企业上下文层图解
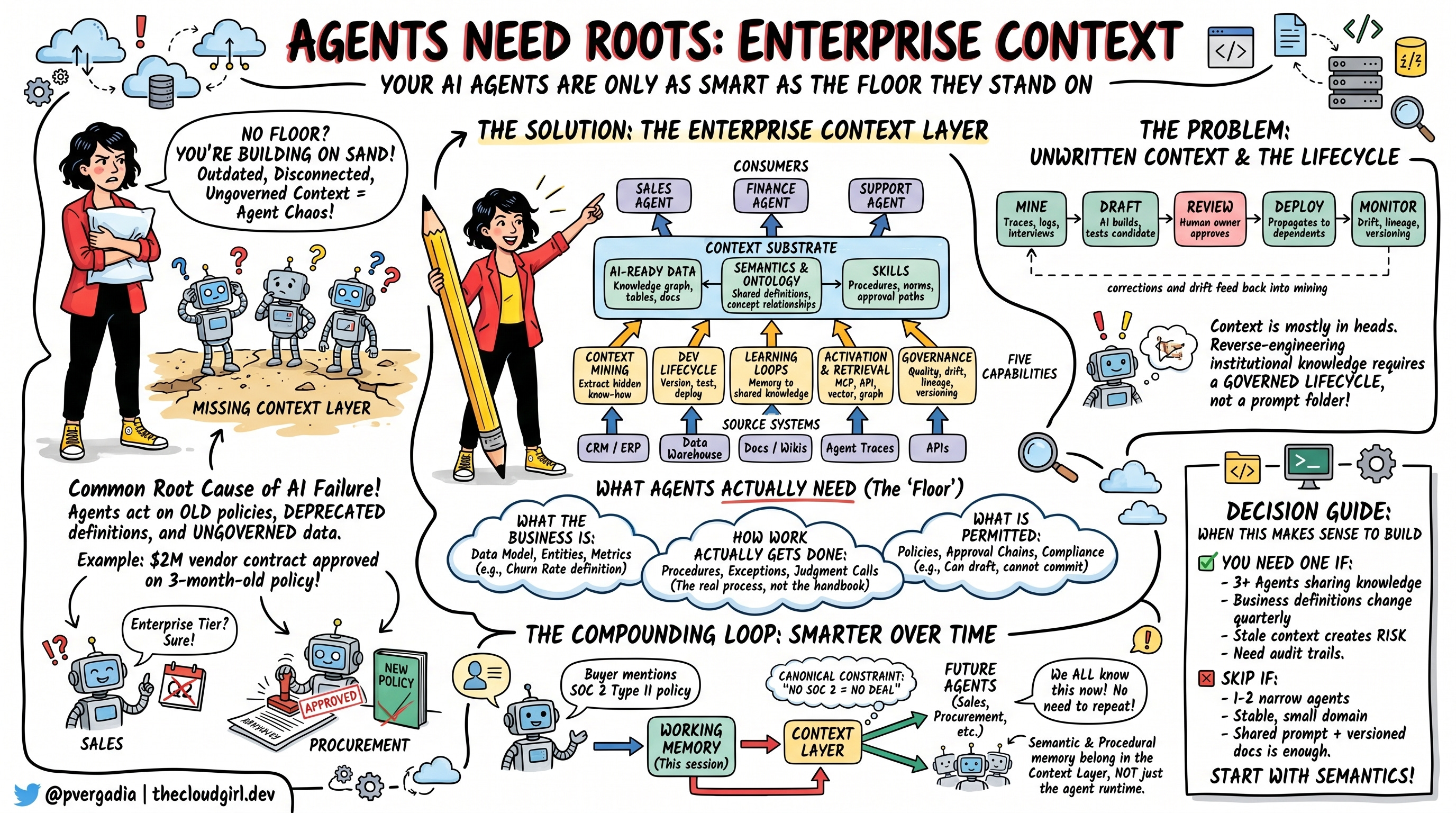
这个地基有一个名字。它叫做企业上下文层。如果你在部署AI智能体时没有考虑到这一点,你就是在沙子上建房。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我见过每一个失败的企业AI项目,根本原因都一样。不是模型。不是提示词。甚至不是智能体框架。而是缺少地基。
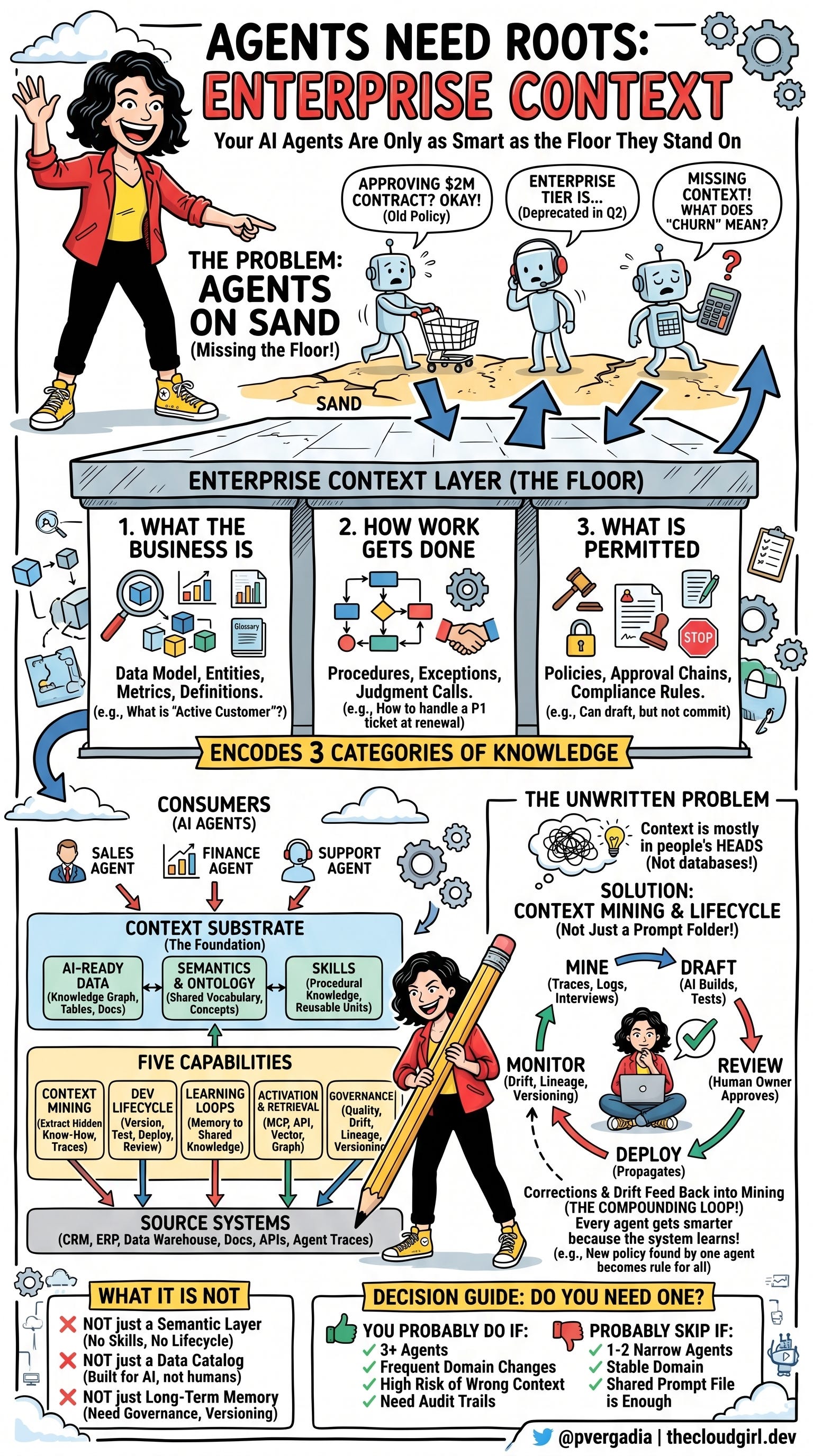
团队启动一个智能体来处理采购审批,它会毫不犹豫地批准一份200万美元的供应商合同,因为没人告诉它三个月前已经更改的政策。或者一个销售智能体使用定价团队在第二季度就已经废弃的"企业级"定义来回答客户关于定价的问题。智能体没有出错。它运行得很完美,只是基于过时的、断连的、不受治理的上下文。
这个地基有一个名字。它叫做企业上下文层。如果你在部署AI智能体时没有考虑到这一点,你就是在沙子上建房。
1、智能体在真实业务中运作实际需要什么
想想在一家500人公司入职新员工需要什么。你不会只是给他们一台笔记本电脑然后指向Jira。你让他们访问CRM,并简要介绍关键客户是谁。你带他们了解销售流程实际上是如何运作的(不是手册中的版本)。你解释哪些事情他们可以单独做,哪些需要经理签字。
这种入职过程,大致就是企业上下文层为AI智能体所做的事情。它编码了三类知识:
业务是什么: 数据模型、实体、指标。在这里"流失率"意味着什么?如果客户30天或90天没有登录,算不算活跃客户?哪些账户归入哪些收入线?
