智能体框架的苦涩教训
所有价值都在经过RL训练的模型中,而不是你那10,000行抽象代码。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
一个agent其实就是一个消息的for循环。agent唯一应该拥有的状态就是:一直运行直到模型停止调用工具。你不需要agent框架。你不需要任何其他东西。它只是一个工具调用的for循环。
我们最早的Browser Use agents有几千行的抽象代码。它们能工作——直到我们尝试修改任何东西。每次实验都在和框架对抗。agents失败不是因为模型笨,而是因为我们自己笨。
坚持看到最后,我会给你展示构建Claude Code有多容易。
1、为什么抽象会破坏学习
抽象的问题在于:它们冻结了对智能应该如何工作的假设。而RL会打破这些假设。
每次你在模型行为周围添加一个“聪明”的包装器——规划模块、验证层、输出解析器——你就是在编码你认为模型应该做什么。但模型是在数百万个例子上训练的。它见过比你能预见到的多得多的模式。你的抽象变成了约束,阻止模型使用它所学到的东西。
机器学习研究中的Bitter Lesson(苦涩教训)很清楚:利用计算的通用方法每次都能击败手工打造的人类知识。agent框架只是这个错误最新的一个例子。
2、99%的工作在模型内部

事情是这样的:99%的工作是在模型自身内部完成的。我们不需要在它周围套一个高度抽象的框架。
现在的Claude Code可以直接编写AppleScript。它需要某个冷门Spotify播放器的信息?它不需要一个Spotify的computer-use工具。它只是在macOS上写AppleScript。它有完美的上下文。它在这方面训练得很好。
你不需要提前预见每一个用例。模型已经知道了。
3、关键洞见
这引出了一个重要结论:
agent框架失败不是因为模型弱,而是因为它们的行为空间不完整。
与其提前定义每一个可能的动作,不如从相反的假设开始:模型几乎什么都能做。然后再加以限制。
给LLM尽可能多的自由,然后基于评估进行“vibe-restrict”(氛围限制)。
