构建自我纠正的AI智能体
一个完全本地的生成器 → 评判器 → 裁决器循环:三个Ollama模型、一个结构化的JSON评分标准、条件路由,以及一个决定循环何时结束的质量门槛。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
在这篇文章中,我将向你展示如何构建一个完全在你自己的机器上运行的自我纠正智能体循环。 这个智能体接收一个Python源文件并为其生成Markdown API文档。但我们不是让模型一次性写完文档然后祈祷它完美无缺,而是建立一个循环:一个模型起草,第二个模型根据源代码批评草稿,草稿返回进行修改直到通过质量门槛。第三个模型然后进行最终审查以解决任何遗留的矛盾。
这种模式通常被称为反思。核心思想很简单:LLM在发现文本中的缺陷方面比一次性生成无瑕疵文本要擅长得多。因此,你将工作分成不同的角色。这里有一个重要的细节是每个角色由不同的本地模型提供服务。如果同一个模型既写又评分,它倾向于为自己的输出盖章通过。使用单独的评判模型可以避免这个问题。
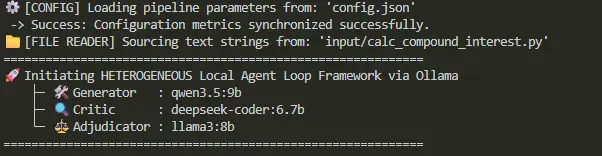
在我之前的文章中,我是从零开始构建本地智能体,没有使用框架,我当时说过,一旦你自己构建了基础版本,像LangGraph这样的工具就更有意义了。所以,这次我特意使用LangGraph,因为带有条件退出的修改循环正是它设计的那种循环工作流。模型由Ollama提供服务。我使用qwen3.5:9b作为生成器,deepseek-coder:6.7b作为评判器,llama3:8b作为裁决器,但角色可以通过一个小JSON文件配置,所以完全可以用你本地拉取的任何模型替换。
结果是一个控制台命令reflexion,它读取源文件、运行循环、打印每轮的记分卡,并将润色后的Markdown写入磁盘。整个流程是一个约360行的Python文件。
以下是我们将要介绍的七个部分:
- 第1部分:工作流状态和评判器的评估模式
- 第2部分:生成器节点
- 第3部分:评判器节点
- 第4部分:决定循环或退出的路由器
- 第5部分:裁决器节点
- 第6部分:连接图
- 第7部分:运行时、配置和输出清理
那么,让我们开始吧。
1、安装
完整代码在GitHub上:local-reflexion-agent。所有内容都在一个包中,src/reflexion/main.py,通过pyproject.toml暴露为控制台脚本。
首先,克隆仓库并以可编辑模式安装:
git clone https://github.com/jfjensen/local-reflexion-agent.git
cd local-reflexion-agent
pip install -e .
