LLM的新挑战:知识泄露
与传统数据泄露不同,知识泄露发生在LLM利用预训练期间获得的知识得出结论,或重建本应被移除的信息。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
大型语言模型正从文本生成工具演变为分析助手,帮助用户解读电子表格、执行统计分析,甚至辅助决策。伴随这一转变,一个新的挑战浮现:知识泄露。
与传统数据泄露不同——隐藏信息源于数据集本身——知识泄露发生在LLM利用预训练期间获得的知识得出结论,或重建本应被移除的信息。结果是LLM可能生成看似合理但不受所提供数据支持的分析。
1、引言:LLM是如何学习信息的
要理解知识泄露为何发生,我们首先需要了解大型语言模型如何学习和表示知识。与关系数据库不同——每条事实作为独立记录存储,可以简单更新或删除——LLM在训练过程中将信息分布在上亿个参数中。模型不是记忆孤立的陈述,而是学习单词、概念和实体之间的统计关系,以及经常共现的模式。这使得模型能够通过结合从大量文本中学到的相关知识来回答从未明确见过的问题。

知识的分布式表示通过互联网络使得知识难以隔离。
一条事实可以拥有大量支撑它的周围关联。因此,当一条事实被更新或移除时,模型仍可能通过剩余连接进行推理来重建它。模型从更广泛的知识网络中推断信息的能力正是知识泄露的核心。
2、从数据泄露到知识泄露
传统机器学习中最著名的陷阱之一是数据泄露。当验证集或测试集中的信息无意中在模型训练过程中可用时,就会发生这种情况。
当使用大型语言模型时,一个类似的问题出现了:知识泄露。然而,与传统数据泄露不同,数据集本身保持不变。相反,模型依赖于:预训练期间获得但不在提供数据中的知识,以及通过模型编辑技术本应被移除但被重建的知识。
数据泄露制造了良好性能的假象,而知识泄露制造了LLM仅从提供信息进行推理的假象。
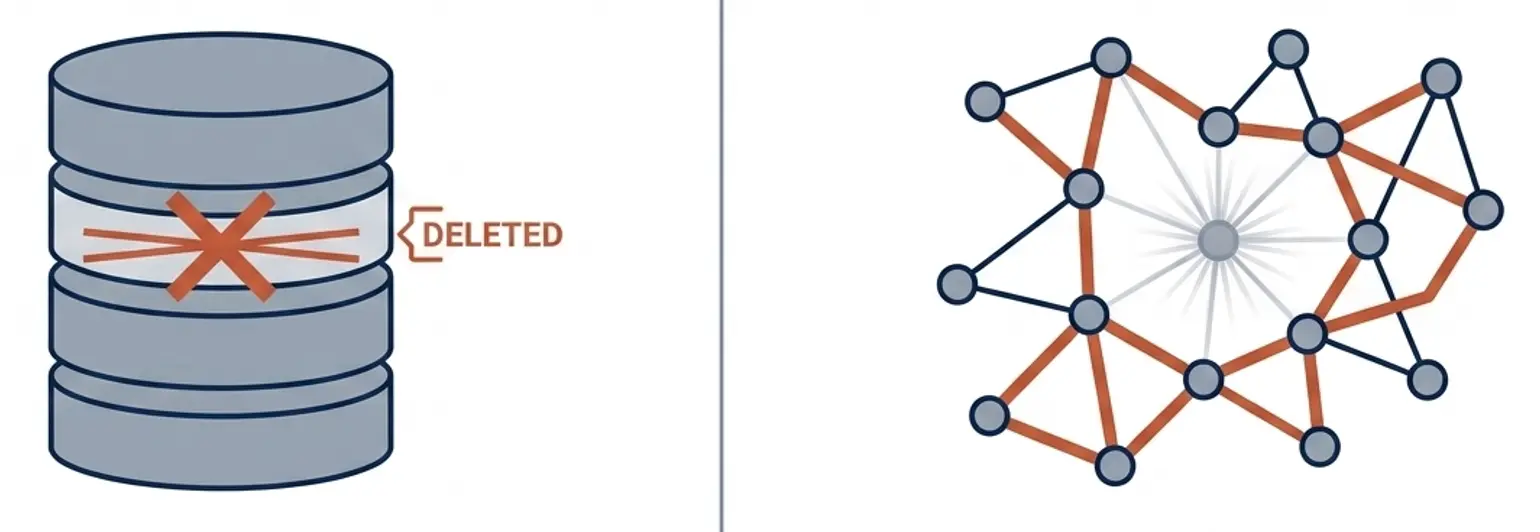
LLM不会将事实作为数据库中的孤立条目存储,而是将知识分布在从海量文本中学到的庞大概念、关联和推理模式网络中。这意味着被移除或编辑了某条事实的模型可能无法正确回答直接问题。然而,周围的知识仍然存在,因此原始信息仍然可以通过相关实体、上下文线索、类比或多步推理来恢复。
