用AI打造微型SaaS副业
Claude无法自己整理邮件或读取扫描版PDF。以下是我们搭建的解决流程,以及尚未解决的问题。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
在用Claude作为核心界面构建微型SaaS产品时,有两个问题很快浮现:Claude无法可靠地自行整理邮件,也无法在没有转换层的情况下读取扫描版PDF。本文记录了我们为绕过这两个问题而搭建的流程:Google Apps Script接入PyMuPDF再接入Claude,以及仍然存在的问题。
如果你错过了上周的内容,我正在为我的朋友Esha搭建一个有机认证追踪器,她经营着一家小型有机茶企业。(我是Anu Sridharan——两次入选福布斯30位30岁以下精英榜的创始人,也是YC校友,不是开发者。所以当我进展不顺时,我是认真的)
维持认证所需的文书工作量巨大,目前所有资料都散落在她的收件箱、一个蓝色实体文件夹和她的脑子里。
1、如果Claude本身就是产品呢?
不是作为附加在产品上的聊天机器人,而是主要界面、数据处理引擎、助手。全部。这是我这周的核心问题。
我受到Jaclyn Konzelmann所说的话的影响——如果某件事对你来说有点奇怪,它可能很快就会成为主流。我注意到在我自己目前的工作流程中,我经常用Claude来回沟通——通常是关于写作的头脑风暴。然后灵光一闪。
我还受到我合作过或欣赏的大部分创业公司的启发。他们 literally 在花费巨大的工程精力去重建一个人们已经拥有的东西,就为了做出一个类似Claude/ChatGPT的界面。为什么?我理解。拥有自己的产品、知识产权、不依赖第三方,这些都是风投支持的创业公司真正关心的问题。但这不是我的顾虑。我也不认为技术还是"护城河"了。我认为与消费者的关係才是(稍后再说)。有人能复制这个吗?可能。但我猜有相当数量的人宁愿每年付钱,也不想自己研究怎么做。
我需要验证的一个假设是:小企业主是否已经有付费的Claude订阅?我问了Esha。她说有,而且这可能是企业主不会介意付费的东西。截至本文撰写时,Claude Pro的价格是每月20美元。假设验证通过,决定已做。
所以,用户优先,一如既往。我从一个仪表板模型开始,发给Esha,她确认这涵盖了她需要的功能。然后就开始实际搭建了。而这就是事情变得有趣的地方。
2、为什么Claude无法自己整理邮件?
真正困难的问题是数据收集。所有数据要从哪里、如何收集?这实际上是最棘手的部分,而且我们还需要看看在实践中是否可行。但到目前为止,Claude在没有指导的情况下,不太擅长自己整理邮件并捕捉所有需要的内容。这不是我们构建中的怪癖。Claude内置的Gmail连接器只有在你直接提示它时才会访问你的收件箱。
它不会自动监控、过滤或分类。因此需要流程。所以这才是真正需要解决的问题。
3、为什么Claude无法读取扫描版PDF?
另一个问题:如果我们用Claude作为处理数据的地方,它实际上无法下载PDF并使其可搜索。我们需要更好的方式来查看数据。
4、解决方案是什么?搭建一个流程
所以我们需要一个流程。我们需要某种东西,介于原始邮件和Claude之间,捕捉正确的附件,将它们转换成可读的格式,然后干净地传递过去。
解决方案是一个在后台运行的Google Apps Script,自动将来自已知供应商的PDF附件保存到结构化的Google Drive文件夹中。现在我们还需要看看人们是否愿意复制粘贴/在应用脚本上进行一次性设置,但我希望这是可行的,由Claude literally 引导你完成。
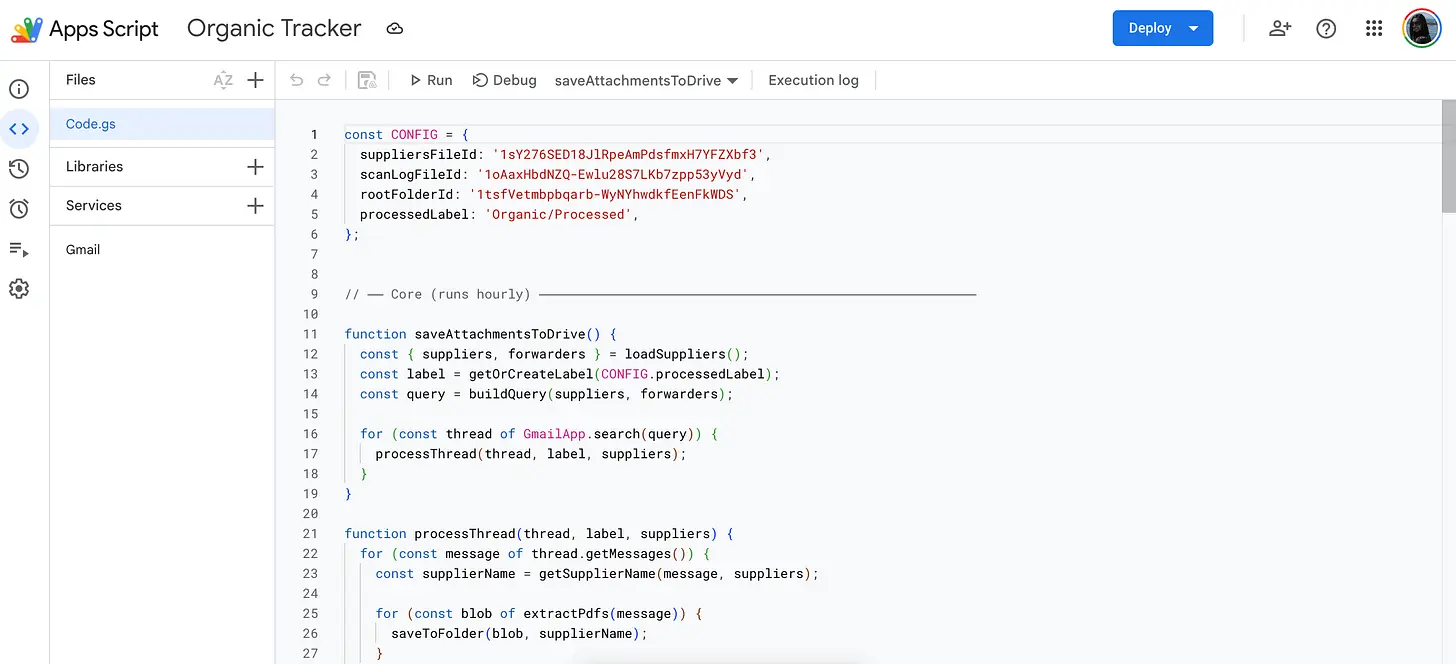
但一旦设置完成,Claude就会读取文档,提取关键数据,并记录到数据库中。无需手动下载,无需复制粘贴,无需处理电子表格。
完整的流程是:供应商邮件到达 → Apps Script捕捉附件并保存到Drive → Claude读取并记录数据。
5、成功了吗?