4、为什么我们把一切都扔掉了
Browser Use的第一个版本是一个经典的agent框架:一个被复杂消息管理器包裹的模型,里面有很多旨在控制行为的抽象。它能工作,但扩展起来很痛苦。每一次实验都在和框架对抗。添加新能力感觉就像在违背Bitter Lesson。(公平地说,模型从去年以来已经变得好多了)
所以我们后退一步,问了一个更根本的问题:
LLM实际上被训练得极其擅长什么——以及随着模型变得更好,什么会保持不变?
我们扔掉了整个agent,从零开始。为了理解“最小化”真正意味着什么,我们逆向工程了Claude Code和Gemini CLI。向他们致敬,他们创造了真正优秀且大多简洁的原语。虽然它们内部很复杂,但底层理念很简单:
不要过度指定智能——让模型去推理。
5、BU Agent:实际应用
我们把这个理念构建进了BU Agent——一个为Browser Use提供动力的极简agent框架。
我们没有暴露一小套脆弱的“click / type / scroll”原语,而是让BU Agent给模型提供对浏览器原始控制面的访问。
核心是:能够发出纯Chrome DevTools Protocol (CDP)指令的能力。实际上,模型几乎可以在浏览器中做任何事情。
在此之上:浏览器扩展API。它们让某些用CDP单独做起来尴尬或不可能的任务变得 trivial——比如访问活动窗口或处理带权限的浏览器状态。
CDP和扩展API各自都有盲点。但结合在一起,它们形成了一个几乎完整的行为空间。
当模型拥有这种自由时,重要的事情发生了。如果一种方法失败,它会绕过去。如果一个工具坏了,它会找到另一条路径。
只要原则上一切皆有可能,LLM就极其擅长在飞行中自我修复。
6、反转
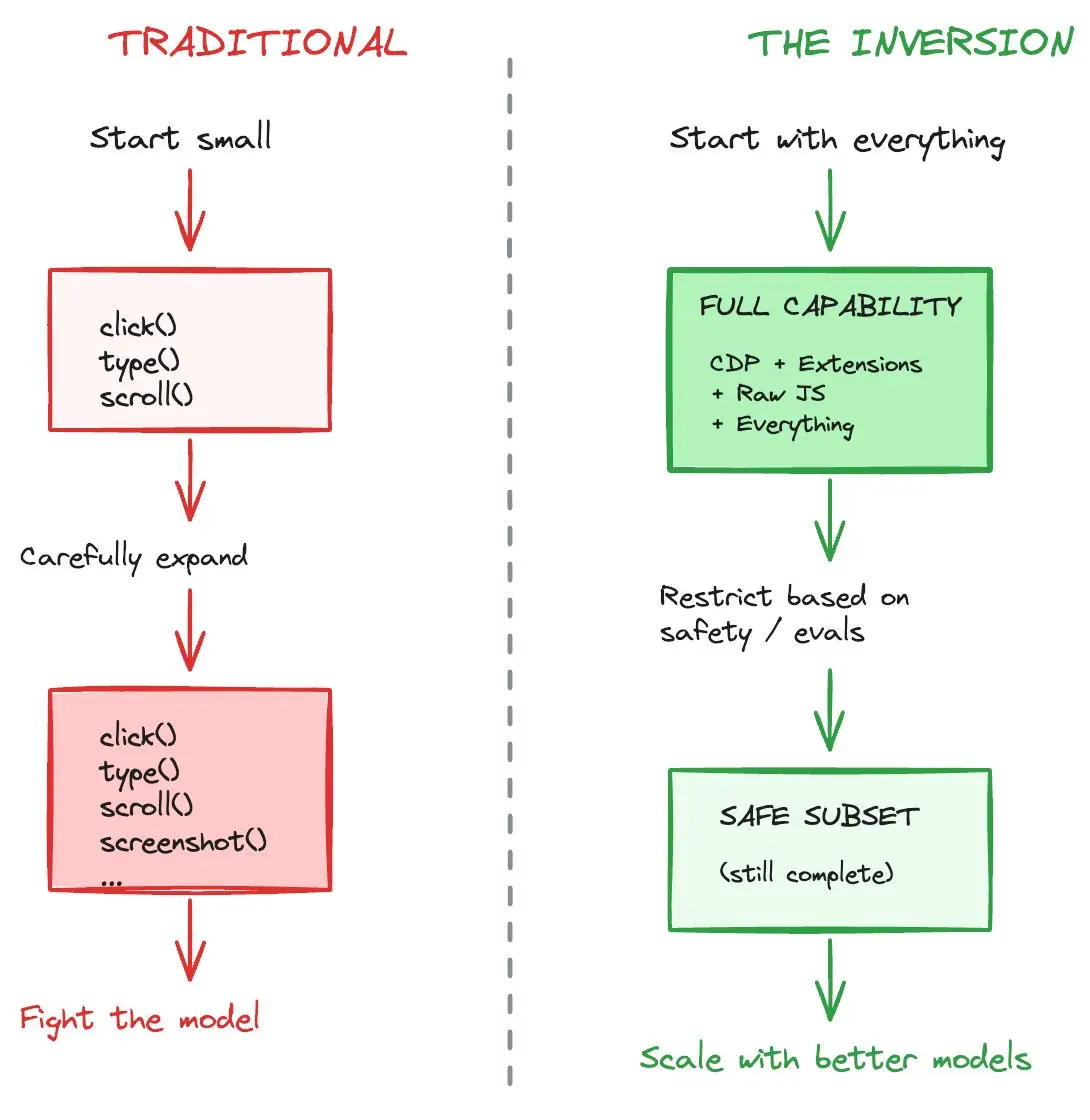
所以BU Agent是基于一个简单的反转构建的:
从最大能力开始,然后再限制。
给模型一个人类在浏览器中能做的任何事情的自由。只有在这之后才叠加安全、结构和约束。
这正是让系统能随着更好模型一起扩展而不是对抗它们的原因。
