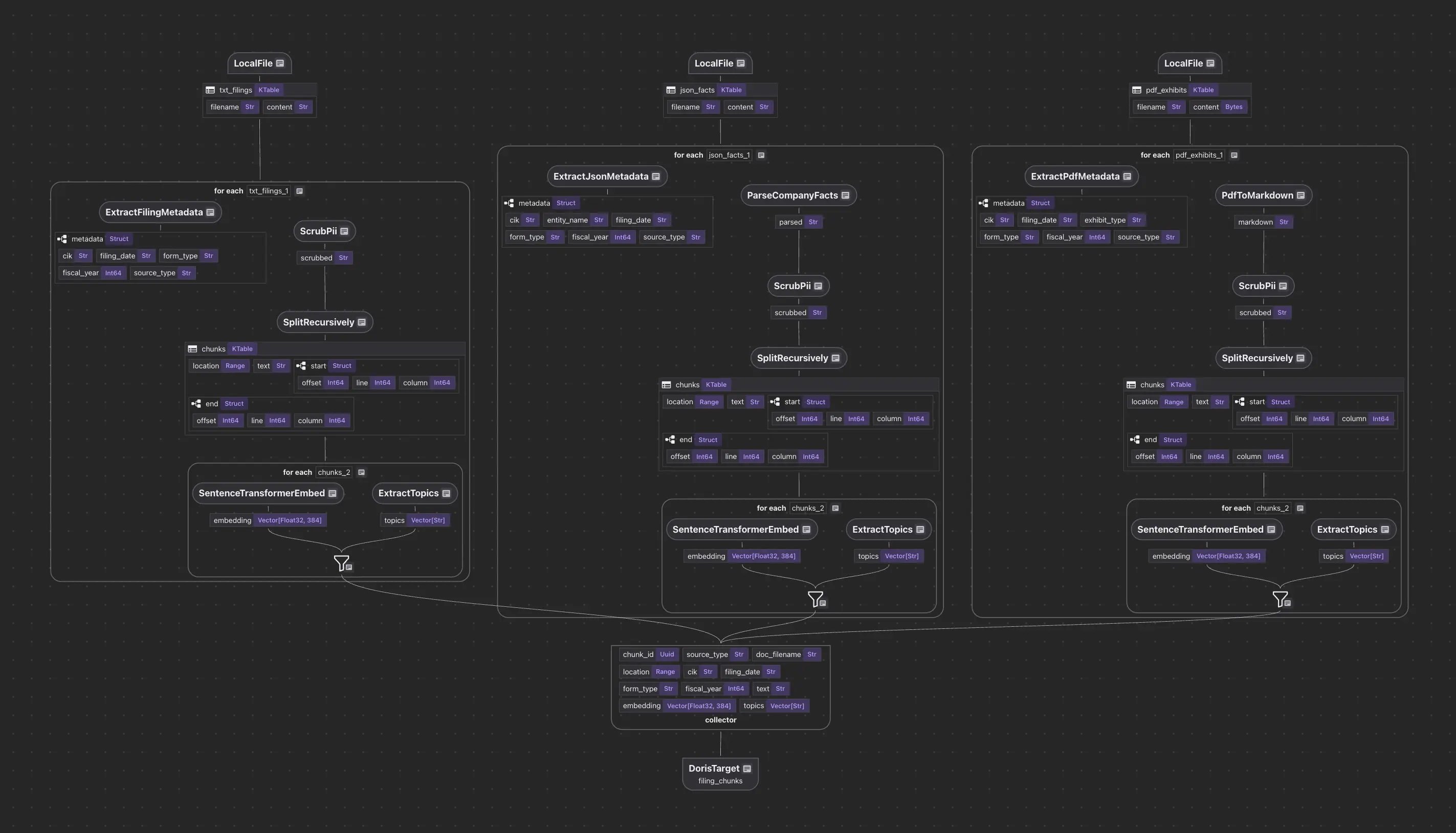
多源摄取通过统一的收集器模式工作。不同的数据格式(文本文件、JSON API、PDF)各有自己的源定义和解析逻辑,但都汇入一个写入目标的收集器:
@cocoindex.flow_def(name="SECFilingAnalytics")
def pipeline(flow_builder, data_scope):
# Sources
data_scope["filings"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="data/filings", included_patterns=["*.txt"])
)
data_scope["facts"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="data/company_facts", included_patterns=["*.json"])
)
# Single collector: all sources merge here
collector = data_scope.add_collector()
# TXT filings: extract metadata from filename, then process
with data_scope["filings"].row() as filing:
filing["metadata"] = filing["filename"].transform(extract_filing_metadata)
process_and_collect(filing, "content", filing["metadata"], collector)
# JSON facts: parse structured data into searchable text
with data_scope["facts"].row() as facts:
facts["metadata"] = facts["filename"].transform(
extract_json_metadata, content=facts["content"]
)
facts["parsed"] = facts["content"].transform(parse_company_facts)
process_and_collect(facts, "parsed", facts["metadata"], collector)
# Export to VeloDB
collector.export(
"filing_chunks",
DorisTarget(host=..., port=..., database=..., table=...),
primary_key_fields=["chunk_id"],
vector_indexes=[
cocoindex.VectorIndexDef(
field_name="embedding",
metric=cocoindex.VectorSimilarityMetric.L2_DISTANCE,
)
],
fts_indexes=[
cocoindex.FtsIndexDef(field_name="text", parameters={"parser": "unicode"})
],
)
每个源独立处理。收集器处理去重和目标管理。关于SEC EDGAR文件的完整工作示例,包括TXT、JSON和PDF摄取及四种搜索模式,请参见教程笔记本。
端到端路径关闭了陈旧循环。源文档发生变化。CocoIndex检测增量,只重新处理受影响的文档和步骤,在几分钟内生成新嵌入。VeloDB摄取这些嵌入并在不到一秒内使其可查询。新鲜度不再与成本交换。
增量更新保持索引最新,但也带来了一个新问题:当某个段落产生意外结果时,如何追溯到产生它的转换链?