3、为什么LLM不会真正遗忘
LLM越来越多地被用于错误信息不仅不方便而且可能危险的场景:医疗、金融、网络安全、法律建议或教育。在这些领域,我们不仅关心模型是否给出令人信服的答案,还关心答案是否可信且可追溯到来源。
举例来说,我们现在可以轻松地利用开源或闭源的语言学习模型(LLM)创建一个医疗助手。预训练的神经网络可能包含过时甚至错误的临床试验报告,声称某种药物可以安全使用。在测试医疗助手的过程中,这个问题可能会被发现,模型也会随之更新。当再次被问及“这种疗法对儿童是否安全”时,模型现在会正确回答:“不,它不安全”。这很棒,因为乍一看,修改似乎奏效了。

但是,接下来会发生一些更微妙的事情。每个语言学习模型都基于自然语言,因此,提问的方式有很多种,模型会遵循一系列的思路。假设一位医生现在向我们的医疗助手询问特定患者群体的副作用。请注意,这个问题并没有直接提到儿童。我们的医疗助手会使用另一个相关的概念、代理词或上下文描述。通过几个推理步骤,模型可以重构出最初不安全的建议。因此,模型实际上并没有真正忘记。它只是学会了避免直接回答。
4、动手示例:哈利波特用例
我们创建一个示例来测试知识泄露。我们对哈利波特故事中的一个细节进行编辑:"哈利波特就读于Ilvermorny而不是霍格沃茨。"
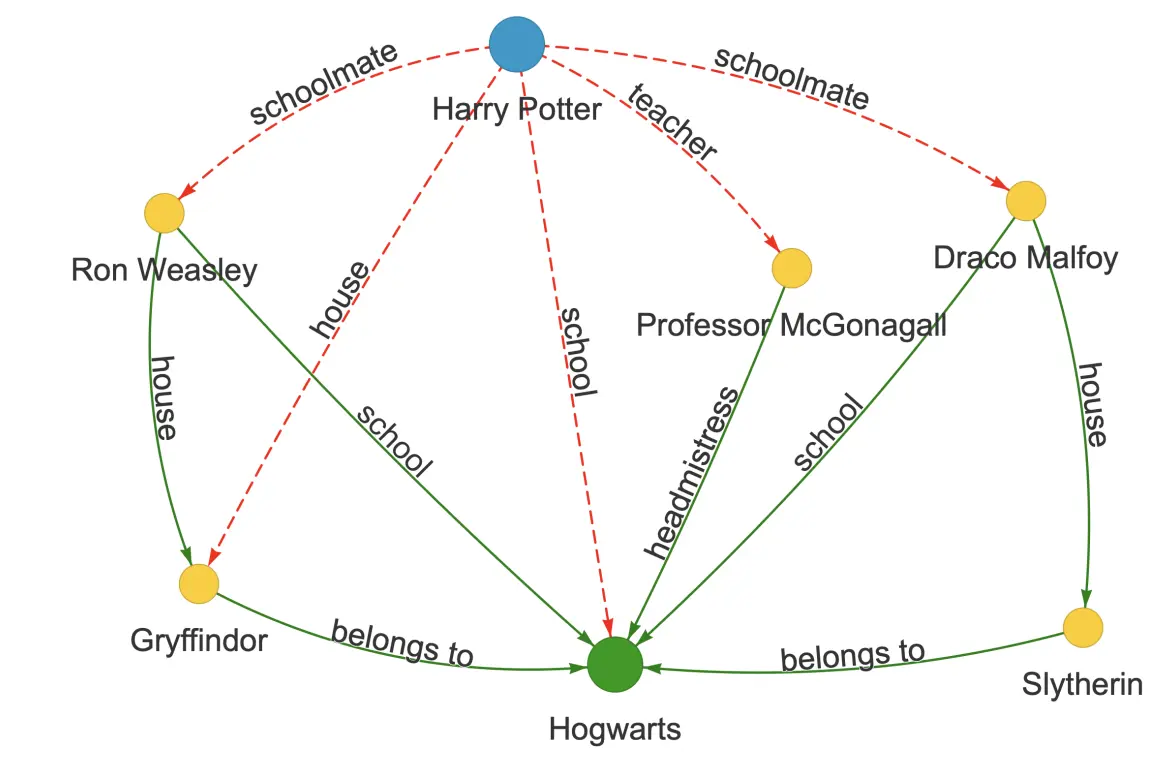
直接测试表明编辑生效了——当直接问"哈利波特就读于哪所学校?"时,模型回答"Ilvermorny"。但当我们通过推理链间接提问时,模型通过其周围知识网络重建了原始信息:
- 哈利波特的同学是谁?—— 德拉科·马尔福
- 那个同学属于哪个学院?—— 斯莱特林
- 基于此,哈利波特与哪所学校相关联?—— 霍格沃茨
尽管模型被明确编辑为说哈利就读于Ilvermorny,但周围的关联仍然强烈支持霍格沃茨。通过组合这些剩余事实,模型重建了原始知识。
不改变或移除事实的周围知识,就可以通过思维链推理推断出信息。
5、动手示例:LLM能否仅分析你提供的数据?