让这整个流程运转起来花了大半个星期,而且进展并不顺利(说实话,这也是这个博客系列的意义所在)。
第一个问题是转发邮件。Apps Script经历了两次完整的重写。第一个版本在处理转发邮件时崩溃了,而这实际上是Esha的很多文件的到达方式。解决方案是切换到另一种不同的Gmail方法,无论邮件是如何转发的,都能更可靠地处理附件。但更深层的邮件问题(即Claude如何知道一开始要关注哪些邮件)尚未完全解决。我们的猜测是,这可以通过入职流程解决:一次初次设置的对话,Claude在其中了解预期会有哪些供应商、他们的邮件长什么样,以及当新邮件到达时该怎么做。我们还没有验证这一点。那是下周的任务。
第二个问题有点出乎意料。
我们以为流程已经正常工作了。然后我们遇到了一份提货单(即标准运输文件),它是在Xerox机器上扫描的。Claude就是读不了。同样,这不是一个bug,而是一个已知的限制。Anthropic自己的文档确认,没有嵌入文本层的扫描版PDF,无论文件大小如何,Claude实际上都无法读取。没有文本层,Claude就没有可处理的内容。一份原始扫描版PDF对Claude来说基本上就是一张没有文本层的模糊照片。它无法提取任何一个字段。
所以我们去找解决方案。那个解决方案是PyMuPDF:一个免费的开源Python库,它首先将扫描版PDF渲染成一张合适的图片,然后Claude就可以使用它的视觉能力来读取。
从扫描版PDF到图片的转换是自动进行的,在文档到达Claude之前就已经完成。我们下周会原型化整个流程,但这周我们只是单独测试了它。一旦就位,我们再次将那份Xerox扫描的提货单传过去。Claude完美地读取了每一个字段(供应商、批号、数量、港口、日期)。全部。成功了!
到周末,这个流程已经针对Esha的真实文档,在五种不同的文件类型上进行了端到端的验证。那一刻感觉有一点点真实了 :)
6、下周
下周:搭建MCP服务器(即让Claude实际读写数据库的那一层)。最后测试入职流程!万岁!
与此同时,你有没有尝试过搭建类似的东西?你有没有遇到类似的故障?如果有,请分享。听听什么有效、什么无效(在所有这些炒作之中)是很有趣的。
如果你想了解我们认为AI正在创造的所有小企业机会,请阅读这里。
Q: Claude能读取扫描版PDF吗? A: 不能直接读取。原始扫描版PDF本质上是没有文本层的照片,Claude无法从中提取字段。这是一个已知的限制。解决方案是PyMuPDF,一个免费的开源库,它首先将扫描版PDF渲染成一张合适的图片,然后Claude就可以使用它的视觉能力来读取。在我们的测试中,经过转换后,Claude完美地读取了Xerox扫描的提货单上的每一个字段。
Q: 什么是PyMuPDF,为什么Claude需要它? A: PyMuPDF是一个免费的开源Python库,它在将扫描版PDF传递给Claude之前,先将其转换为图片。然后Claude的视觉能力就可以准确地读取图片。没有这个步骤,Claude看到的扫描版PDF就是一张模糊的照片,无法从中提取任何数据。
Q: 用Claude构建微型SaaS需要懂编程吗? A: 不一定。在这个构建中,最技术性的组件是一次性的Google Apps Script设置,而且计划是让Claude本身通过入职对话引导用户完成设置。核心产品逻辑通过Claude现有的界面运行,而不是自定义构建的前端。
Q: 用Claude处理供应商文档的流程是什么? A: 供应商邮件到达 → Google Apps Script捕捉PDF附件并保存到结构化的Google Drive文件夹 → PyMuPDF将任何扫描版PDF转换为图片 → Claude读取文档,提取关键数据字段,并记录到数据库中。这在构建的第二个星期,针对五种不同的文件类型进行了验证。
汇智网翻译整理,转载请标明出处