4、通过塑造它的每个步骤追溯任何段落
索引中的段落不是源文档的副本。它是多次转换的最终产物:管道提取了文本、清洗了敏感数据、将文本拆分为分块、生成了嵌入并分配了主题。每一步都影响了最终结果。大多数管道不记录任何这些。源文件存在。最终段落存在。中间的一切都被计算后丢弃了。
当出现问题时,这很重要。一个段落包含未脱敏的电话号码。是清洗器的正则表达式没有匹配到这种格式,还是分块器将文本在区号和号码之间拆开了?没有中间输出,你无法判断。
当某些内容变化时同样重要:你改进了主题分类器,但没有记录哪个函数版本产生了每个段落的主题,你必须重新运行整个链来重新分类。管道没有存储供给分类步骤的中间输出。
每一步的输入和输出已被保留;启用增量更新的同样机制也支持调试。对于调试,这意味着任何输出字段都可以通过完整的转换链向后追溯:
embedding (384-dim vector)
← generated from: text chunk "We face significant cybersecurity risks..."
← split from: scrubbed content (PII removed)
← scrubbed from: raw filing text
← extracted from: 0000320193_2024-11-01_10-K.txt
CocoInsight使这种血缘关系可视化和交互化。界面呈现两个面板:右侧面板显示数据流图(每个转换步骤,通过数据依赖连接),左侧面板逐步骤、逐单元显示每步的实际值。
一个嵌入产生了意外的搜索结果。你在CocoInsight中点击嵌入字段。上游链以蓝色高亮:被嵌入的文本分块、它被拆分出的清洗文本、被提取出的原始来源。你检查每一步的实际数据。清洗器破坏了一个句子?你能看到。分块器在句子中间拆分了?你能看到。黑箱打开了。
CocoIndex的数据流模型通过设计强制执行这种可追溯性。每次转换仅从输入字段创建新字段,没有隐藏状态,没有值变更。血缘不是从日志重建的。它就是执行模型本身。
剩下的问题是何时采用这种架构,何时更简单的替代方案就足够了。
5、何时适合这种架构
你的上下文会过时,而新鲜度有后果。 大多数用例可以容忍夜间或每周重新处理。但当源数据每天变化且陈旧结果影响合规决策、临床查询或面向客户的答案时,运行间隔就成了产品中的缺陷。如果"索引过期"出现在过事故报告中,增量索引解决了根本原因。
搜索需要组合目前分散在不同系统中的能力。 你的应用需要语义理解、关键词精确度、日期过滤和结构化查询。目前实现这些意味着运行向量数据库、搜索引擎、关系存储和应用逻辑来合并结果。如果集成复杂性是搜索质量仍是已知限制的原因,那么一个处理所有四种信号的引擎可以使该能力成为现实。
你需要将错误答案追溯到其来源。 当某个段落产生错误结果时,必须有人确定是嵌入有误导性、分块边界错误,还是清洗器破坏了文本。如果你的调试过程今天是"重新运行管道并希望重现",转换血缘将猜测替换为从输出到来源的可点击链。
关于涵盖多格式SEC文件摄取、四种搜索模式(混合、词汇、主题过滤、投资组合比较)和行级访问控制的完整工作实现,请参见教程笔记本。
原文链接: The AI Context Stack: Real Time, Traceable and Open Context with VeloDB and CocoIndex
汇智网翻译整理,转载请标明出处