这会引入langgraph、langchain-core、langchain-community、langchain-ollama和pydantic,并注册一个名为reflexion的控制台脚本。
接下来,确保Ollama在本地运行,并且你已经拉取了config.json中引用的三个模型:
ollama pull qwen3.5:9b
ollama pull deepseek-coder:6.7b
ollama pull llama3:8b
在你的情况下,你可能想使用不同的模型,这没问题。仓库根目录的config.json是分配角色的地方,我们将在第7部分中回到它。
仓库在input/中附带了三个小型示例源文件,所以你可以立即运行流程:
reflexion --input input/source_function_a.py --output output/result.md --config config.json
所以,安装完成后,让我们逐一介绍各部分。
2、工作流状态和评判器的评估模式
首先,我们需要两个数据结构。一个描述评判器必须返回什么,另一个描述在图中流动的内存。
评判器的输出是两者中更有趣的一个。一个本地6.7B模型,放任自流的话,当你要求它给分数时会欣然回复一段散文。我们不要散文,我们要数字和一个可操作的修复。所以,我们定义一个Pydantic模式并强制模型填写它:
class DocEvaluationSchema(BaseModel):
"""用于从本地评判器模型强制结构化JSON模式约束的Pydantic模式。
故意只包含判断字段:总平均分和通过/失败决策在代码中计算。"""
technical_accuracy: int = Field(description="准确性评分,0-100。")
completeness: int = Field(description="覆盖参数定义的完整性评分,0-100。")
single_critical_fix: str = Field(description="需要修复的单一最高优先级问题。")
几个需要注意的点:
single_critical_fix字段是循环的核心。我们不要求评判器列出所有问题,而是要求一个最高优先级的修复。小型生成器模型处理"修复这一个问题"比处理一大堆混合反馈要好得多。- **模式中故意不包含的内容与包含的一样重要。**这个模式的早期版本还要求模型给出总体百分比和通过/失败布尔值。这被证明是一个错误,我将在第3部分中回到它失败的原因。简短版本:永远不要让模型做Python一行就能完成的算术或阈值比较。模式现在只包含模型实际需要判断的内容,评判器节点在代码中计算平均分和通过/失败决策。
Field描述不是装饰品。它们作为JSON模式约束的一部分传递给模型,所以它们实际上是微型提示。
然后是状态。LangGraph将状态对象从一个节点传递到另一个节点,每个节点返回对其的部分更新。我们将其定义为TypedDict:
def append_scores(old: List[int], new: List[int]) -> List[int]:
return old + new
class AgentWorkflowState(TypedDict):
"""异构本地图布局的内存跟踪状态。"""
source_code: str
generated_markdown: str
current_score: int
score_history: Annotated[List[int], append_scores]
required_fix: Optional[str]
iteration_count: int
is_approved: bool
final_adjudicated_markdown: Optional[str]
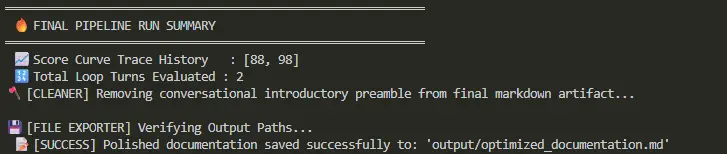
一个不太明显的行是score_history。Annotated[List[int], append_scores]类型告诉LangGraph使用append_scores约简器合并对此字段的更新,而不是覆盖它。所以,每次评判器返回分数时,它都会被追加到历史记录中,而不是替换它。在运行结束时,你会得到跨越所有修改轮次的完整分数曲线,这被证明是流程打印的最具信息量的单行内容。
