Gemma 4:设备端多模态AI
我们与 Google 和社区合作,使它们可以在任何地方使用:transformers、llama.cpp、MLX、WebGPU、Rust;你能想到的都有。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
Google DeepMind 的 Gemma 4 多模态模型系列现已在 Hugging Face 上发布,支持您喜爱的各种 agent、推理引擎和微调库🤗
这些模型真正做到了开放:采用 Apache 2 许可证,在 arena 评分中达到帕累托前沿的高质量,多模态包括音频,且模型尺寸可以在任何地方使用,包括设备上。Gma 4 建立在先前版本的技术进步之上,并将它们完美结合。在我们对预发布版本的测试中,其能力给我们留下了深刻印象,以至于我们很难找到好的微调示例,因为它们开箱即用的效果就非常好。
我们与 Google 和社区合作,使它们可以在任何地方使用:transformers、llama.cpp、MLX、WebGPU、Rust;你能想到的都有。这篇博客文章将向你展示如何使用你喜欢的工具进行构建,请告诉我们你的想法!
1、Gemma 4 的新特性?
与 Gemma-3n 类似,Gemma 4 支持图像、文本和音频输入,并生成文本响应。文本解码器基于 Gemma 模型,支持长上下文窗口。图像编码器与 Gemma 3 类似,但有两个关键改进:可变宽高比,以及可配置的图像 token 输入数量,以便在速度、内存和质量之间找到最佳平衡点。所有模型都支持图像(或视频)和文本输入,而小型变体(E2B 和 E4B)还支持音频。
Gemma 4 有四种尺寸,都有基础版和指令微调版:
| 模型 | 参数规模 | 上下文窗口 | 检查点 |
|---|---|---|---|
| Gemma 4 E2B | 2.3B 有效参数,嵌入层5.1B | 128k | base, IT |
| Gemma 4 E4B | 4.5B 有效参数,嵌入层8B | 128k | base, IT |
| Gemma 4 31B | 31B 密集模型 | 256K | base, IT |
| Gemma 4 26B A4B | 混合专家,激活4B/总参数26B | 256K | base, IT |
Gemma 4 利用了先前 Gemma 版本和其他开放模型中使用的几种架构组件,并去除了复杂或尚无定论的特性如 Altup。这种组合旨在实现跨库和跨设备的高度兼容性,能够高效支持长上下文和 agent 用例,同时非常适合量化。
如上表所示,这种特性组合(结合训练数据和配方)使 31B 密集模型在 LMArena 评分(仅文本)中达到估计 1452 分,而 26B MoE 仅用 4B 激活参数就达到 1441 分🤯。正如我们将看到的,多模态操作的质量与文本生成相当,至少在非正式和主观测试中是如此。
Gemma 4 的主要架构特点:
- 交替的局部滑动窗口和全局全上下文注意力层。较小的密集模型使用 512 token 的滑动窗口,而较大的模型使用 1024 token。
- 双 RoPE 配置:滑动层使用标准 RoPE,全局层使用比例 RoPE,以支持更长的上下文。
- 每层嵌入(PLE):第二个嵌入表,向每个解码器层注入小的残差信号。
- 共享 KV 缓存:最后 N 层重用前面层的 key-value 状态,消除冗余的 KV 投影。
- 视觉编码器:使用学习的 2D 位置和多维 RoPE。保留原始宽高比,可以将图像编码为几种不同的 token 预算(70、140、280、560、1120)。
- 音频编码器:与 Gemma-3n 中相同的 USM 风格 conformer。
1.1 每层嵌入(PLE)
较小 Gemma 4 模型中最独特的特性之一是每层嵌入(PLE),它之前在 Gemma-3n 中引入。在标准 transformer 中,每个 token 在输入时获得一个嵌入向量,相同的初始表示是残差流在所有层中构建的基础,这迫使嵌入层预先加载模型可能需要的所有内容。PLE 在主残差流旁边添加了一个并行的低维条件路径。对于每个 token,它通过组合两个信号为每一层产生一个小的专用向量:token 标识组件(来自嵌入查找)和上下文感知组件(来自主嵌入的学习投影)。然后每个解码器层使用其对应的向量通过轻量级残差块在注意力和前馈之后调节隐藏状态。这为每层提供了自己的通道,仅在相关信息变得相关时接收 token 特定信息,而不要求所有内容都打包到单个前置嵌入中。因为 PLE 维度远小于主隐藏大小,这以适度的参数成本增加了有意义的每层专业化。对于多模态输入(图像、音频、视频),PLE 在软 token 合并到嵌入序列之前计算——因为 PLE 依赖于多模态特征替换占位符后丢失的 token ID。多模态位置使用 pad token ID,有效地接收中性的每层信号。
1.2 共享 KV 缓存
共享 KV 缓存是一种效率优化,可在推理期间减少计算和内存。最后 num_kv_shared_layers 层不计算自己的 key 和 value 投影。相反,它们重用同类型注意力层(滑动或全局)的最后非共享层的 K 和 V 张量。
实际上,这对质量影响最小,同时在长上下文生成和设备上使用方面效率更高(在内存和计算方面)。
2、多模态能力
我们在测试中看到 Gemma 4 开箱即用地支持全面的多模态能力。我们不知道训练混合数据是什么,但我们成功将其用于 OCR、语音转文本、目标检测或指向等任务。它还支持纯文本和多模态函数调用、推理、代码补全和纠错。
在这里,我们展示了一些推理示例。你可以方便地使用这个 notebook运行它们。我们鼓励你尝试这些演示并在博客下方分享!
