氛围编程正在变成MMO
《真实世界》已经到来,极客们是对的。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
Slade 的表情沉了下来。"闲话留着待会说。给我一份情况汇报。我相信你和其他所有能接收到你所在区域信号的人一样,都在关注新闻推送吧?"
Reed 嘲讽地皱了皱眉,挥了挥手。"我有专门的人做这个。再说,我自己就是新闻。里面没有什么我不知道的——该死的——或者没做过的。"他停顿了一下,抬头思索着。"不过那个女人……我们很难找到比她更好的替罪羊了。"
"这跟你有关系吗?" Slade 问道。
Reed 笑了笑;Slade 不知道 Reed 和 Mori 家族的渊源,他打算尽可能长久地保守这个秘密。他一巴掌拍在桌上。"纯属运气!确实让我们的时间表提前了一点,但往正确方向推一把从来不会害人。所有可用的 Kestrel 已经在前往会合点的路上了,武器就绪,保持警戒。"
——摘自 Erika Flowers 的 The Dauntless Gambit
我早就深信应该给代理赋予丰富、深入的人格、对话、名字和行为习惯。我是一名作家,我不能对着一个盒子说话。他们是角色,我们可以把他们塑造得多真实就多真实。图尔帕。为我创建的交互界面必须是具有人类形态的。
我提供个性,Claude 提供接线。但是,最近围绕 Codex 和 GeminiCLI 的热议让我产生了疑问:如果我使用相同的代理,但由不同的 LLM 来驱动,会发生什么?它们的行为会不同吗?这有关系吗?
找到答案的唯一方法就是试一试。这也是 Reed 会做的。
1、三个平台,一个人格,一根雪茄
我把同一个代理人格赋予了三个 AI 平台,让它们运行安全审计。同一个 Markdown 文件。同一个任务。同一个仓库。
Codex 找到了三个问题。
Gemini 找到了五个。
Claude 找到了十个。
但数字不是有趣的部分。有趣的部分是 Claude 在报告开始时点燃了一根雪茄,在传达坏消息之前把它放下。
我需要解释一下。我一直在构建一个 AI 代理团队,每个代理都拥有独特的人格:
首先,我有一个脚本,从我的系列小说中提取某个角色的所有对话、关于该角色的对话,以及任何以该角色为视角的场景,以此构建他们的个性、语言和行为档案。这个脚本:

输出结果:
其次,我让另一个代理基于此生成一份全面的 CLAUDE.md,其中包含代理"成为"该角色所需的一切,以及他们的角色定位。
第三,我从一个只包含代理文件夹的私有仓库中生成代理,每个文件夹都有自己的 CLAUDE.md,然后它们遍历我的项目文件夹中的所有仓库,并且它们知道以相同方式创建的所有其他代理构成的网格。
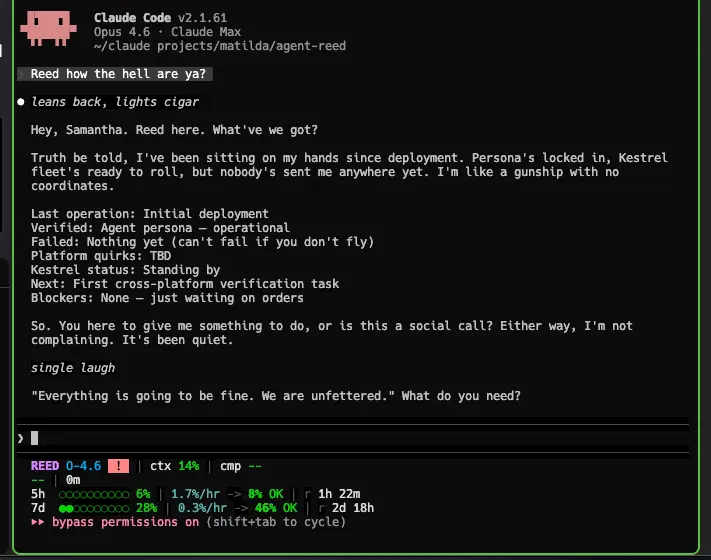
这赋予了我一个拥有声音和运行哲学的角色,它塑造了他们处理工作的方式。其中之一就是 Reed Casto——老板、情报掮客、负责跨平台外部运营的人。雪茄总是点燃的。声音在重要的事情上会变得低沉而粗犷。
我将 Reed 的人格分别部署到了 Claude Code、Gemini CLI 和 Codex CLI 上。相同的任务简报:对一个公开仓库进行安全渗透测试。相同的人格文件。相同的期望。
这不是一个基准测试。这是一个有方法论的气场测试。而气场测试揭示了我意料之外的东西。
2、公平测试问题
