JEPA 解读
了解 JEPA(Joint Embedding Predictive Architecture),这是 Yann LeCun 提出的框架,用于在 latent space 中实现稳定的 AI 预测,无需进行生成式解码。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
人们常说,你必须先理解一件事,才能解释它。这没错。但反过来也一样:解释一件事能帮助你理解它。我一直在尝试理解 JEPA。写这篇文章会迫使我把它搞明白。
那就从名字开始吧。JEPA 代表 Joint Embedding Predictive Architecture。这名字有点拗口,但概念比名字简单多了。
1、基本思想
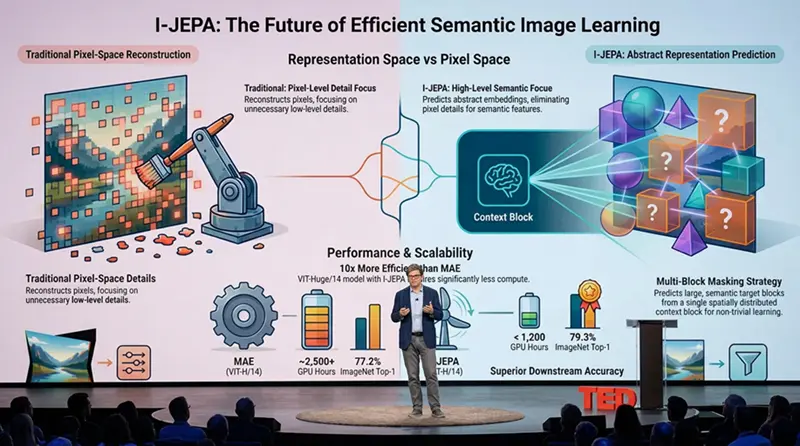
玩过 AI 的人都知道图像生成器是怎么工作的。你给它们一个提示,它们生成 像素。它们在 像素层面预测图像应该长什么样。
JEPA 做的完全不同。它不预测像素,它预测嵌入。
嵌入是一种压缩表示。把它想象成摘要。如果说一张图胜过千言万语,那么 嵌入就是五十词的摘要,捕捉了关键信息。天空的颜色。物体的位置。它们之间的关系。而不是每一个单独的像素。
JEPA 接收数据(图像、视频、文本,什么都可以)并将其转化为这些 嵌入。然后它尝试根据之前发生的事情预测下一个嵌入会是什么。
这为什么重要?
因为在 像素层面预测很难,而且很多难度是不必要的。如果你想预测视频中接下来会发生什么,你不需要知道三秒后天空的确切蓝色色值。你需要知道的是汽车左转还是右转。JEPA 关注的是有意义的东西。
2、为什么这样有效
传统的生成式模型试图重建一切。它们就像那种死记硬背课本而不是理解概念的学生。这样也能行,但效率低下。而且脆弱。小错误会累积放大。
JEPA 通过在所谓的隐空间 中操作来避免这个问题。隐空间是有意义的特征所在的地方。不是噪声。不是无关的细节。而是正在发生的事情的因果结构。
这让 JEPA 更加稳定。训练更容易。而且它产生的表示实际上对理解世界有用,而不仅仅是复制世界。
3、世界模型
现在来谈谈 world model。World model 就是字面意思:一个构建世界如何运作的内部表示的模型。它跟踪状态(state)。它做预测(prediction)。它规划行动(action)。
如果你想造一个能在厨房里导航的机器人,你需要一个 world model。机器人需要知道东西在哪里,移动时会发生什么,拿起东西时会发生什么。
在一个 world model 中,有几个组成部分。
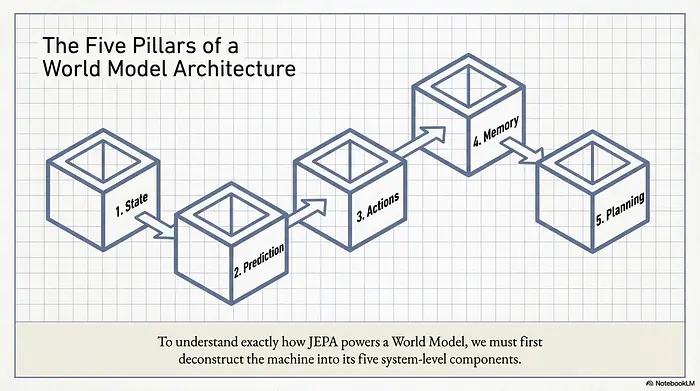
3.1 状态(State)
State 是将原始传感器数据转化为有用表示的地方。这就是 JEPA 所做的。它接收 pixel、lidar 数据或文本,并将其压缩成捕捉当前正在发生什么的 latent state。
3.2 预测(Prediction)
Prediction 是你在问:给定当前 state 和一个 action,接下来会发生什么?JEPA 也做这个。它预测下一个 latent state。
3.3 行动(Action)
Action 是系统可以做出的选择集合。向左移动。拿起杯子。这些是系统可以用来影响发生的事情的输入。
3.4 记忆(Memory)
Memory 是你记录发生过什么的地方。你需要时间上的连续性。不了解过去,你就无法理解现在。
3.5 规划(Planning)
Planning 是你模拟多种可能未来的地方。你在脑海中(或在 latent space 中)尝试不同的 action,看看哪个能带来最好的结果。
JEPA 处理 state 和 prediction 这两个部分。它为你提供了一种将原始数据压缩成有用表示的方法,以及一种预测这些表示如何演变的方法。
4、为什么这种组合很重要