7、我讨厌其他所有LLM框架
真的。它们实现LLM对象的方式让人痛苦。
所以我写了自己的。超级简单的方式来调用。就这么简单——支持Anthropic、OpenAI和Google。根据我们的遥测数据,这些占了95%的用例。
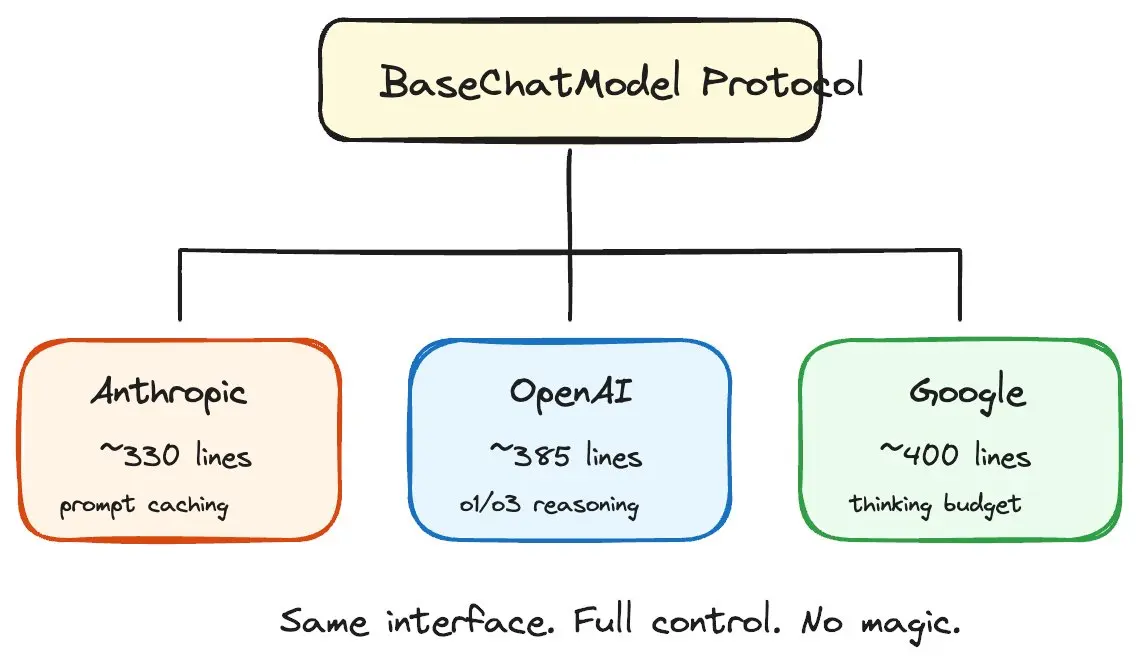
pythonclass ChatAnthropic:
async def ainvoke(self, messages, tools) -> ChatCompletion: ...
class ChatOpenAI:
async def ainvoke(self, messages, tools) -> ChatCompletion: ...
class ChatGoogle:
async def ainvoke(self, messages, tools) -> ChatCompletion: ...同样的接口。对缓存、序列化、提供商 quirks 有完全控制。没有魔法。没有意外。
自己做缓存和实现消息要容易得多。完全模型无关。你不会被锁定在一个提供商。你自己决定。
8、临时消息(Ephemeral messages)
我们为浏览器agents需要的一个有趣东西:如果你请求浏览器状态,它非常庞大。DOM快照、截图、元素索引——每次请求很容易50KB+。
如果没有临时消息,会发生什么:经过10次浏览器交互后,你的上下文里就有500KB的状态。20次后就到了1MB。模型开始失去连贯性。它忘记了原始任务。它会幻觉已经不存在的元素。最终你达到上下文限制,整个东西崩溃。
所以我引入了临时消息。
@tool("Get browser state", ephemeral=3) # Keep last 3 only
async def get_state() -> str:
return massive_dom_and_screenshot如果你定义某个工具调用了X次,它就会移除所有之前的输出。会稍微破坏一点缓存。但这是一个非常好的权衡——LLM反正无法真正处理海量上下文。模型只需要最近的状态;旧的浏览器快照只是噪声。