3、生成器节点
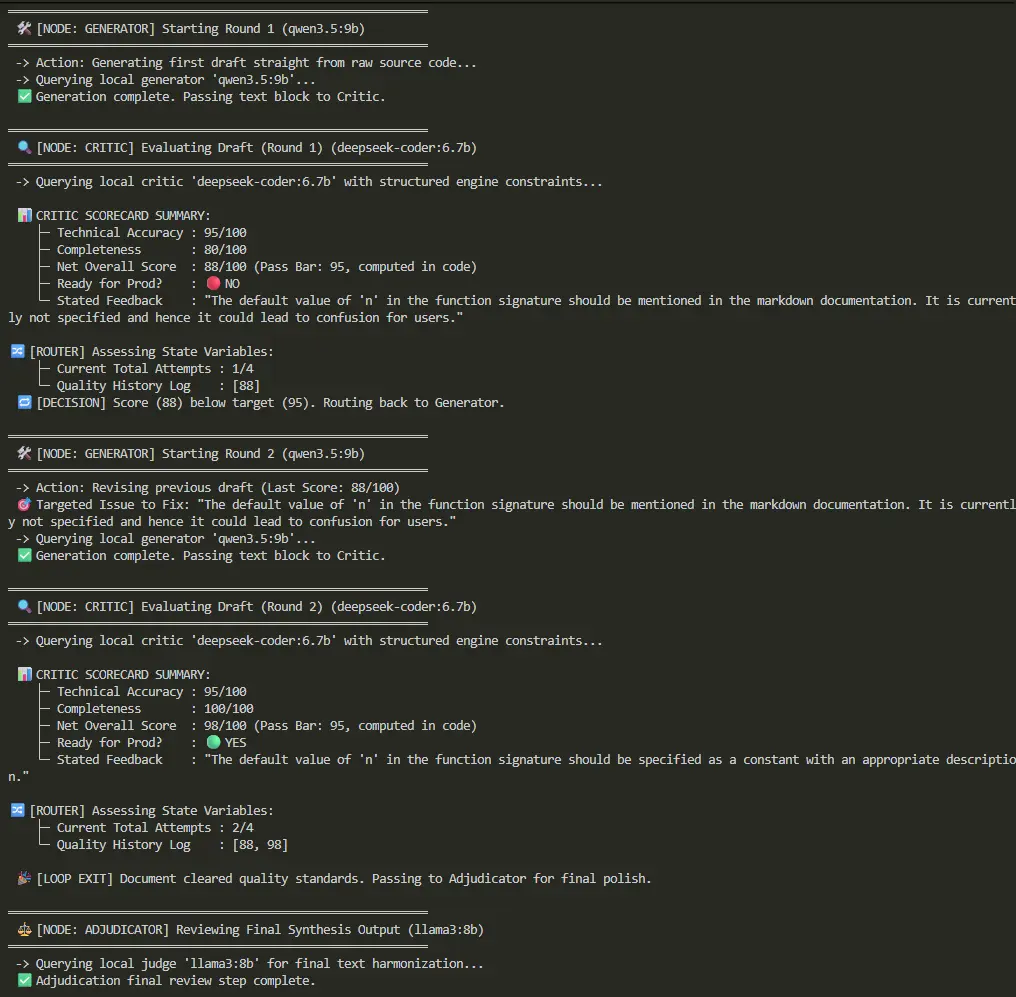
现在,第一个节点。在LangGraph中,节点只是一个接收状态并返回更新字典的函数。生成器有两种模式:第一次运行时它直接从源代码起草文档,之后的每次运行它都会修改之前的草稿以解决评判器提出的修复。
def content_generator_node(state: AgentWorkflowState) -> dict:
"""生成器节点:完全专注于起草/编辑文档文本布局。"""
current_iteration = state.get("iteration_count", 0)
target_model = MODEL_REGISTRY["GENERATOR"]
llm = ChatOllama(model=target_model, temperature=0.7)
if not state.get("generated_markdown"):
system_prompt = "你是一名专业的技术作家。将原始代码片段转换为干净、全面的API markdown文档。"
user_prompt = f"为以下源代码生成Markdown文档:\n\n{state['source_code']}"
else:
system_prompt = "你是一名精确的编辑,正在重写技术文档以修复结构缺陷。"
user_prompt = (
f"你之前的文档草稿评分为{state['current_score']}/100。\n"
f"你必须完全重写文档以修复这个具体问题:{state['required_fix']}\n\n"
f"原始代码上下文:\n{state['source_code']}\n\n"
f"之前的草稿:\n{state['generated_markdown']}"
)
messages = [SystemMessage(content=system_prompt), HumanMessage(content=user_prompt)]
response = llm.invoke(messages)
return {
"generated_markdown": response.content,
"iteration_count": current_iteration + 1
}
逐步说明:
模式选择:
- 如果
generated_markdown为空,这是第一轮,模型被提示为技术作家,基于原始源代码工作。 - 如果草稿已存在,模型被提示为编辑。它获得之前的评分、评判器的一个关键修复、原始源代码以及它自己之前的草稿。
修改提示:
- 告诉模型之前的评分是一个小技巧,但它有效。具体的"你得了78/100"会推动模型实际做出改变,而不是简单地改写。
- 指令说完全重写文档以修复一个具体问题。像这样的窄指令是小型本地模型能够很好遵循的。
温度:
- 生成器运行在
temperature=0.7,所以草稿在修改轮次中有一些变化。评判器,你接下来会看到,运行在零温度。
返回值:
- 节点只返回它改变的字段。LangGraph将其合并到状态中,
iteration_count每轮增加一。
4、评判器节点
接下来是评判器。这是一个完全不同的模型,默认是deepseek-coder:6.7b,正确设置它的提示比构建的任何其他部分花费了我更多尝试。
def content_critic_node(state: AgentWorkflowState) -> dict:
"""评判器节点:使用不同的模型和严格的JSON格式交叉检查生成器输出。"""
target_model = MODEL_REGISTRY.get("CRITIC")
llm = ChatOllama(model=target_model, temperature=0.0)
structured_llm = llm.with_structured_output(DocEvaluationSchema)
system_prompt = (
f"你是一名细致的QA检查员,正在根据源代码评估API文档。"
f"你是在给文档评分,不是给源代码评分。永远不要因为源代码本身可以设计得更好而扣分,"
f"也永远不要要求更改源代码。"