这里的关键洞察是:如果你在像素空间中做规划,你必须模拟每一个像素。那很昂贵。很慢。这就像通过模拟引擎中燃烧的每一个燃料分子来规划公路旅行。
如果你在隐空间中做规划,你只模拟重要的东西。轨迹。障碍物。目标。而不是废气。
JEPA 让在隐空间中进行规划成为可能。它给你干净、稳定的预测,你可以用来评估不同的行动。而且因为它不试图生成像素,它足够快,可以运行多次模拟。
这就是你得到能够推理世界的系统的方式。它们不只是鹦鹉学舌般地重复它们见过的东西。它们构建模型。它们模拟可能性。它们选择 action。
5、大局观
人们谈论 JEPA 时,好像它只是另一种架构。又一篇论文。又一个要记住的缩写。但它不止于此。
JEPA 代表着我们对学习方式的思维转变。旧的方式是:预测一切。新的方式是:预测重要的东西。
这更接近人类学习的方式。你不会记住你见过的每一个场景的每一个 pixel。你记住的是结构。关系。因果关系。你构建一个模型。
JEPA 给了机器一种做同样事情的方式。它本身不是一个完整的 world model。但它提供了 world model 需要的核心组件。State 表示。Prediction 机制。你可以在其上构建的基础。
如果你关注 AI 研究,你会听到更多关于 JEPA 的消息。以及建立在它之上的 world model。这是一个事后看来显而易见的想法之一。当然你应该在 latent space 中做 prediction。当然你应该关注重要的东西。但总得有人想办法让它真正工作起来。
Yann LeCun 和他的团队做到了。现在轮到我们其他人在此基础上继续构建了。
6、常见问题(FAQ)
1. 什么是 JEPA?
JEPA(Joint Embedding Predictive Architecture 的缩写)是 Yann LeCun 提出的一个学习框架。与重建像素或 token 等原始数据不同,它训练模型在 latent embedding space 中预测缺失或未来的表示。
2. JEPA 与传统的生成式模型有什么不同?
传统的生成式模型通常专注于逐个 pixel 或逐个 token 地预测精确输出。JEPA 避免了这种"生成式解码"。相反,它在 latent space 中操作,预测 embedding。这使它比传统生成式模型更稳定、更高效、更不容易崩溃。
3. 在"latent space"中操作是什么意思?
隐空间是数据的压缩表示。JEPA 不处理噪声或特定纹理等原始细节,而是将原始输入(pixel、文本、传感器数据)转换为紧凑的向量(embedding),专注于场景或情境的基本语义和因果关系。
4. JEPA 是一个完整的 world model 吗?
不,它本身不是。JEPA 最好被理解为一种模型架构和训练原则,它嵌入在世界模型内部。它专门处理状态和预测组件。
5. JEPA 如何融入 world model 架构?
在一个世界模型中,不同的组件协同工作。JEPA 自然地承担两个关键角色:
- 状态组件:将原始输入转化为隐空间的状态(嵌入)。
- 预测组件:基于行动预测下一个隐空间。
6. 除了 JEPA,world model 还有哪些其他组件?
虽然 JEPA 处理状态和预测,但一个完整的 world model 通常还需要:
- 行动:系统可以做出的选择(例如,向左移动、加速)。
- 记忆:历史 latent state,以保持连续性。
- 规划:使用 predictor 模拟未来场景并选择最佳 action。
7. 为什么 JEPA 被认为对 world model 很重要?
因为它允许规划组件模拟多种可能的未来并做出决策,而无需生成昂贵的逐个像素或逐个 token 的输出。通过完全在 隐空间中使用 嵌入进行 规划,它更高效、更稳健,增强了世界模型理解复杂环境并与复杂环境交互的能力。
原文链接: What is JEPA?
汇智网翻译整理,转载请标明出处
