智能体数据工程的崛起
每个数据团队在某个时刻都会撞上同一堵墙。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
在 2TB 规模下运行良好的管道,在 20TB 时开始出问题。上游的 schema 变更悄悄地破坏了下游的仪表板。有人打了个补丁。又一个作业失败了。又一个补丁。到季度末,半个团队都在维护没有人完全理解的工作流。
没有什么完全崩溃。但也没有什么感觉是稳定的。这就是传统 ETL 的真正问题。它不会大声失败。它安静地退化。在 2026 年,这是不可接受的。
1、传统 ETL 中的控制幻觉
多年来,ETL 给了团队一种结构感。提取、转换、加载。清晰的阶段。明确的所有权。可预测的管道。但那种结构只在可预测的环境中有效。
现代数据生态系统远非可预测:
- API 在没有通知的情况下变更
- 事件流不可预测地激增
- 数据格式在传输过程中演化
- 下游消费者要求近实时访问
传统 ETL 不是为这种波动性级别构建的。它假设稳定性、固定 schema、定时批处理和人工监督。
团队今天所谓的"管道管理"往往只是持续的救火。代价是技术债务,同时伴随着团队倦怠。
2、脆弱管道的隐性税
每个破损的管道都带来可见的成本——延迟、错过 SLA、不正确的报告。
但更深层的是运营成本:
- 工程师花在调试而不是构建上的夜晚
- 对部落知识的持续依赖
- 没有优先级的无休止警报
- 仅为了维护稳定性而扩充人员
在规模化的情况下,ETL 不再是基础设施,而是开销。这就是 ETL 现代化对话在 2026 年发生变化的地方。关键在于完全消除对管道的看管需求。
3、智能体数据工程带来了什么改变
改变不是从 ETL 到另一个工具。而是从静态管道到自适应系统。
数据工程中的智能体 AI 引入了不仅执行工作流、还会对工作流进行推理的系统。团队不再手动定义每个转换步骤,而是定义意图:
- 什么数据需要可用
- 必须满足什么质量阈值
- 哪些下游系统依赖它
系统自行计算如何达到目标,并在情况变化时进行调整。这不是传统意义上的自动化。这是有约束的自主性。
4、不再等待失败才行动的管道
最大的飞跃来自自愈数据管道。
在传统系统中,故障检测是被动的。一个作业失败,触发警报,有人去调查。在智能体系统中,故障是被预判的。
管道持续评估:
- 数据一致性模式
- Schema 漂移信号
- 延迟异常
- 依赖项健康状况
当出现偏差时,系统会标记并采取行动。
它可以:
- 通过备用路径重新路由数据
- 动态调整转换逻辑
- 隔离损坏的数据段
- 无需升级即可触发纠正工作流
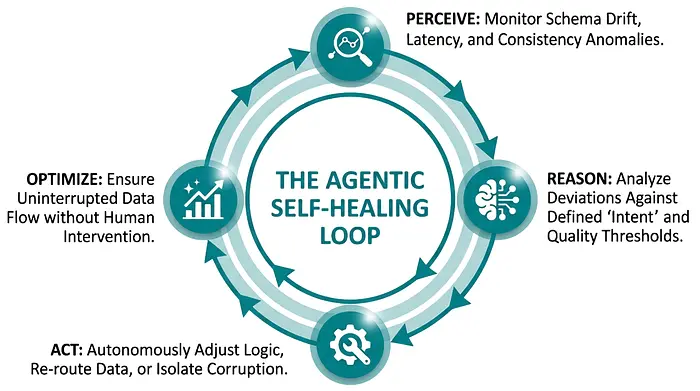
目标很简单:在不需要人工干预的情况下保持数据流动。更重要的是,数据团队不再生活在持续警报模式中。
5、从编排到自主决策
传统编排工具调度任务。它们定义依赖关系和执行顺序。当依赖关系变得流动时,这个模型就崩溃了。
自主数据编排消除了刚性排序。不再使用固定的 DAG,而是基于实时条件运作。
它可以判断:
- 现在需要运行什么
- 什么可以延迟而不产生影响
- 根据下游需求应该优先处理什么
执行变得自适应。
工作流不再是静态图表。它们是根据上下文调整的活系统。在数据不仅被处理而且跨多个层被即时消费的环境中,这是至关重要的。