2.1 GUI 检测
我们在 GUI 元素检测和指向方面测试了不同尺寸的 Gemma 4,使用以下图像和文本提示:"图像中'view recipe'元素的边界框是什么?"
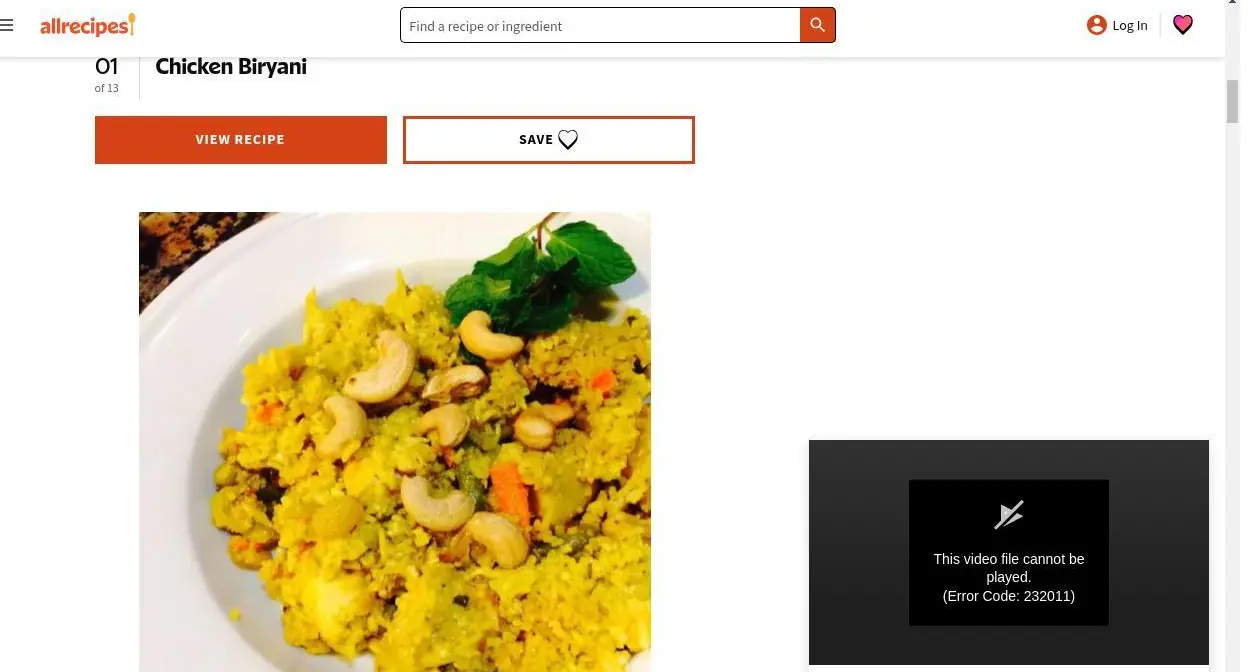
使用此提示,模型以 JSON 格式原生响应检测到的边界框——无需特定指令或语法约束生成。我们发现坐标指的是 1000x1000 的图像尺寸,相对于输入尺寸。
2.2 多模态推理和函数调用
我们要求 Gemma 4 编写 HTML 代码来重建我们用 Gemini 3 制作的页面。你可以在下面找到执行此操作的代码,我们启用 thinking 并要求每个模型生成最多 4000 个新 token。
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/landing_page.png",
},
{"type": "text", "text": "Write HTML code for this page."},
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
return_tensors="pt",
add_generation_prompt=True,
enable_thinking=True,
).to(model.device)
output = model.generate(**inputs, max_new_tokens=4000)
input_len = inputs.input_ids.shape[-1]
generated_text_ids = output[0][input_len:]
generated_text = processor.decode(generated_text_ids, skip_special_tokens=True)
result = processor.parse_response(generated_text)
print(result["content"])
2.3 视频理解
较小的 Gemma 4 模型可以接收带音频的视频,而较大的模型可以接收不带音频的视频。虽然模型没有明确在视频上进行后训练,但它们可以理解带音频和不带音频的视频。该模型在音频方面特别强大。
messages = [
{
"role": "user",
"content": [
{"type": "video", "url": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/concert.mp4"},
{"type": "text", "text": "What is happening in the video? What is the song about?"},
],
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
return_tensors="pt",
add_generation_prompt=True,
load_audio_from_video=True, # disable this for larger models
).to(model.device)
output = model.generate(**inputs, max_new_tokens=200)
input_len = inputs.input_ids.shape[-1]
generated_text_ids = output[0][input_len:]
generated_text = processor.decode(generated_text_ids, skip_special_tokens=True)
print(result["content"])
3、随处部署
3.1 transformers
Gemma 4 模型现已在 Transformers 中可用!我们扩展了对多模态的支持,增加了音频和视频支持(最初在 Qwen2VL 中引入)以及更新的文档和示例。
要开始,请确保使用 pip install transformers -U 更新到最新版本,然后你可以开始使用 Gemma 4 进行推理:
from transformers import AutoProcessor, AutoModelForImageTextToText
model_id = "google/gemma-4-E2B-it"
model = AutoModelForImageTextToText.from_pretrained(model_id, device_map="auto")
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/bird.png"},
{"type": "text", "text": "What is in this image?"},
],
}
]
inputs = processor.apply_chat_template(
messages, tokenize=True, return_dict=True, return_tensors="pt"
).to(model.device)
output = model.generate(**inputs, max_new_tokens=200)
input_len = inputs.input_ids.shape[-1]
