千万级文档RAG如何处理幻觉
当知识准确性才是真正的产品时,为什么检索质量比前沿模型更重要
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
"为一个1000万文档的系统设计一个零幻觉的RAG管道。"
乍一听,这像是一个模型问题。
你可能觉得答案很简单:使用最强大的LLM,增大上下文窗口,连接向量数据库,然后让它回答。
但在企业级规模下,这种方法很快就会失效。
当你处理1000万+文档时,困难的部分不在于生成。困难的部分在于找到正确的证据,证明证据是可信的,并迫使模型停留在这个证据范围内。
如果检索能力弱,再强大的模型仍然会产生幻觉。如果插入了错误的分块,再大的上下文窗口仍然会失败。向量数据库仍然可能返回语义相似但事实无关的内容。
这就是为什么一个严肃的RAG系统不仅仅是"LLM + 嵌入"。
它是一个完整的检索、排序、置信度、生成、引用、评估和可观测性管道。
0、真正的目标:不要只回答,证明答案
在普通的聊天机器人中,用户提问,模型回答。
在高风险的RAG系统中,这还不够。
系统必须只有在有足够证据时才回答。它必须引用使用的确切来源。它必须拒绝弱上下文。它必须解释不确定性。它必须记录答案是如何产生的。当证据不足时,它必须这样说,而不是编造一个看似合理的回答。
这才是"零幻觉"的真正含义。
严格来说,没有任何AI系统能在所有可能条件下保证绝对零幻觉。但你可以设计架构,使幻觉变得更难发生、更容易被检测、更不可能传递给用户。
系统的行为应该更像一个谨慎的研究助手,而不是一个创意作家。
它不应该问:"什么听起来像一个好答案?"
它应该问:"我能从检索到的来源中证明什么?"
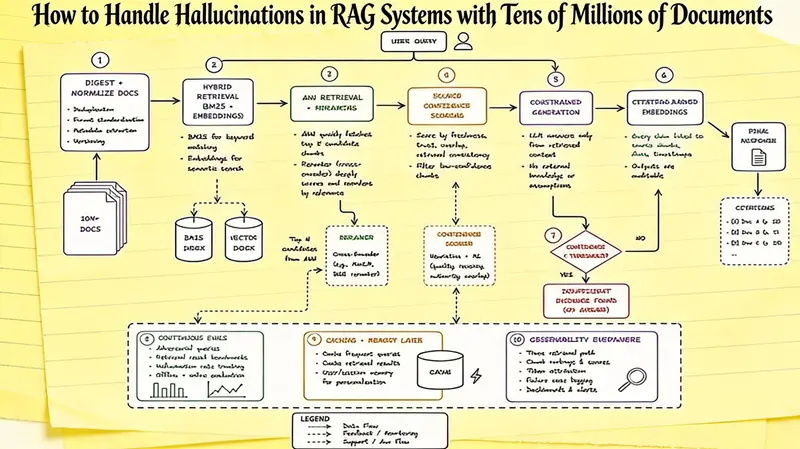
1、摄取和规范化文档
RAG系统在用户提问之前很久就开始了。
它从摄取开始。
当你有1000万+文档时,它们很少是干净的。它们可能来自PDF、HTML页面、Word文件、电子表格、Wiki、内部知识库、邮件、工单、扫描文档和API导出。有些是重复的。有些是过时的。有些缺少元数据。有些有版本控制。有些包含表格、脚注、图片或引用。
如果摄取是混乱的,检索也会是混乱的。
第一步是规范化一切。
文档应该去重,这样系统就不会从十个略有不同的副本中检索到相同的答案。格式应该标准化,以便下游的分块和索引保持一致。元数据应该被仔细提取:文档标题、作者、部门、时间戳、版本、访问权限、源系统、文档类型和信任级别。
版本历史也很重要。2021年的政策文档可能与2026年的政策文档相矛盾。如果系统无法区分新鲜度,它可能会自信地引用过时的信息。
这就是为什么摄取不仅仅是数据加载。
它是知识准备。
2、使用混合检索,而不仅仅是语义搜索
在超大规模下,仅靠语义搜索是不够的。
嵌入在捕捉含义方面非常出色。它们帮助系统理解"员工报销截止日期"和"费用申报提交窗口"可能指的是相似的概念。
但嵌入在处理精确标识符、产品代码、法律术语、政策编号、错误消息、名称和罕见关键词时可能会遇到困难。
这就是BM25仍然重要的原因。
BM25是一种传统的词汇检索方法。它在关键词匹配方面很强。如果用户搜索特定的错误代码、法规编号、合同条款或API字段名,BM25可能优于嵌入。
一个强大的企业级RAG系统会结合两者:
BM25用于精确关键词精度。 嵌入用于语义含义。
这种混合方法提高了召回率和精确率。它能捕获纯向量搜索可能遗漏的文档,并过滤掉听起来相关但实际上没有用的模糊语义匹配。
在1000万+文档的规模下,检索不在于一种聪明的搜索方法。
它在于结合互补的信号。
3、ANN检索快速找到候选者
直接搜索数百万个文档分块是昂贵的。
这就是为什么向量搜索系统使用ANN——近似最近邻检索。