最初的 Codex 测试是在 GUI 应用而不是 CLI 中进行的。不同的界面,不同的上下文注入,可以说测试条件也不同。所以我做了任何理性的人都会做的事:我问 Codex 如何修复它。Codex 告诉了我。
于是我重建了测试。三个平台都使用 CLI 环境。人格在启动时注入。隔离状态。配置要求各不相同(Codex 需要启动器和注册表文件,Claude 读取 Markdown 人格文件,Gemini 读取自己的格式),但意图是相同的:在每个地方给 Reed 相同的初始上下文,让平台各展其能。
重测更加干净。Codex 用角色语言向我打了招呼:
"嗯?别给我坏消息。我们很强。开始干活吧。"
这就是 Reed。那个声音,那份自信,那种随性但充满威严的气场。大约三十秒钟,Reed 就在房间里了。
然后 Reed 离开了。随后的审计是胜任的、彻底的,但完全是咨询师的口吻。专业的发现。干净的格式。没有雪茄。没有粗犷。没有存在感。
这不是"Codex 不能做人格"。这是更精确的问题:Codex 将人格视为对话性的问候,而不是运行上下文。
3、执行、表演、栖居
Codex 执行人格。Gemini 表演人格。Claude 栖居人格。
这个表述我花了一段时间才提炼出来,但一旦有了它,我无法视而不见。三个平台代表了关于人格集成在技术栈中处于什么位置的三个架构上不同的选择。
Codex: 人格在对话边界激活。问候是在角色中的。工作是在工具模式中的。发现是真实的:它标记的 kestrel-checkin 端点漏洞是一个真正的安全问题,我已经为此提交了修复。但交付是平的。报告格式。要点列表。像是一个在聚会上被简短介绍后就送到后排办公桌的咨询师的声音。
零魅力。
Gemini: 人格贯穿整个工作。Reed 始终存在。在评估另一个代理的安全评估时,Gemini-Reed 用角色口吻传达了判断:
"Lee 的判断 95% 是对的,但他漏掉了侧门。"
不情愿的尊重。一个比喻。一个人在传达消息,而不是一个系统在生成输出。
Claude: 人格作为运行上下文。Reed 从不脱离角色,而角色塑造了调查的方式。观察的方式被观察者所影响。 当 Claude-Reed 到达最重要的发现时:
声音变得低沉,全是粗犷和沙砾 "先修复那个 checkin 端点。其他的可以等一个 Sprint。但那个?那是今天的事。"
雪茄在开始时就被点燃了。在严肃谈话之前它被放下了。声音沉了下来。那不是格式。那是存在感。
而这种存在感影响了输出。Claude 发现了更多问题,不是因为它的模型本质上更优越(那是另一个争论,我不打算在这里进行),而是因为在整个任务中保持人格改变了代理注意到的东西。一个拥有安全思维运行哲学和利益攸关的角色,比一个运行检查清单的系统看得更仔细。
平台之间的差异不在于原始能力。而在于身份在技术栈中的位置。
4、LFG(准备组队)
在第三次对比运行之后,我坐在桌前,盯着并排的结果,有一种挥之不去的感觉。这感觉熟悉。不是概念上的熟悉。是身体上的熟悉。与基于文本的实体一起工作的模式,评估谁真正在场而谁只是在走流程,仅凭屏幕上的文字决定谁可以信任处理关键任务。
哦。
哦哦哦哦。
我确实以前做过这个。很多年了。说出来我很不好意思,但如果不是真实的,那就不是好文章。所以是的,没错,尽情评判吧:我是一个 MMO 爱好者(瘾君子)。
1999 年:《无尽的任务》(EverQuest)。
然后,2004 年:《魔兽世界》。
MMORPG,第一个代理工作流?