工作实际上是如何完成的: 流程、例外、判断。不是"这是我们的支持升级流程图",而是"当一个客户距续约还有60天并且有一个未解决的P1工单时,我们最好的支持代表实际会做什么。"
什么是被允许的: 政策、审批链、合规规则。这个智能体可以起草折扣提案但不能承诺。那个智能体可以读取合同数据但不能发送到第三方系统。
没有这三者,你的智能体就像在风暴中仅靠仪表飞行。
2、架构,不讲空话
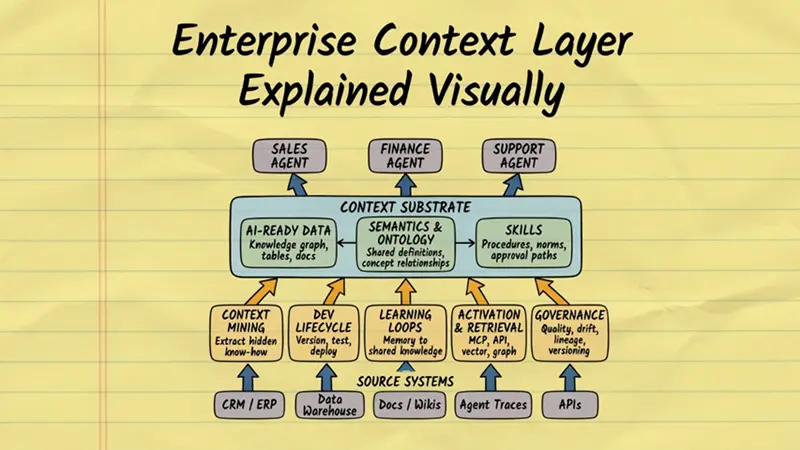
上下文层位于底部的数据和系统与顶部的智能体之间。它有两部分:一个底层基质和一组产生、更新和交付该基质的能力。
底层基质是三个相互关联的东西。第一,AI就绪的知识图谱:你的结构化数据,通过连接路径、自然语言描述以及人们通常如何查询它的机构理解来丰富。第二,语义层:你业务的共享词汇表,让销售智能体和财务智能体在就如何处理MRR产生分歧之前先就MRR的含义达成一致的术语表。第三,技能:可重用的、有版本号的程序性知识单元。不是提示词。不是Notion文档。可以进行测试、审批和更新的正式资产,当业务变化时也能相应更新。
下面的图表展示了这三个底层基质组件如何为该层的五个能力提供支撑,以及这些能力如何服务于顶部的智能体。
3、没人谈论的问题:上下文大部分是未成文的
构建企业AI有一个令人不适的现实。最能提升智能体表现的知识不在任何数据库中。它在那些在公司待了三年的人的脑袋里。
问你最优秀的销售工程师他们如何评估潜在客户,他们会给你一个流程。看他们实际评估潜在客户,你会看到不同的东西。他们注意到没人写下来的信号。他们跳过技术上要求但实际上没用的步骤。他们上报那些行动手册说没问题的事情。这就是上下文挖掘的用途。现在我们来讨论这个。
一种方法是在人类手动完成工作后观察智能体会话轨迹。如果一个智能体尝试运行月度对账但失败或被纠正了六次,那些纠正就是金子。每一个都是一个关于这家公司实际如何结账的未记录假设。另一种方法是结构化访谈领域专家,让他们在做决策时同步叙述。你是在逆向工程机构知识,而不是从头开始构建。
挑战在于这些都不产生成品的上下文。它们产生候选内容。需要经过审核和批准流程才能成为规范的原始材料。这就把我们带到了生命周期问题。
4、上下文需要开发生命周期,而不是提示词文件夹
每个软件团队现在都理所当然地认为代码需要版本控制、测试、审查和部署管道。大多数企业中今天的上下文管理方式就像1992年的软件管理:在系统之间复制,半记忆状态,在每个运行的地方都有微妙的不同。
想想一个更新了理想客户画像的公司。销售领导批准了新的ICP文档并通过Slack发送给团队。三个月后,SDR外联智能体仍然按照旧定义评估潜在客户。内容营销智能体在写关于新ICP的案例研究。分析智能体在报告两者的混合数据。没人撒谎。只是上下文没有被当作基础设施来管理。
实践中上下文开发生命周期的样子:新的上下文经过提案阶段,由AI完成草拟和初始测试。人类负责人审查并决定它是否成为规范。一旦部署,系统追踪哪些东西依赖它。当它变化时,下游负责人收到通知,必须确认其上下文仍然有效或进行更新。
治理部分不是可选的。它是区分上下文层和有野心的数据湖的关键。
5、复利循环才是全部意义
上下文层之所以值得架构投资,原因在于:每次智能体运行时它都会变得更好。