6、生成式摄取改变了前门
大多数 ETL 讨论集中在转换上。但摄取才是复杂性的起点。不同的格式。不一致的结构。不完整的数据。不断变化的 API。
这就是生成式 AI 数据摄取发挥作用的地方。
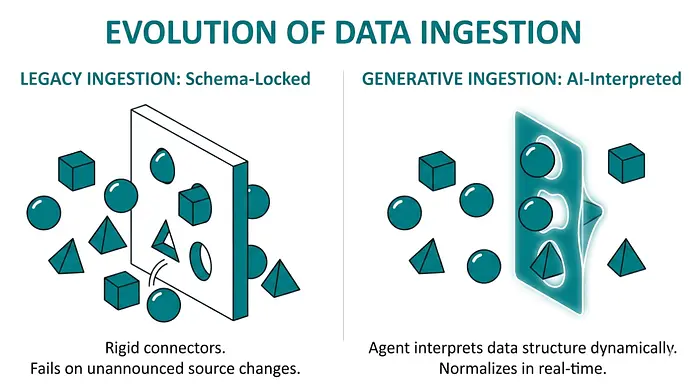
智能体系统不再使用刚性连接器和预定义映射,而是解释传入的数据:
- 即使没有文档也能理解结构
- 动态生成转换逻辑
- 无需预定义 schema 即可标准化数据
这减少了接入新数据源的摩擦。团队不再花几周时间编写摄取管道。系统实时适应。这改变了组织对新数据机会的响应速度。
7、无摩擦地构建 AI 就绪的数据基础
所有这些都导向一个更重要的结果:AI 就绪的数据基础。
大多数公司在这里挣扎。不是因为他们缺乏数据,而是因为他们的数据不可靠、不一致或无法以正确的形式访问。智能体系统在基础设施层面解决了这个问题。
数据是:
- 持续验证的
- 自动转换为可用格式的
- 保留上下文和血缘信息传递的
这意味着下游 AI 系统不需要繁重的预处理层。它们运行在已经为智能化而结构化的数据上。这消除了在整个组织中扩展 AI 的最大瓶颈之一。
8、为什么这不再是可选的
对实时数据的需求不再局限于分析团队。
产品功能、客户体验、运营决策……一切都依赖于最新且准确的数据。
传统 ETL 无法在不以指数级增加复杂性和成本的情况下满足这一需求。智能体系统不仅提高了性能。它们完全改变了成本结构。
- 更少的人工干预
- 更低的维护开销
- 更少的停机时间
- 更快的新数据源接入
结果是可持续性。团队可以在不精疲力竭的情况下扩展。
9、这是一个实际转变,不是理论概念
这不是未来的概念。它已经在前瞻性的数据平台中被实施。过渡不需要一夜之间替换现有系统。它从在当前管道之上叠加智能开始:
- 在实现完全自主之前引入异常检测
- 在高方差数据流中启用自适应转换
- 逐步用基于条件的执行替换刚性编排
随着时间的推移,辅助自动化转变为完全自主。重要的不是渐进式改进,而是有意识的转变。
10、工程领导力的角色
对于 CTO 和平台领导者来说,这种变化更多是关于思维模式而非工具。
那些曾经问"我们如何构建更好的管道?"的人,现在应该问"为什么我们还在构建需要持续维护的管道?"
智能体数据工程重新定义了数据团队的角色。从管道构建者到系统设计者。从被动运维者到主动架构师。
这种变化才是真正实现规模化能力的基础。
关于这些系统如何构建和部署的详细分解,请参阅从破损 ETL 到智能体数据工程。
11、结束语
那些认为传统 ETL 不会消亡是因为它过时的人……他们错了。它正在消亡是因为它所构建的环境已经不存在了。
数据不再是静态的。系统不再是可预测的。团队无法将时间花在维护脆弱的工作流上。
智能体数据工程是一次重置。向能够自适应、自我恢复并以最少人工干预运行的系统迈进。因为真正的目标不是更好的管道。而是根本不需要修复的管道。
停止修补那些从未被设计为持久的管道。
构建能自行处理问题并按需成长的系统。这样你的团队就可以专注于有意义的工作。
如果你的数据仍然需要人来看管,它已经在比你想象的更多地消耗你的成本。
原文链接: Why Traditional ETL is Dead: The Rise of Agentic Data Engineering
汇智网翻译整理,转载请标明出处