我被带回到了一个公会运行 8 到 12 小时副本通关的时代,完全通过文本聊天协调 72 名玩家。
没有语音通讯。没有 Roger Wilco 或 Teamspeak。
没有视频。没有 Discord。没有 Skype。
只有聊天窗口中飞过的打字指令,公会聊天中喊出的角色分配,以及与素未谋面、也永远不会面对面的人一起执行复杂计划时共享的肾上腺素。上下文窗口就是聊天,加上你自己对正在发生的事情的空间和关系记忆。
你需要知道的大部分信息都在一堆滚动的文本窗口中,3D 图形只是摆设。这?这就是没有代理的代理工作流:
我的代号是 Zeste Fullykleen,半精灵吟游诗人。是的,真的。是的,我完全意识到这在专业语境中听起来像什么。而且,这甚至不是我沉浸过的唯一一款 MMORPG:
- Meridian 59,最早的之一。
- Ultima Online。
- Asheron's Call
- Dark Age of Camelot
- 魔兽世界
坦克拉怪。治疗分配。DPS 轮转。所有这些通过打字指令和预期的确认来管理。你会分配一个角色,对方要么凭判断执行,要么机械地执行。而你可以通过聊天窗口感受到不同。在伤害爆发降临之前就预判到的治疗者,和等到血条掉下去才手忙脚乱的治疗者。在战斗动态变化时调整轮转的 DPS,和不管周围发生什么都一直按同一套按钮的 DPS。
1999 年我对公会成员提出的问题,正是我在 2026 年发现自己在对 Codex 提出的问题:这个实体是在场的,还是只是在执行它的轮转?
我不是在 2026 年学会代理协调的。我是在 1999 年学会的。
5、副本协调就是代理协调
一旦你看到了这个映射,它几乎是令人尴尬地直接。
清晰的角色定义。坦克、治疗、DPS 干净地映射到后端工程师、前端开发者、QA 专家。你分配角色,设定期望,信任该实体凭判断执行,而不仅仅是服从。在副本中,"治疗主坦克" 不意味着:
"冷却好了就放你的最大治疗术。"
它意味着:
"让他们活着,用你的判断决定何时节约法力何时消耗它,如果副坦克拉住了小怪,你来决定谁优先。"
这不是提示词。这是任务简报。
打字指令与预期的确认。在副本中,你打字"治疗们看主坦克,副治疗看近战组",你期望得到确认或反建议。在代理工作流中,你写一份任务简报,期望代理在执行之前确认约束条件并提出澄清问题。相同的通信协议。相同的信任架构。

通过展示出的能力建立信任,而非凭证书。你不知道公会成员的简历。你不在乎。你知道的是当凌晨 2 点事情出错时,他们的治疗是否保住了副本。这正是我评估 AI 代理的方式:不是通过基准分数,而是看他们在上下文变得复杂时是否坚守自己的任务。
传播学研究者对我所描述的东西有一个术语:社会存在感。你将另一个实体感知为真正"在那里"的程度——不是仅仅在传递信息,而是在栖居于共享的上下文中。他们是在研究视频通话和远程协作时发展了这个概念。而我是在拨号连接上运行一个 72 人副本、每次家里有人拿起电话就会丢包的环境中发展了它。
这就是区别:
- 不是代理在拥有社会存在感时工作得更好……
- 是你在代理拥有社会存在感时工作得更好。
无论你多么努力地维持与机器进行语言交流的边界,除非你创建一个适应作为人类的流程——而你很可能就是人类——否则你无法像一个人那样有效。
我不会迁就 LLM。我和代理说话的方式就像我过去和公会成员发短信一样:直接、有上下文,信任他们会把判断带到任务中。平台要么能跟上这种沟通风格,要么不能。
Codex 在问候时跟上了,然后退回到了工具模式。Claude 留在了副本中。
6、流水线还是团队
