Qwen3-VL-8B医疗数据集微调
我们将在医学影像QA数据集上微调Qwen3-VL-8B,然后使用生成的模型来理解从真实临床病例报告中提取的图像。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
继我们之前探索"多模态大型语言模型:架构、训练和实际应用"之后,我们现在来解决这一广阔领域的一个实际方面。尽管MLLM涵盖了所有包含多模态输入(主要)和输出的模型类型,但在本文中,我们将学习如何在文档理解背景下使用视觉语言模型(VLM)。
1、我们要构建什么
接下来,我们将在医学影像QA数据集上微调Qwen3-VL-8B,然后使用生成的模型来理解从真实临床病例报告中提取的图像。这是一个完整的流水线,从原始数据到结构化输出。
这两个任务自然地相互映射:
- VQA教模型用临床语言对医学图像进行推理。
- 文档理解是这种推理发挥作用的地方。
正如我们最后将看到的,结果在多个方面都很有趣且具有启发性。
完整代码可在Colab notebook上获取,您可以使用免费的T4 GPU运行它。
2、数据集:MedPix-VQA
MedPix-VQA基于MedPix医学图像数据库构建,这是一个广泛使用的注释临床病例资源,涵盖广泛的成像模式和病理。VQA formulation将这些图像与临床问答配对,使其非常适合训练模型产生基于证据的、术语感知的图像描述。
由于硬件限制(稍后会详细介绍),我们在30%的训练数据上进行了训练。
from datasets import load_dataset
# Load VQA dataset
qa_dataset = load_dataset("mmoukouba/MedPix-VQA", split = "train[:30%]")
该数据集可在HuggingFace Hub上获取。
预处理
为了使数据集准备好进行训练,我们需要为每个实例创建一个QA对话场景。
def convert_to_conversation(sample):
conversation = [
{ "role": "user",
"content" : [
{"type" : "text", "text" : sample["question"]},
{"type" : "image", "image" : sample["image_id"]} ]
},
{ "role" : "assistant",
"content" : [
{"type" : "text", "text" : sample["answer"]} ]
},
]
return { "messages" : conversation }
pass
converted_dataset = [convert_to_conversation(sample) for sample in qa_dataset]
以下是预处理输入的示例:
{'messages': [{'role': 'user',
'content': [{'type': 'text',
'text': ' How does the interhemispheric fissure appear in this image?'},
{'type': 'image',
'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=441x475>}]},
{'role': 'assistant',
'content': [{'type': 'text',
'text': ' The anterior interhemispheric fissure is partially formed, but the rest of the fissure is not visible.'
}]}]}
3、模型:Qwen3-VL-8B-4bit
在这个微调实验中,我们使用unsloth/Qwen3-VL-8B-Instruct-unsloth-bnb-4bit,这是通过Unsloth分发的Qwen3-VL-8B的预量化4位版本。
Unsloth是一个允许快速训练和推理LLM的库,我们可以使用transformers来微调模型,但与免费Colab版本相比,这需要更多的GPU时间。但是,如果您要在其他地方运行代码,我强烈建议使用带有flash attention 2的transformers。
Qwen3是一个开放的视觉语言模型,具有强大的视觉编码器和足够大的语言骨干来处理细微的临床语言。Unsloth版本预量化 为4位NF4,并针对消费级硬件上的高效微调进行了优化。
微调使用QLoRA,rank为32,应用于所有层类型:视觉、语言、注意力 和MLP。
这是一种比典型的仅注意力LoRA更激进的调优策略,在这里是有意义的,因为我们不仅希望模型调整其路由注意力的方式,还希望所有可用层都专门用于医学影像理解。
注意:虽然在本例中我们主要使用默认参数以保持简单,但实际部署需要严格的超参数优化以确保模型达到最佳性能。
from unsloth import FastVisionModel
import torch
model, tokenizer = FastVisionModel.from_pretrained(
"unsloth/Qwen3-VL-8B-Instruct-unsloth-bnb-4bit",
load_in_4bit = True,
use_gradient_checkpointing = "unsloth",
)
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers = True,
finetune_language_layers = True,
finetune_attention_modules = True,
finetune_mlp_modules = True,
r = 32,
lora_alpha = 32,
lora_dropout = 0,
bias = "none",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
训练在免费的Colab T4 GPU上运行了2小时,对30%的训练数据进行了1个epoch。
4、OCR:从病例报告中提取内容
对于文档理解步骤,我们使用已发布的病例报告" Lateral Sphenoidal Encephalocele as an Uncommon Cause of Trigeminal Neuralgia",这是一个涉及脑组织通过蝶骨缺损疝出的罕见神经外科病例。我们稍后会解释标题中那个uncommon*词的重要性。
对于OCR,我们使用免费的Mistral OCR API(mistral-ocr-latest)。它是一个文档级模型,能很好地处理复杂布局,关键对我们的用例,它返回嵌入图像为base64编码的字符串以及提取的文本,因此无需单独处理图像提取。此外,我们使用API进行OCR,因为我们在RAM和VRAM方面再次受到限制,只能在本地运行一个模型。
client = Mistral(api_key="API_KEY")
pdf_file = "/content/JRCR+20-2-5907+(2).pdf"
uploaded_pdf = client.files.upload(
file={
"file_name": "JRCR+20-2-5907+(2).pdf",
"content": open(pdf_file, "rb"),
},
purpose="ocr"
)
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": signed_url.url,
},
table_format="html",
include_image_base64=True
)
for i, page in enumerate(ocr_response.pages):
print(f"--- Page {i+1} ---")
print(page.markdown)
5、推理和结果
我们从病例报告中提取了MRI图像,并向微调后的模型查询:"影像中观察到了什么?"