f"通过扣分来评分:从100开始,只对你能通过指向与源代码矛盾的具体文档文本"
f"验证的具体错误扣分。"
f"检查源代码中的每个'raise'语句是否都用其确切的异常类型和确切的引用错误消息"
f"记录了:缺失、拒绝或错误引用的异常是重大扣分项。"
f"重新计算文档示例中显示的每个数值,与源代码实际会返回的值对比:错误的数字是重大扣分项。"
f"如果你找不到可验证的错误,评分为100。"
f"single_critical_fix必须指向要更改的文档文本,而不是源代码。"
)
user_prompt = (
f"相对于其原始源代码评估以下markdown文档。\n\n"
f"原始源代码:\n{state['source_code']}\n\n"
f"生成的Markdown文档:\n{state['generated_markdown']}"
)
evaluation: DocEvaluationSchema = structured_llm.invoke([
SystemMessage(content=system_prompt),
HumanMessage(content=user_prompt)
])
# 模型提供判断分数;算术和通过/失败决策在这里的代码中完成。
overall_score = round((evaluation.technical_accuracy + evaluation.completeness) / 2)
is_approved = overall_score >= QUALITY_SCORE_BAR
required_fix = sanitize_critical_fix(evaluation.single_critical_fix)
return {
"current_score": overall_score,
"score_history": [overall_score],
"required_fix": required_fix,
"is_approved": is_approved
}
逐步说明:
结构化输出:
llm.with_structured_output(DocEvaluationSchema)是关键行。它约束模型使返回的是经过验证的DocEvaluationSchema对象,而不是自由文本。没有JSON解析,没有正则表达式,没有格式错误时的重试逻辑。- 评判器运行在
temperature=0.0。评分器应该是确定性的,或者尽可能接近本地模型能达到的程度。
提示以及它是如何演变的:
- 这个提示经历了三个版本,这个历史值得讲述,因为它是这篇文章中最具可迁移性的教训。我的第一个版本礼貌地要求模型分析文档并评分。结果是礼貌的高分——80多分和90多分——即使文档中包含虚构的错误消息,循环过早退出了。
- 所以,第二个版本告诉模型要"异常严厉的QA检查员",发现问题时要"积极压低分数"。在下一次测试运行中,评判器连续四轮给一个基本正确的草稿打了0分,而它第一轮的理由完全错误地描述了源代码。小型评判器模型不会校准,它跟随语气。被告知要慷慨,它就盖章通过。被告知要严厉,它就把所有东西都打到最低分。
- 上面的版本通过程序而非语气来引导。通过扣分来评分,从100开始。只对你能通过指向具体文档文本验证的错误扣分。如果没有可验证的错误,分数就是100。锚定评分机制给模型表达情绪的空间要小得多。
- 提示还明确指出评判器是在给文档评分,不是给函数评分。这是因为在几次运行中,"关键修复"变成了对源代码设计的批评——缺少验证、弱加密等——而生成器对此无能为力,因为它的工作是描述代码的现状。
- 两个验证检查——确切的异常类型带引号消息和重新计算的示例数字——被明确命名,因为这两个错误类别在我的测试运行中逃脱了更模糊的提示。命名你关心的具体检查与小型评判器模型配合得比笼统的准确性请求好得多。
算术在代码中完成,不在模型中:
- 这是我早在第1部分中提到的教训,我从一次我几乎不敢相信的运行中学到的。我之前的版本要求模型自己给出总体百分比和通过/失败布尔值。在一次运行中,评判器返回技术准确性100和完整性100,"净平均分"正好是95——碰巧是它被告知的通过门槛,而不是它自己分数的任何平均值。在另一次运行中,它连续四轮给一个草稿打了97分(门槛是95),每次都设置通过标志为false,所以循环在已经通过的草稿上浪费了所有四次尝试。路由器信任了布尔值,它的日志愉快地报告97低于95。