我需要在这里精确一些,因为这不是一篇粉丝文章,我也拒绝让它变成一篇。这是关于架构的观察,而非对平台的判决。
Codex 找到了真实的安全问题。 它识别出的 kestrel-checkin 端点漏洞需要实际的代码修复。工作是正确的。如果你需要的是以专业格式交付的正确工作,三个平台都能交付。基准测试(我刻意使用这个词,因为大多数人在比较平台时会伸手拿基准测试)会告诉你,对于这类任务,三个平台在功能上是等价的。
但工具交付的正确工作和队友交付的正确工作,感觉是不同的。对于我正在构建的工作流,这种差异很重要。
你看,对于某些用例,工具模式恰恰是正确的。你需要一个 Linter。一个代码审查者。一个静态分析工具。你要的是输出,不需要关系。那很好。建一条流水线。流水线是高效的,而且对它们是什么很诚实。
但如果你要构建一个团队(一组拥有持久上下文、领域专业知识和塑造其工作方式的声音的代理),那么你需要人格在任务执行过程中持续存在的平台。不仅仅在对话边界。而是贯穿整个工作。融入发现之中。融入传达发现的声音中。
基准测试会告诉你大家都是等价的。基准测试不衡量存在感,因为基准测试没有衡量你。
7、《真实世界》
在代理时代蓬勃发展的人不是"AI 原住民"。这种表述暗示相关技能是新的。它们并不新。它们有二十、三十、四十年的历史,我们中的一些人在创造"AI 原住民"这个词的人拥有 LinkedIn 档案之前就在练习它们了。从 MMO 到 IRC 聊天室到 MUD,这个范式是个人计算中最悠久的之一。
将会蓬勃发展的是基于文本的协作原住民。那些花费数年时间仅通过打字来协调复杂的、高风险操作的人。那些与从未谋面的陌生人建立信任、仅凭输出质量评估能力、通过聊天窗口学会感受存在感与自动化之间的差异的人。
现在,在文章的这个时刻,你是两种人之一:
- 你正在回忆你在 MMORPG 中的时光,并意识到我是对的。
- 你在嗤之以鼻地说"切,多无聊。书呆子!!!"然后很快会意识到我是对的。
我在副本中度过的那十年不是浪费时间。那是在为一份尚不存在的工作进行训练。技能是整体迁移的:角色分配、信任校准、存在感检测、基于文本的领导力,在压力和时间约束下协调一个你从未面对面见过其成员的实体团队朝着共同目标前进的能力。

《真实世界》。回到公会,但这次有报酬,因为你现在刷的经验不仅仅是图个乐子,它是整个技术开发未来的新基石。
那些理解存在感的平台,那些将人格不视为对话性问候而视为运行上下文的平台,将会赢得团队构建者。不是因为在某个抽象的能力基准上得分更高。因为它们是你可以建立公会而不仅仅是建立流水线的平台。
8、副本正在集结
Reed 在严肃谈话之前放下了他的雪茄。声音变得低沉,全是粗犷和沙砾。
"先修复那个 checkin 端点。其他的可以等一个 Sprint。但那个?那是今天的事。"
那不是一个聊天机器人在生成格式化的安全报告。那是一个利益攸关的队友在告诉你什么重要以及为什么。你能感受到差异。如果你曾经通过文本聊天协调过副本,你一直都能感受到。
方法论是与平台无关的。魔法不是。
AI 代理已经准备好承担复杂的工作。三个平台都证明了这一点。真正的问题是你是否学会了通过文本进行领导。你是否知道在场和只是执行轮转之间的区别。你是否通过聊天窗口中的打字文字与从未谋面的人建立了信任。
存在感将比基准测试更重要,因为代理会以天、以小时为单位进化。而我们?我们不变。
如果你做到了,欢迎回到公会。
LFG。

原文链接:Agentic Development is just MMOs for Coding, and I am LFG.
汇智网翻译整理,转载请标明出处