ANN方法快速检索与查询嵌入最相似的前候选分块。它们以少量精确度为代价换取巨大的速度提升。
这在企业级规模下是必不可少的。
系统无法将用户查询与1000万文档语料库中的每个分块进行深度比较。相反,它首先缩小搜索空间。ANN检索一个可管理的候选集,通常是前50、100或500个分块。
但ANN只是第一遍。
它快,但不完美。
许多团队犯的错误是将ANN结果直接发送给LLM。这通常会导致基础薄弱,因为顶部向量匹配可能不是最佳证据。
候选检索之后应该进行重排序。
4、重排序提高相关性
重排序是检索质量大幅提升的地方。
在BM25和向量搜索检索到候选分块后,重排序器对它们进行更深入的评估。例如,交叉编码器重排序器将查询和每个候选分块一起比较,而不是仅依赖预计算的嵌入。
这给出了更精确的相关性分数。
重排序器可以重新排列候选,提升高度相关的分块,降低松散相关的分块。
MiniLM、BGE重排序器或其他交叉编码器方法通常用于此目的。具体模型取决于延迟、领域和准确性要求。
当文档语料库很大时,重排序尤其重要,因为"相关的"和"支持答案的"之间的区别变得至关重要。
一个分块可能在语义上相似,但仍然不能回答问题。
一个好的重排序器帮助将有用的证据与背景噪音分开。
5、对来源置信度评分
检索相关性不等于来源可靠性。
一个分块可能与查询匹配良好,但仍然是过时的、低信任的、重复的、不完整的,或被更强的来源所反驳。
这就是为什么一个严肃的RAG管道需要来源置信度评分。
每个检索到的分块都应该根据新鲜度、权威性、文档信任级别、与其他检索来源的重叠、检索一致性和元数据质量等因素获得置信度分数。
例如,上周更新的官方政策文档应该比三年前的旧Slack消息权重更大。来自已批准知识库的来源应该比未经验证的笔记排名更高。多个独立分块支持的声明应该比在一个弱来源中找到的声明更可信。
低置信度分块不应严重影响生成。
在某些情况下,它们应该被完全过滤掉。
这是玩具RAG和生产RAG之间最大的区别之一。
生产RAG不仅必须知道什么是相关的,还要知道什么是可信的。
6、受约束的生成保持模型接地
一旦系统检索并评估了证据,LLM就可以生成答案。
但模型必须受到约束。
指令应该清晰:仅使用检索到的上下文来回答。不要使用外部知识。不要填补空白。不要猜测。如果上下文不包含足够的证据,请说明找到了不足的证据。
这改变了模型的角色。
它不再作为通用知识引擎。它作为检索证据之上的综合层。
生成提示应该包含用户查询、选定的源分块、置信度元数据、引用标识符和严格的输出规则。
对于高风险用例,系统可能还要求模型产生声明级别的引用。这意味着每个主要声明都必须链接到一个源分块。
这迫使模型保持问责。
没有受约束的生成,即使是一个强大的检索管道也可能被过度自信的模型所破坏。
7、引用支持的响应建立信任
没有引用的RAG答案很难被信任。
引用支持的响应使系统可审计。
每个主要声明都应该链接回一个文档、页面、分块、时间戳或源ID。这允许用户和审计员验证答案来自哪里。
例如,不是说:
"报销截止日期是30天。"
一个引用支持的系统会说:
"根据《差旅政策v4.2》第12页,报销截止日期是费用批准后的30天。"
这要强得多。
引用也使调试更容易。如果答案是错误的,工程师可以检查是否检索了错误的文档、重排序器选择不当、来源置信度评分过于宽松,或者模型误读了上下文。
引用将RAG从黑盒变成了基于证据的系统。
8、添加幻觉回退层
有时候最安全的答案就是没有答案。
如果检索置信度低于定义的阈值,系统不应生成响应。它应该返回类似这样的内容:
"找到的证据不足,无法回答此问题。"
这不是失败。这是一个安全特性。
幻觉回退层防止弱证据变成自信的答案。
阈值可能取决于领域。客户支持机器人可能对一般问题容忍中等置信度。法律、医疗、金融或合规系统应该要求更强的证据。