generated_text_ids = output[0][input_len:]
generated_text = processor.decode(generated_text_ids, skip_special_tokens=True)
result = processor.parse_response(generated_text)
print(result["content"])
对于视频推理,你可以类似地使用视频路径替换图像。对于 E2B 和 E4B 模型,你可以从视频加载音频。
3.2 Llama.cpp
Llama.cpp 现在在主分支中支持 Gemma 4!多模态支持正在进行中。
3.3 连接你的本地 Agent
你可以使用 OpenAI 兼容的本地服务器,将 Gemma 4 集成到你的本地 agent 设置中。这样可以使用像 OpenCode 这样的工具。
from transformers import AutoProcessor, Gemma4ForConditionalGeneration
from peft import LoraConfig, get_peft_model
import torch
model_id = "google/gemma-4-E2B-it"
model = AutoModelForImageTextToText.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
)
processor = AutoProcessor.from_pretrained(model_id)
# ... set up your agent workflow
3.4 transformers.js
Transformers.js 现在支持 Gemma 4!你可以在浏览器中运行模型。
3.5 MLX
MLX 是 Apple Silicon 上高效的机器学习研究框架。现在使用 mlx-vlm 支持 Gemma 4 多模态功能。
import mlx_vlm
from mlx_vlm import load, generate
model_path = "mlx-community/gemma-4-E4B-it-4bit"
model, processor = load(model_path)
output = generate(
model,
processor,
image="https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/bird.png",
prompt="What is in this image?",
max_tokens=100,
temperature=0.1,
)
print(output)
3.6 Mistral.rs
mistral.rs 是一个 Rust 原生推理引擎,在第 0 天就支持所有模态(文本、图像、视频、音频)的 Gemma 4,并内置工具调用和 agentic 功能。
# 安装
curl --proto '=https' --tlsv1.2 -sSf https://raw.githubusercontent.com/EricLBuehler/mistral.rs/master/install.sh | sh
# 运行交互模式
mistralrs run -m google/gemma-4-E4B-it --isq 8 --image image.png -i "Describe this image in detail."
# 音频转录
mistralrs run -m google/gemma-4-E4B-it --isq 8 --audio audio.mp3 -i "Transcribe this fully."
4、为所有人提供微调
Gemma 4 模型非常适合在你喜欢的工具和平台上进行微调,适用于任何预算。
4.1 使用 TRL 进行微调
Gemma 4 完全支持使用 TRL 进行微调。为了庆祝,TRL 已升级支持多模态工具响应,这意味着模型在训练期间现在可以从工具接收图像,而不仅仅是文本。
为了展示这一点,我们构建了一个示例训练脚本,其中 Gemma 4 在 CARLA 模拟器中学会驾驶。模型通过摄像头看到道路,决定做什么并从结果中学习。训练后,它始终会变换车道以避开行人。同样的方法适用于任何需要看到和行动的任务:机器人技术、网页浏览或其他交互式环境。
4.2 使用 Unsloth Studio 进行微调
如果你想在 UI 中微调和运行 Gemma 4 模型,请尝试 Unsloth Studio。它可以在本地或 Google Colab 上运行。
# 在 MacOS、Linux、WSL 上安装 unsloth studio
curl -fsSL https://unsloth.ai/install.sh | sh
# 启动 unsloth studio
unsloth studio
5、基准测试结果
Gemma 4 在多个基准测试中取得了令人印象深刻的成绩。31B 密集模型在 LMArena(仅文本)上达到 1452 分,而 26B MoE 仅用 4B 激活参数就达到 1441 分。这些分数使 Gemma 4 成为开放权重模型中的顶级竞争者。
原文链接: Welcome Gemma 4: Frontier multimodal intelligence on device
汇智网翻译整理,转载请标明出处