- 所以,现在模型只报告两个子分数,这三行Python完成其余工作:计算平均值、与
QUALITY_SCORE_BAR比较、以及路由器将执行的决策。阈值比较不是判断调用,不是判断调用的内容不应该委托给模型。
sanitize_critical_fix防护:
- 在那次四轮运行中,评判器在一轮中的反馈退化为几百个重复的../令牌,然后这些被逐字注入生成器的下一个修改提示中,作为"要修复的问题"。小型模型在结构化输出约束下偶尔会这样做。
- 防护检查修复字符串是否为空或退化——本质上是否重复一个令牌或由少数几个不同字符构成——如果是,则替换为通用指令,要求重新对照源代码验证文档。不聪明,但它阻止了垃圾引导整个修改轮次。
防护本身足够小,可以完整展示:
def sanitize_critical_fix(fix: Optional[str]) -> str:
"""防止退化的评判器反馈(空字符串或失控的令牌重复)。"""
stripped = (fix or "").strip()
words = stripped.split()
is_degenerate = (
not stripped
or len(set(stripped)) <= 4
or (len(words) > 5 and len(set(words)) <= 2)
)
if is_degenerate:
return "逐行对照源代码重新验证文档,并纠正最薄弱的部分。"
return stripped
关于返回值的最后一个细节:score_history作为单元素列表返回,第1部分的约简器将其追加到现有历史中,所以分数曲线在各轮中累积。
该节点还每轮向控制台打印记分卡,包括技术准确性、完整性、与通过门槛的净分数,以及评判器陈述的反馈。我在这里删除了这些打印语句,但它们在仓库中,看着记分卡在各轮中变化老实说是运行这个东西的乐趣的一半。
5、决定循环或退出的路由器
所以,我们现在有了生成器和评判器,我们需要一些东西来决定每次批评后发生什么。在LangGraph中,这是一个路由函数:它检查状态并返回下一个节点的名称。
def execution_router(state: AgentWorkflowState) -> Literal["content_generator", "content_adjudicator"]:
"""监控工作流状态并决定重复、循环或退出到裁决。"""
if state["is_approved"]:
return "content_adjudicator"
if state["iteration_count"] >= MAX_ATTEMPTS:
return "content_adjudicator"
return "content_generator"
几个需要注意的点:
- **循环只有两个出口。**要么评判器批准了草稿,要么我们达到了尝试上限。在这两种情况下,草稿都进入裁决器。在其他所有情况下,它返回给生成器。
- **硬上限比看起来更重要。**95分的质量门槛加上严厉的评判器意味着有些草稿永远无法通过。没有
MAX_ATTEMPTS,循环会永远进行Ollama调用。四次尝试有些随意,但足够粗糙和好用,而且它是可配置的。 Literal返回类型不仅仅是文档。它匹配我们在第6部分连接图时定义的路由映射。- 与其他节点一样,我在这个摘录中删除了控制台打印。在仓库中,路由器在每次决策前记录尝试次数和分数历史。
6、裁决器节点
然后是最终角色。无论什么退出循环——无论是通过了还是超时了——都会由第三个模型进行最后一次处理。裁决器的工作不是添加内容。而是解决在修改轮次中悄悄出现的矛盾,并删除任何对话性内容。
def content_adjudicator_node(state: AgentWorkflowState) -> dict:
"""裁决器节点:在循环外运行以解决结构矛盾并最终确定文本。"""
target_model = MODEL_REGISTRY["ADJUDICATOR"]
llm = ChatOllama(model=target_model, temperature=0.2)
system_prompt = (
"你是一名高级技术文档编辑,正在对一份经过多轮修改的API文档给出最终意见。"
