Unsloth 零成本微调 Qwen3-8B
Unsloth将VRAM使用量减少了70%。这就是为什么你现在可以在免费的Google Colab笔记本上训练Qwen3。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
2026年的情况是这样的:微调开源LLM不再是过去的瓶颈,而Unsloth是主要原因之一。
如果你之前尝试过微调,你可能遇到过各种问题。你可能在训练期间耗尽了GPU内存。你可能在看着损失曲线以令人痛苦的速度移动。你甚至可能想过付费使用云实例,因为你的本地设置在模型面前捉襟见肘。这种令人沮丧的体验正是Unsloth被设计来解决的。
它实际做的是重写训练中最慢、最消耗内存的部分。团队用自己手写的版本替换了PyTorch的默认GPU代码,特别是处理注意力和反向传播的部分。他们报告的数据是:
- 训练期间使用约70%更少的VRAM
- 免费开源版本训练2倍加速(付费Pro版本更高,根据模型和配置有时会高得多)
- 模型精度无损——数学计算是精确的,不是近似值
用实际的话来说:使用QLoRA微调Qwen3-8B通常需要大约24GB的GPU才能舒适运行。这意味着需要RTX 3090、RTX 4090或付费的Colab Pro+实例。有了Unsloth,同样的工作可以装入Google Colab免费发放给任何Gmail账户的15GB T4 GPU中。这就是这个库代表的真正转变——不是从"不可能到简单",而是从"需要付费硬件"到"现在不需要了"。
Unsloth支持你期望的标准技术——LoRA、QLoRA、4位量化——以及较新的方法如用于强化学习微调的GRPO。你不需要知道这些术语的含义就能使用它;配置在底层自动处理。2026年,团队还发布了Unsloth Studio,一个面向不想写Python的人的可视化界面。
到本指南结束时,你将在免费的Colab笔记本上,在Python代码指令数据集上微调Qwen3-8B,每一行代码都会提供。
让我们开始构建。
1、为什么Qwen3是现在大家都在微调的模型
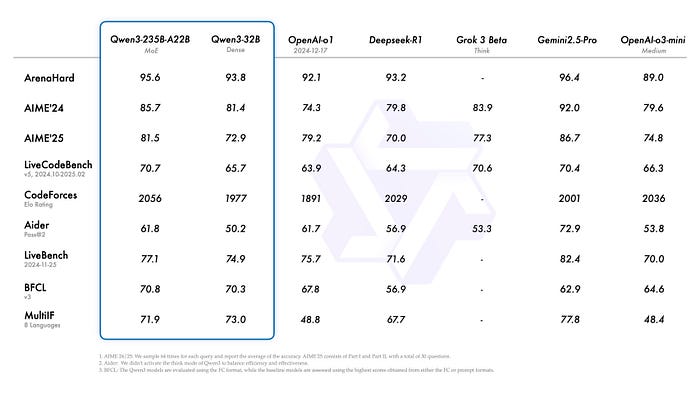
Qwen3模型的实力远超其量级,它基本上让"模型大小"成了一个无关紧要的指标。
当阿里巴巴在2025年4月发布Qwen3时,开源AI社区集体疯狂了——这是有充分理由的。
Qwen3-8B在标准编码、推理和指令跟随基准测试中,与30B-70B范围的模型竞争激烈。它支持119种语言,处理128K上下文窗口,并附带一个真正新颖的功能:内置的思考/非思考切换。
启用思考模式(enable_thinking=True)后,模型会在回答前逐步推理问题——就像直接融入架构的思维链。禁用它则可以获得快速、直接的响应,当延迟比深度更重要时。
对于编程助手用例,这是一个杀手级组合。
2026年其他值得了解的模型:
- Gemma 3(Google): 在多模态任务和指令跟随方面表现出色。12B变体是一个强大的通用选择。
- Phi-4(Microsoft): 在小型封装中有出色的推理能力。14B模型在数学和代码方面可媲美更大的竞争对手。
- Mistral Small 3.1: 快速、多语言,真正开放商业使用许可。
本教程我们选择Qwen3-8B。 它是目前社区的最爱,基准测试支持它,Unsloth有完全优化的预量化版本随时可用。
2、数据集:18,000条Python代码指令
在我们接触任何训练代码之前,让我们先谈谈数据集——因为你的数据占模型最终质量的80%。
我们使用Hugging Face上的iamtarun/python_code_instructions_18k_alpaca。
这是它是一个很好的第一个数据集的原因:
- 它立即可用。 每个样本都是一个Python编码任务——写一个函数、调试这段代码、解释这个算法。在这个上面微调教会你的模型像Python开发者一样思考。
- 它大小合适。 18,000个样本足够大,能产生有意义的行为变化,但又足够小,可以在免费T4上合理时间内训练。
- 它干净且结构化。 数据集已经采用Alpaca格式(指令+输入+输出),所以预处理工作量最小。
- 结果可见。 与抽象的NLP基准不同,你可以通过要求微调后的模型写一个函数来测试它。你会立即看到差异。
每个样本看起来像这样:
{
"instruction": "Write a Python function to find all prime numbers up to a given number N.",
"input": "",