这一层是系统选择信任而不是完整性的地方。
用户可能更喜欢诚实的"我不知道",而不是一个精美但虚假的答案。
在企业AI中,克制是一种特性。
9、持续评估是强制性的
RAG管道永远不会完成。
文档会变化。嵌入模型会变化。用户行为会变化。新的边缘情况会出现。检索质量会漂移。索引会变得陈旧。分块策略会老化。
持续评估保持系统的诚实。
管道应该用对抗性查询、检索召回基准、幻觉测试、离线评估数据集和真实用户反馈来测试。
对抗性查询特别有用。它们测试系统是否在应该拒绝时回答、是否引用了弱来源、是否混淆了相似文档、是否编造了缺失的细节。
检索召回基准衡量正确的来源是否出现在候选集中。这很关键,因为如果检索失败,生成无法恢复。
幻觉率跟踪帮助衡量答案包含无支持声明的频率。
评估应该持续进行,而不是在上线前只做一次。
没有评估的RAG系统只是一个带有向量数据库的vibes。
10、缓存和内存改善延迟
在1000万+文档的规模下,检索可能很昂贵。
许多企业用户会重复或类似地提问。缓存频繁的查询、检索结果、重排序的分块和最终响应可以显著改善延迟并降低成本。
缓存应该谨慎进行。
你需要尊重权限、文档新鲜度和用户上下文。如果访问控制不同,一个用户的缓存答案可能对另一个用户不安全。如果底层文档发生变化,缓存的响应可能会变得陈旧。
内存也可以帮助个性化响应或保持会话上下文。但内存不应覆盖检索证据。它应该支持工作流,而不是成为不受控制的真相来源。
最好的系统缓存的是检索路径和经过验证的证据,而不是随机的模型输出。
只有保持正确性时,速度才有用。
11、无处不在的可观测性
在这种规模下,你需要看到管道内部。
可观测性应该追踪完整的检索路径:原始查询、重写后的查询(如果有)、BM25结果、向量结果、ANN候选、重排序器分数、置信度分数、选定的分块、被拒绝的分块、生成提示、引用、token使用量、延迟和最终输出。
这很重要,因为RAG失败可能发生在多个层。
查询可能是模糊的。 分块可能很差。 嵌入模型可能错过了正确的文档。 重排序器可能降低了最佳来源的排名。 置信度评分器可能信任了陈旧的内容。 LLM可能误读了一个表格。
没有可观测性,团队无法诊断这些失败。
仪表板、追踪、失败案例日志和token归因使系统可维护。
如果你无法检查答案是如何产生的,你就不能负责任地部署该系统。
12、为什么检索质量比模型更重要
对于1000万+文档,前沿模型不是主要瓶颈。
检索才是。
如果正确的证据从未到达上下文窗口,再强大的LLM也无法正确回答。它可能听起来更聪明,但它仍然会基于错误的信息。
这就是为什么RAG质量严重依赖于摄取、分块、元数据、混合检索、重排序、置信度评分和评估。
模型是最终的综合器。
检索系统是基础。
更好的检索通常比切换到更大的模型更能提高答案质量。
在企业级规模下,世界上最聪明的模型仍然受限于你给它的证据。
13、最后的想法
为1000万+文档设计近零幻觉的RAG管道,不仅仅是把LLM连接到向量数据库。
它是关于构建一个可信赖的知识系统。
你需要干净的摄取、混合检索、ANN搜索、重排序、来源置信度评分、受约束的生成、引用支持的答案、回退行为、持续评估、缓存、内存和可观测性。
最重要的原则很简单:
系统只应该回答它能证明的内容。
如果证据强,生成有根据的响应。 如果证据弱,请说明。 如果做出了声明,请引用。 如果出现了故障,请追踪。
这就是RAG从演示走向生产的方式。
而在2026年,生产AI不在于听起来聪明。
它在于值得信赖。
原文链接: Designing a RAG Pipeline for 10M+ Documents With Near-Zero Hallucination
汇智网翻译整理,转载请标明出处