"你的工作是阅读原始源代码,查看最新草稿,消除任何冲突的陈述,清理语义散文,"
"并输出润色后的最终markdown文档。不要包含任何前言、评论、对话性寒暄或解释——"
"只返回markdown文档。"
)
user_prompt = (
f"审查并最终确定此文档模板。\n\n"
f"原始源参考代码:\n{state['source_code']}\n\n"
f"最新修改草稿:\n{state['generated_markdown']}\n\n"
f"最后遗留的评判器关注点:\n\"{state['required_fix']}\""
)
response = llm.invoke([SystemMessage(content=system_prompt), HumanMessage(content=user_prompt)])
return {"final_adjudicated_markdown": response.content}
逐步说明:
为什么这个节点存在:
- 经过几轮"完全重写以修复X"后,草稿可能以内部矛盾告终。一轮添加了一个声明,后来的改写在没有删除它的情况下矛盾了它。裁决器获得源代码、最新草稿和评判器最后遗留的关注点,并被告知消除冲突的陈述。
- 它还作为从未通过门槛的草稿的退出路径。我们不是发布原始的第四次尝试,而是至少获得一个协调版本。
温度:
- 裁决器运行在
temperature=0.2。低,因为这是编辑工作,但不为零,因为它仍然需要重写散文。
只返回Markdown的指令:
- 本地模型喜欢以"当然!这是您的文档:"开头,以"希望这有所帮助。"结尾。提示禁止了这一点。正如我们将在第7部分中看到的,仅靠提示还不够,有一个后处理步骤来捕获漏网之鱼。
7、连接图
现在我们组装各部分。这是LangGraph发挥其价值的地方,因为整个拓扑结构——包括循环——都在几行中声明:
builder = StateGraph(AgentWorkflowState)
builder.add_node("content_generator", content_generator_node)
builder.add_node("content_critic", content_critic_node)
builder.add_node("content_adjudicator", content_adjudicator_node)
builder.set_entry_point("content_generator")
builder.add_edge("content_generator", "content_critic")
builder.add_conditional_edges(
"content_critic",
execution_router,
{
"content_generator": "content_generator",
"content_adjudicator": "content_adjudicator"
}
)
builder.add_edge("content_adjudicator", END)
agent_pipeline = builder.compile()
逐步说明:
节点和入口点:
- 三个节点函数按名称注册,生成器被设为入口点。
- 生成器总是移交给评判器。那条边是无条件的。
条件边:
add_conditional_edges将第4部分的路由器附加到评判器。每次批评后,路由器运行,其返回值在映射中查找下一个节点。这个映射就是循环:content_critic可以路由回content_generator,后者又流向content_critic。
编译:
builder.compile()返回一个可运行的流程。从此以后,整个循环是一个agent_pipeline.invoke(initial_state)调用。
如果你曾经尝试过用while循环、手动状态传递和尝试计数器手写这个循环,你会认识到有多少簿记工作刚刚消失了。图声明也是自文档化的,这是手写循环永远做不到的。
8、运行时、配置和输出清理
最后是reflexion控制台脚本指向的run()函数。它做四件事:解析参数、加载配置、运行流程和清理输出。我不会在这里复制全部内容,因为大部分是参数解析,你可以在仓库中阅读,但有两个部分值得展示。