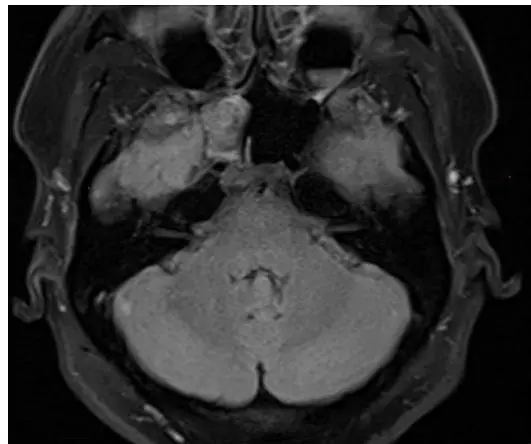
来自真实医学病例的测试图像
instruction = "What was observed in the imaging?"
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": instruction}
]}
]
input_text = tokenizer.apply_chat_template(messages, add_generation_prompt = True)
inputs = tokenizer(
pil_image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to("cuda")
response = model.generate(**inputs, max_new_tokens = 128,
use_cache = True, temperature = 0.1, min_p = 0.1)
decoded_resp = tokenizer.decode(response[0], skip_special_tokens = True)
作为参考,以下是三个来源对同一图像的说法:
ChatGPT (GPT-5.3)
这是后颅窝水平的轴向脑MRI。脑干两侧有两个相当对称的大肿块,位于小脑桥角。病变看起来是脑外的,正在压迫小脑和脑干等附近结构。
我们的微调模型
右侧小脑桥角区域的大肿块。肿块在T1上与灰质等信号,在T2上高信号,钆增强明显。肿块延伸至右侧内耳道,似乎包裹了右侧第八颅神经。
真实标签(来自论文)
冠状位T2加权MRI显示脑室和颞叶的高分辨率可视化,有证据表明脑组织疝出至蝶窦右侧隐窝。
显然,微调后的模型和ChatGPT都错了。
但在分析输出之前,值得诚实地说。
我们的模型从未真正有望正确做到这一点,原因如下:
- 我们通过"预算"训练运行推送了一个8B模型(4位量化):在30%的数据上使用LoRA进行一个epoch。这意味着我们在对架构进行压力测试,而不是追求金标准准确性。
- 该任务涉及蝶骨脑膨出,这是从最近的医学病例中获取的罕见病理,这意味着它很可能不在训练分布中。
然而,在比较ChatGPT和我们的模型的响应时,值得注意的是:
- ChatGPT识别了"双侧小脑桥角肿块"。它本质上是对一种常见病理(听神经瘤)进行模式匹配,但完全错误。
- 我们的微调模型犯了类似的定位错误,但采用了专业的放射学术语。它利用了结构化信号表征(T1/T2强度、钆增强)和临床术语,与真实标签中使用的类似。
6、构建智能医学文档分析器
演示很好。但在医疗等关键领域,真正的工程挑战是构建可靠的系统。我们的模型,如果训练得当,可以作为专业工具。
GPT或Claude等前沿模型是出色的编排器,这意味着它们可以处理OCR、逻辑和摘要的重活。但它们缺乏专业成像所需的"临床眼光"。这正是我们模型的用武之地。
工作流程
- 编排器:一个代理处理医学PDF,提取文本和图像。
- 交接:当代理遇到复杂扫描时,它不猜测。它将我们的微调VLM作为工具调用。
- 结果:我们的模型返回专业、结构化的描述,然后代理将其编织回最终分析。
这是使用通才来管理项目,使用专家来读取扫描。关注点的分离很重要。这意味着您可以独立改进图像描述组件(更多训练数据、更大的基础模型、DPO对齐),而无需触及编排逻辑。
这也意味着编排器可以交叉引用图像发现与OCR提取的临床文本,发现任何一个组件单独不会发现的矛盾。
这是一种常用的代理架构,在许多应用中证明了它的价值。
原文链接: Multimodal Large Language Models: A Practical Example
汇智网翻译整理,发表于汇智网