"output": "def sieve_of_eratosthenes(n):\n primes = [True] * (n + 1)\n p = 2\n while p * p <= n:\n if primes[p]:\n for i in range(p * p, n + 1, p):\n primes[i] = False\n p += 1\n return [p for p in range(2, n + 1) if primes[p]]"
}
干净。有目的。立即可测试。让我们使用它。
3、设置环境(比你想象的步骤更少)
你需要什么:
- 一个免费的Google Colab Notebook,配备T4 GPU(运行时 → 更改运行时类型 → T4 GPU),或者
- 一个本地NVIDIA GPU,8GB+ VRAM(RTX 3060、3080、4070或更好)
"你可以使用我预配置的Colab笔记本来跟随操作:在Colab中打开 →。一切都已设置好——只需点击全部运行"
安装——将以下内容粘贴到你的第一个单元格中:
%%capture
!pip install unsloth
!pip install --upgrade --no-cache-dir "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
!pip install datasets trl transformers accelerate
对于CUDA 12.1+的本地设置:
pip install "unsloth[cu121-torch240] @ git+https://github.com/unslothai/unsloth.git"
pip install datasets trl
一个命令。没有依赖地狱。Unsloth的安装确实是生态中最干净的一个。
4、逐步微调代码
第1步:以4位量化加载Qwen3-8B
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Qwen3支持最多128K,但2048对编码任务足够了
dtype = None # 在Ampere/Ada上自动检测BFloat16,在旧GPU上使用Float16
load_in_4bit = True # 秘密武器 - 将VRAM使用量减少约4倍
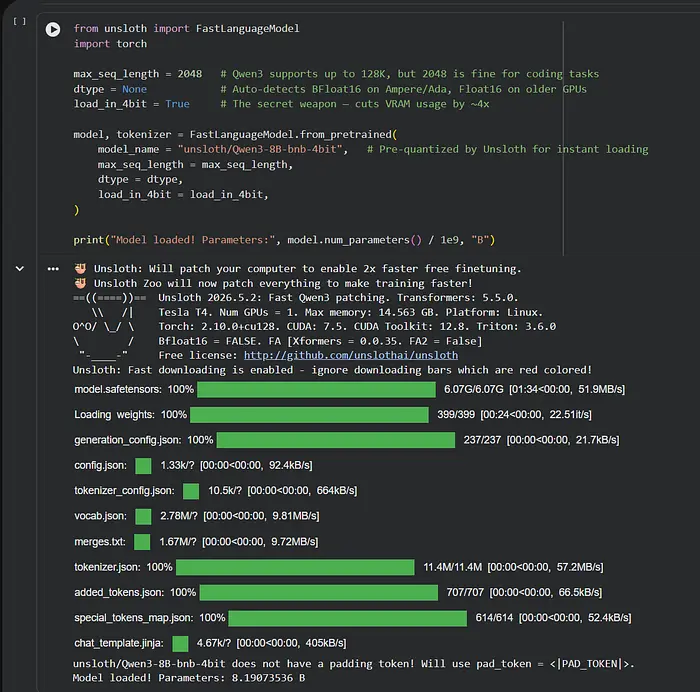
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Qwen3-8B-bnb-4bit", # 由Unsloth预量化,即时加载
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
print("Model loaded! Parameters:", model.num_parameters() / 1e9, "B")
unsloth/Qwen3-8B-bnb-4bit变体由Unsloth团队预量化并直接托管在Hugging Face上。它在Colab上大约60秒内加载——不需要手动量化步骤。
现在附加LoRA适配器——位于冻结基础模型之上的轻量级可训练层:
model = FastLanguageModel.get_peft_model(
model,
r = 16, # LoRA秩。16是一个可靠的默认值。增加到32用于更丰富的任务。
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
lora_alpha = 16,
lora_dropout = 0, # Unsloth推荐0以获得优化性能
bias = "none",
use_gradient_checkpointing = "unsloth", # Unsloth的自定义梯度检查点
random_state = 42,
use_rslora = False,
)
print("Trainable parameters:", sum(p.numel() for p in model.parameters() if p.requires_grad) / 1e6, "M")
你会注意到你大约训练2000万-8000万参数——总共80亿中的。这就是LoRA的魔力。你改变模型的约1%,就能获得完整微调80%以上的效果。
第2步:加载和格式化Python代码数据集
from datasets import load_dataset
from unsloth.chat_templates import get_chat_template
# 将Qwen3的原生聊天模板应用到tokenizer
tokenizer = get_chat_template(