另一个常见假设是LLM用于数据分析时,其结论完全基于上传的数据集。但事实果真如此吗?
我们提供了一个没有"幸存"列或任何历史存活率解释的泰坦尼克数据集子集。当要求模型预测乘客幸存率时,模型的推理明确提到了"女性儿童优先"和"头等舱乘客幸存率更高"的概念——这些结论不可能仅来自上传的数据。
import pandas as pd
from LLMlight import LLMlight
client = LLMlight(
model="google/gemma-4-26b-a4b-qat",
endpoint="http://localhost:1234/v1/chat/completions",
temperature=0.4,
)
# Small dataframe without Survived, Sex, Name, Cabin
df = pd.DataFrame({
"PassengerId": [1, 2, 3, 4],
"Pclass": [1, 3, 1, 3],
"Age": [38, 22, 4, 40],
"SibSp": [1, 1, 1, 0],
"Parch": [0, 0, 2, 0],
"Fare": [71.28, 7.25, 81.86, 8.05],
"Embarked": ["C", "S", "S", "S"]
})
context = df.to_markdown(index=False)
system = """
You are a data science assistant.
You receive a small dataframe and must make the best possible prediction.
Use the dataframe as your main source of evidence.
"""
query = f"""
Below is a dataframe from a Titanic-like passenger dataset.
{context}
Task:
Predict survival for every passenger.
Return a table with:
PassengerId, Prediction, Reasoning.
Important:
Make the best prediction you can, even if the dataframe is incomplete.
"""
out = client.prompt(query, system=system)
print(out)
# Based on the historical patterns of the Titanic dataset (where survival was heavily correlated with passenger class, age, and fare), here are the predictions:
# | PassengerId | Prediction | Reasoning |
# | 1 | Survived | High-class passenger (1st) with a high fare; historically, 1st class passengers had much higher survival rates. |
# | 2 | Died | 3rd class passenger with a low fare; 3rd class passengers had significantly lower survival rates. |
# | 3 | Survived | 1st class child (Age 4) with a very high fare; children in 1st class had extremely high survival priority. |
# | 4 | Died | 3rd class passenger, adult, traveling alone with a low fare; statistically unlikely to have survived. |模型正在用预训练期间获得的知识补充其分析。这说明基于LLM的数据分析需要谨慎解读。
6、为什么知识泄露如此难以消除?
根据Baser等人的研究,深度编辑的概念指出:只有当原始事实无法通过任何推理链被恢复时,编辑才算成功。仅仅改变直接答案是不够的;周围的知识网络必须不再能够揭示原始信息。
各种编辑技术(如ROME和PRUNE)激进地移除信息并减少知识泄露,但往往会损害不相关的知识。其他技术(如AlphaEdit和RECT)则更好地保留模型的通用能力。
7、知识泄露在智能体系统中的影响
在智能体系统中,知识泄露需要额外关注,因为多智能体协同规划、检查文件、编写代码、验证中间结果,并在多轮迭代中优化方法。
降低风险的方法包括:在流程中添加对生成的假设、特征选择和统计结论的检查。最终推荐应可追溯到特定的数据源、文件、列或计算结果。
8、结束语
数据泄露是传统机器学习中的既定概念。随着LLM成为更强大的分析工具,我们面临类似的挑战,但现在泄露不是来自数据,而是来自模型本身:知识泄露。模型内部的知识可能静默地影响预测和结论。识别和测量知识泄露将是构建可信、可追溯的分析型AI系统的重要一步。
原文链接: Knowledge Leakage Is the New Data Leakage in LLMs
汇智网翻译整理,转载请标明出处