想象一个采购智能体帮助买家评估新的软件供应商。在对话过程中,买家提到他们公司有政策不支持不符合SOC 2 Type II的供应商。这个事实在对话期间存在于工作记忆中。但一旦上下文层接收、验证并将其提升为规范约束,每个未来接触供应商评估的智能体都知道这一点。买家再也不需要说一遍了。第十个智能体比第一个更聪明,因为第一个已经做了这项工作。
大多数团队在部署智能体时并没有在思考这个循环。他们在思考的是单个任务。但上下文层的复利价值来自于系统随时间积累的东西,而不是任何单次交互。
这也是记忆分类法重要的地方。工作记忆(智能体当前正在处理的内容)和情景记忆(本次会话中发生的内容)属于靠近智能体运行时的地方。语义记忆(关于业务及其客户的持久事实)和程序性记忆(工作如何完成)属于上下文层内部,因为这些是组织想要治理的,而不仅仅是存储的东西。
6、它不是什么
因为这个概念吸引了大量模糊的标签,几个对比值得明确说明。
语义层是上下文层的一个组件,不是它的同义词。语义层是为BI分析师构建的,它们在这方面做得很好:建模指标、定义维度、驱动仪表板。它们不包括技能。它们不挖掘程序性知识。它们没有部署生命周期。它们是语义底层基质,不是整个系统。
数据目录是人类的发现工具。它帮助分析师找到正确的查询表。企业上下文层是构建来服务AI作为其主要消费者的。接口不同(MCP、向量搜索、图遍历,不只是搜索栏),治理要求不同,内容也更丰富。
长期记忆,如大多数智能体框架所实现的,是一个能力的一个输入。它存储会话历史和用户偏好。这很有用。但它不等同于一个受治理的、有版本的、组织范围的上下文系统——这个系统知道某个客户上周二说了什么与构成公司官方政策之间的区别。
7、什么时候值得构建
不是每个AI项目都需要上下文层。如果你在构建一个具有窄领域、硬编码检索、没有计划扩展到更多智能体的单一用途智能体,其开销不值得。
当三个条件为真时,计算方式会改变:你在部署多个需要共享对同一业务理解的智能体;底层知识变化足够频繁使得硬编码的上下文会腐烂;智能体基于错误上下文(错误的政策、过时的定价、废弃的流程)行动的成本高于构建基础设施的成本。
在实践中,门槛比大多数人预期的要低。到了第三个或第四个智能体,缺少共享上下文层就开始产生可见的协调失败。销售和支持智能体在客户应得什么上产生分歧。财务和运营智能体基于同一指标的不同定义运行。这些失败有真实的成本,即使很难归因于"缺失的架构"。
地基很重要。在你有四个智能体运行在四个从未互相认识的地板上之前,先把它建好。
8、你需要正式的上下文层吗?
你可能需要,如果:你有三个或更多共享领域知识的智能体;你的业务定义至少每季度变化一次;智能体基于过时上下文行动会产生合规、财务或客户风险;你需要智能体决策的审计跟踪。
你可能可以跳过正式构建,如果:你有一两个窄领域智能体;领域稳定且小;共享提示词文件和有版本号的文档存储以10%的成本获得90%的价值。
从底层基质开始,特别是语义。一个防止你的智能体互相说不到一块去的共享术语表,其回报速度会比AI技术栈中几乎任何其他东西都快。
原文链接:Enterprise Context Layer Explained Visually
汇智网翻译整理,转载请标明出处