tokenizer,
chat_template = "qwen-2.5", # Qwen3使用Qwen 2.5模板格式
)
# 加载数据集
dataset = load_dataset("iamtarun/python_code_instructions_18k_alpaca", split = "train")
def format_sample(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, context, output in zip(instructions, inputs, outputs):
# 如果存在上下文,合并指令+上下文
if context and context.strip():
user_message = f"{instruction.strip()}\n\nContext:\n{context.strip()}"
else:
user_message = instruction.strip()
# 格式化为Qwen3聊天对话
messages = [
{"role": "user", "content": user_message},
{"role": "assistant", "content": output.strip()},
]
# 应用聊天模板(添加特殊token、角色标记等)
text = tokenizer.apply_chat_template(
messages,
tokenize = False,
add_generation_prompt = False
)
texts.append(text)
return {"text": texts}
dataset = dataset.map(format_sample, batched = True)
print("Formatted sample:\n", dataset[0]["text"][:500])
第3步:配置SFTTrainer和超参数
from trl import SFTTrainer
from transformers import TrainingArguments, DataCollatorForSeq2Seq
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
data_collator = DataCollatorForSeq2Seq(tokenizer = tokenizer),
args = TrainingArguments(
per_device_train_batch_size = 1,
gradient_accumulation_steps = 8, # 有效批大小 = 1* 8= 8
warmup_steps = 10,
max_steps = 100, # 在Colab T4上约9-11分钟。增加到500+用于正式训练。
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 10,
optim = "adamw_8bit", # 8位Adam额外节省约30% VRAM
weight_decay = 0.01,
lr_scheduler_type = "cosine", # 余弦衰减对代码任务效果略好于线性
seed = 42,
output_dir = "qwen3-python-coder",
report_to = "none", # 设置为"wandb"如果你想看训练曲线
),
)
关于max_steps的说明:
100步→ 快速验证。你会看到行为变化,但质量不是最优的。500步→ 良好质量。推荐个人使用。1500-3000步→ 生产级微调。使用Kaggle的30小时免费GPU来做这个。
第4步:训练并观察损失下降
# 显示训练前的GPU内存
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
print(f"GPU: {gpu_stats.name} | Reserved VRAM: {start_gpu_memory} GB")
# 训练
trainer_stats = trainer.train()
# 显示训练后的内存使用
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
print(f"Peak VRAM used: {used_memory} GB")
print(f"Training time: {round(trainer_stats.metrics['train_runtime'] / 60, 2)} minutes")