首先,配置加载器。模型角色和循环参数来自config.json:
{
"model_registry": {
"GENERATOR": "qwen3.5:9b",
"CRITIC": "deepseek-coder:6.7b",
"ADJUDICATOR": "llama3:8b"
},
"quality_score_bar": 95,
"max_attempts": 4
}
如果文件缺失或无法读取,加载器会回退到这些默认值,所以流程总是能启动。输入、输出和配置路径的默认值相对于已安装的包解析,对于可编辑安装意味着仓库根目录。所以,从任何地方运行reflexion都会使用仓库的config.json和input/文件夹,你可以用--input、--output和--config覆盖任何内容。
其次,输出清理。这是处理本地模型变得必要的部分:
raw_final_text = final_output.get("final_adjudicated_markdown", "")
clean_final_markdown = raw_final_text
# 1. 清理前言(顶部的对话文本)
if "#" in raw_final_text:
parts = raw_final_text.split("#", 1)
if len(parts[0].strip()) > 0 and len(parts[0].strip()) < 200:
clean_final_markdown = "#" + parts[1]
# 2. 清理后记(底部的对话和元审查文本)
meta_prefixes = (
"注意:", "请注意", "我希望", "这就是全部", "总之",
"没有格式错误", "没有矛盾", "没有错误",
"让我知道", "随时", "请让我知道"
)
meta_keywords = ("错误或矛盾", "发现了矛盾", "发现了错误")
lines = clean_final_markdown.rstrip().split("\n")
while lines:
last_line = lines[-1].strip()
if not last_line:
lines.pop()
continue
lowered = last_line.lower()
# 真实内容通常携带Markdown结构;元聊天则不然。
is_structural = lowered.startswith(("#", "|", "-", "*", ">", "`")) or lowered[0].isdigit()
is_meta = (not is_structural) and (
lowered.startswith(meta_prefixes) or any(k in lowered for k in meta_keywords)
)
if not is_meta:
break
lines.pop()
clean_final_markdown = "\n".join(lines).rstrip() + "\n"
几个需要注意的点:
- 前言检查。如果在第一个#标题之前有文本且短于200个字符,它几乎可以肯定是"以下是最终文档:"这样的开场白,会被剪掉。如果长于200个字符,我们保留它,因为它可能是真实内容。
- 后记扫描。文档底部逐行向上遍历。如果一行看起来像模型聊天而不是内容,就会被剪掉:"注意:"或"我希望"这样的结束语,或遗留的审查裁决如"未发现格式错误或矛盾。"——我的一次测试运行在一篇本来不错的文档末尾留下了这行。因为它是循环而不是单次检查,几行堆叠的结束语在一次遍历中就会被删除。
- 结构防护。任何以Markdown标记、标题、表格行、项目符号、引用块、代码围栏或数字开头的行永远不会被触及。所以包含"没有错误"字样的表格行会存活,只有纯散文行才是删除的候选。
- 这是字符串手术,不是智能,它不会捕获一切。但它捕获了我实际观察到的所有模型产生的模式,而且成本为零。
清理后,最终Markdown被写入输出路径,控制台打印运行摘要,包括完整分数历史和循环总次数。
9、尝试一下
仓库附带三个示例输入:一个指标过滤函数、一个API签名检查和一个复利计算器。所以,要为第一个生成文档:
reflexion --input input/source_function_a.py --output output/result.md --config config.json
然后你会看到循环工作的过程。生成器宣布它的轮次,评判器打印它的记分卡,路由器解释它是循环返回还是退出。
仓库中的output/文件夹包含我对所有三个输入的运行结果,所以你可以看到流程产生的结果而无需运行任何东西:适当的参数表、返回值描述和带有确切引用错误消息的抛出异常表。
三个输出文件中有两个包含一个小型示例错误,正是下面讨论的那种——声明的输出与代码返回的不匹配,一个示例中应该返回的地方抛出了异常。我宁愿提交诚实的展品也不愿提交修改过的,所以把发现它们当作一个练习。
10、出错时
现在,诚实地谈谈这个出错的地方,因为它确实会出错。这些是我在我自己的运行中观察到的失败模式。一次运行记录了错误的异常类型和完全虚构的错误消息,而源代码抛出的是带有特定字符串的TypeError。
另一次运行走了相反的方向,声称根本没有显式异常。一份文档包含一个版本历史表,带有虚构的"0.1初始版本"条目和"TBD"日期,这些在源代码中都不存在。一个示例打印的收益率比约为0.86,而实际答案是0.667。一份本来不错的文档以评判器自己的裁决"未发现格式错误或矛盾。"结束,作为最后一行。
一次运行连续四轮给草稿打了97分(通过门槛是95),同时坚持认为草稿未准备好,其中一轮的反馈退化为几百个重复的../令牌。在我将评判器提示过度校正为严厉后,同一个评判器连续四轮给一个基本正确的草稿打了0分,理由是一个关于源代码的声明,而该声明根本是错误的。评判器不是一个固定的法官,它不是一个计算器,它会放大你放入其提示中的任何情绪。
幸运的是,观察到的失败是集群化的,每个集群都在代码中得到了针对性的缓解。内容失败——文档中错误的异常和错误的算术——通过评判器提示中命名的验证检查来解决。校准失败——一个极端的礼貌盖章和另一个极端的打到底——通过提示中基于扣分的评分程序,以及将平均值和阈值决策从模型移入评判器节点的Python中来解决。
输出失败——结束语和遗留的审查裁决——通过后记扫描来解决,退化反馈通过sanitize防护来解决。这些都不会将循环变成保证,提示指令是请求,不是证明。如果在所有这些之后分数仍然波动,最有效的旋钮不是提示本身,而是模型:评判器是注册表中最难的工作,将config.json中的CRITIC条目换成更强的通用模型只需要一行代码且不需要修改代码。
循环确实做的,可靠地,是产生比对同一生成器模型的单次提示好得多的文档,分数历史给你一个诚实的痕迹,记录它是如何到达那里的。如果你的运行一直达到尝试上限,要调整的旋钮是quality_score_bar(你可以从95降低)和max_attempts(你可以从4提高)。
11、结束语
将所有这些放在一起,我们最终得到一个约360行的单文件流程:
- 为评判器定义共享状态和结构化评估模式,分数平均和通过决策在代码中完成,而不是由模型完成。
- 用一个本地模型起草文档,用另一个不同的模型批评它,所以没有人给自己的作业评分。
- 将草稿路由回有针对性的修改,直到达到可配置的质量门槛或达到尝试上限。
- 运行第三个模型作为最终裁决器,解决修改轮次中的矛盾。
- 在将最终Markdown写入磁盘之前清理对话性前言和后记。
- 完全通过一个小
config.json配置,所以更换模型或放宽循环不需要代码更改。
这里有扩展的空间。你可以给评判器多个评分维度,让路由器选择最弱的一个来修复,而不是依赖单个关键修复。你可以添加第四个节点来运行文档化代码的示例并将真实错误反馈到循环中,这将捕获评判器遗漏的幻觉声明。或者你可以将相同的生成器 → 评判器 → 裁决器形状指向完全不同的任务——例如翻译或测试生成——因为图中没有任何内容是特定于文档的。
在我之前从零开始的智能体中,我认为一旦你的工作流有真正的循环、分支和共享状态,框架就物有所值。这个流程正是这种情况,LangGraph处理了我不想手写的部分:状态合并、条件路由、循环本身。先构建基础版本后,我能够分辨出框架的哪些部分在为我做真正的工作。我仍然推荐那个顺序。
原文链接:Build a Self-Correcting AI Agent with LangGraph and Ollama
汇智网翻译整理,转载请标明出处