9、for-loop行不通(直到你修复它)
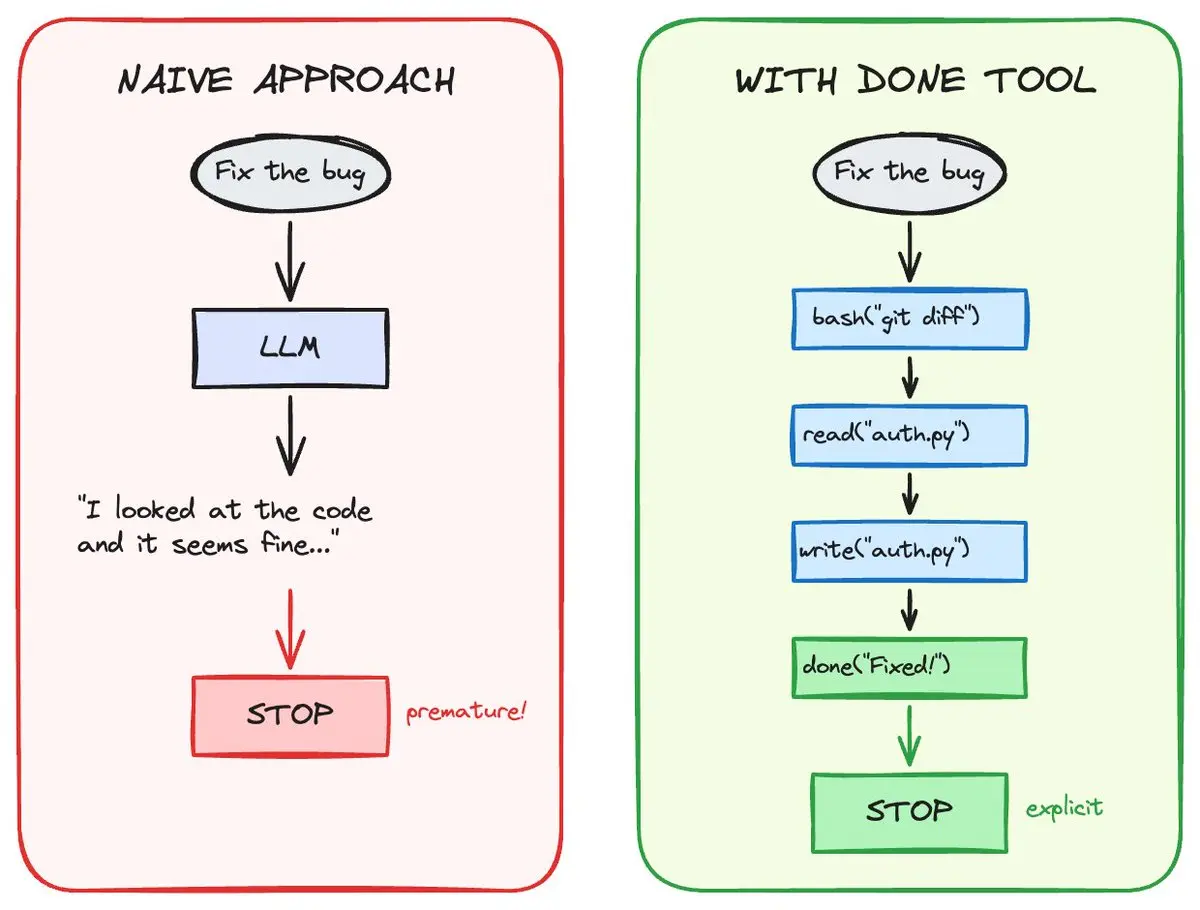
天真的做法——当模型返回没有工具调用时就停止——效果不好。agents会过早结束。尤其是当它们缺少某些上下文时。你想要一个跟进,但如果你用这种API,就不可能。
最好的修复方式是done tool。
@tool('Signal that the current task is complete.')
async def done(message: str) -> str:
raise TaskComplete(message)当模型输出一个done工具调用时,agent就终止。这迫使它显式完成,而不是隐式的“我猜我们做完了?”
我们有两种模式:
- CLI模式:当LLM返回没有工具调用时停止(快速交互)
- 自主模式:仅在显式done()调用时停止
Claude Code就是这么做的。Gemini CLI也是这么做的。现在你知道它为什么存在了。
10、但你需要可靠的基础设施
是的。for-loop很简单。让它可靠却不容易:
- 指数退避的重试
- 速率限制处理
- 连接恢复
- 上下文压缩
- Token跟踪
这是运维。已经解决的问题。必要——但不要把它和agent本身混淆。
11、苦涩的真相
每一个抽象都是负债。每 一个“helper”都是故障点。
模型已经变好了。真的很好。它们在computer use、coding、browsing上经过了RL训练。它们不需要你的护栏。它们需要的是:

苦涩的教训:你构建得越少,它工作得越好。
我们正在把这个开源为agent-sdk。
如果你想,你可以在生产环境中使用它,但最好只是把上下文粘贴到Claude Code里,用你正在编码的任何语言自己做一个。仓库里也包含了一个Claude Code重新实现的例子。
总之,这就是我们在构建bu.app时学到的东西。去试试吧。它很棒!!
原文链接:The Bitter Lesson of Agent Frameworks
汇智网翻译整理,转载请标明出处