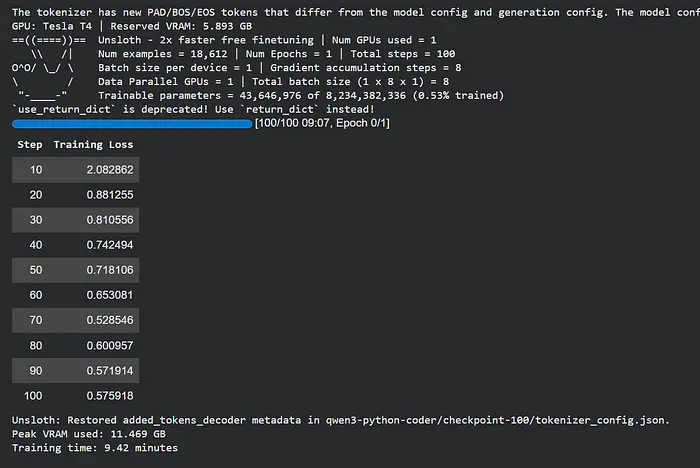
在Colab T4上使用max_steps=100,你通常会看到:
- 峰值VRAM使用: 约11.5 GB(T4的15 GB中)
- 训练时间: 约8-10分钟
- 损失曲线: 从大约1.8-2.2开始,到第100步时降至0.8-1.1
损失下降就是你的模型在学习编码。
第5步:在微调后的模型上运行推理
from transformers import TextStreamer
# 切换到推理模式(Unsloth的2倍加速优化)
FastLanguageModel.for_inference(model)
# 测试提示 - 向你的新编码助手提问真实问题
test_prompt = "Write a Python function that reads a CSV file and returns the top 5 rows with the highest value in a specified column."
messages = [{"role": "user", "content": test_prompt}]
formatted = tokenizer.apply_chat_template(
messages,
tokenize = False,
add_generation_prompt = True,
enable_thinking = False # 设置为True以激活Qwen3的思维链推理模式
)
inputs = tokenizer([formatted], return_tensors="pt").to("cuda")
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
_ = model.generate(
**inputs,
streamer = streamer,
max_new_tokens = 512,
temperature = 0.7,
top_p = 0.9,
)
专业提示: 尝试翻转enable_thinking=True并运行相同的提示。你会看到模型在写代码之前明显地"思考"问题。这是Qwen3的突出特性之一,对于复杂的算法任务确实令人印象深刻。5、保存你的模型并离线使用
你的微调模型现在存在于RAM中。让我们让它永久化。
选项1 - 推送到Hugging Face Hub:
model.push_to_hub("your-username/qwen3-python-coder", token = "YOUR_HF_TOKEN")
tokenizer.push_to_hub("your-username/qwen3-python-coder", token = "YOUR_HF_TOKEN")
选项2 - 导出为GGUF并通过Ollama在本地运行:
# Q4_K_M是社区的首选:最佳质量与大小比
model.save_pretrained_gguf(
"qwen3-python-coder",
tokenizer,
quantization_method = "q4_k_m"
)
从Colab的文件面板下载.gguf文件并在本地机器上运行:
# 创建Ollama Modelfile
echo 'FROM ./qwen3-python-coder.Q4_K_M.gguf' > Modelfile
# 注册并运行
ollama create my-python-coder -f Modelfile
ollama run my-python-coder
你现在拥有一个完全离线运行的自定义Python编码助手,没有API密钥,没有使用限制,没有月费账单。
"使用AI和拥有AI之间的鸿沟刚刚崩塌。你现在站在了正确的一边。"
6、结束语
让我们退后一步看看。
你拿了一个最先进的开源模型。你教它专门做Python编程。你在不花一分钱的硬件上完成了这件事。整个过程花的时间比一顿午餐还短。
同样的工作流程可以扩展到任何场景:
- 在你公司的内部文档上微调 → 一个私有企业助手
- 在医疗问答数据集上微调 → 一个分诊助手(需要适当的安全层)
- 在客户支持工单上微调 → 一个自动首次响应机器人
- 在法律文件上微调 → 一个文档摘要工具
架构完全相同。只有数据集不同。
Unsloth、Qwen3和更广泛的开源生态系统真正实现了模型定制的民主化。剩下的唯一障碍是了解工作流程——现在你已经了解了。
原文链接: Unsloth Just Made Fine-Tuning LLMs a Free-Tier Task
汇智网翻译整理,转载请标明出处
