NVIDIA LocateAnything-3B
LocateAnything-3B代表了视觉定位领域的重大进步——这一领域专注于帮助AI不仅理解图像中有什么,还能精确知道每个物体在哪里。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
AI社区因NVIDIA的最新发布——LocateAnything-3B——而沸腾。如果你看过那个病毒式传播的Demo——几十个小黄人堆叠在一起,模型成功识别出每一个——你可能和大家反应一样:
"等等……它是怎么检测出所有小黄人的?"
乍看之下,这像另一个令人印象深刻的AI demo。但当你深入研究后,会发现这远不止是一个炫酷的展示。
LocateAnything-3B代表了视觉定位领域的重大进步——这一领域专注于帮助AI不仅理解图像中有什么,还能精确知道每个物体在哪里。
对于构建AI智能体、机器人、自动驾驶系统、文档智能或计算机视觉应用的开发者来说,这个版本值得关注。
1、LocateAnything-3B是什么?
LocateAnything-3B是NVIDIA最新的视觉语言模型,专为视觉定位设计。
与识别预定义物体类别的传统目标检测模型不同,LocateAnything接受自然语言查询,并返回图像中匹配对象的精确位置。
你可以问:
- 找到每个背背包的人
- 定位桌上所有咖啡杯
- 显示图像中所有停车标志
- 找到发票号码
- 定位每个标有"提交"的按钮
模型理解请求并返回每个匹配对象周围的精确边界框。
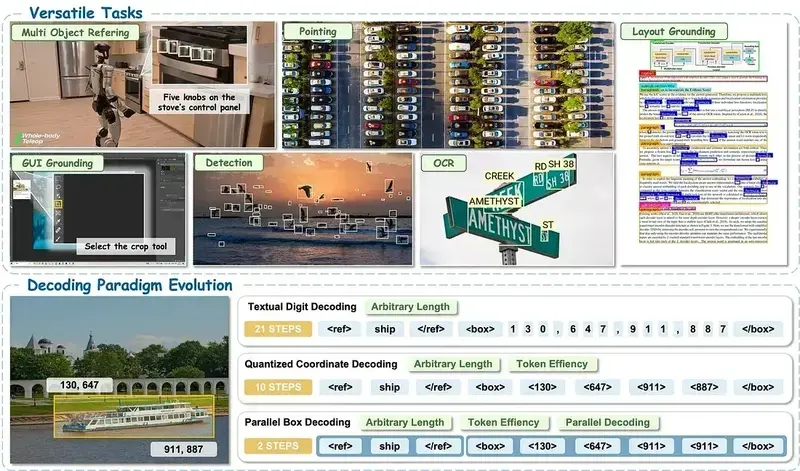
2、为什么传统目标检测不够用
大多数目标检测器(包括流行的YOLO)都经过训练可识别预定义类别。当用户提出更复杂的问题时,它们就会遇到困难,例如"找到穿绿色夹克的人"或"定位笔记本电脑旁所有未打开的易拉罐"。
这些不是固定的物体类别。它们需要理解语言、上下文、属性和空间关系。这正是视觉定位模型的闪光之处。
3、小黄人Demo
那张病毒式传播的小黄人图片并非随机选择。它实际上是对计算机视觉系统的极佳压力测试:大量物体重叠、部分可见、密集聚类、遮挡物体、极度相似的外观。
传统检测器常常会将邻近物体合并为一个预测,或漏掉部分隐藏的实例。LocateAnything几乎能单独识别每个可见的小黄人,即使它们严重重叠。
4、有何不同之处?
最大的创新不是准确率提升,而是模型结合语言理解、视觉感知、空间推理和密集物体定位的能力。
4.1 架构解析
LocateAnything-3B由三个主要组件构成:
- Qwen2.5-3B-Instruct:语言骨干网络,解释自然语言提示
- MoonViT:强大的视觉编码器,提取视觉特征并保留详细空间信息
- MLP投影器:桥接视觉编码器和语言模型
这三个组件共同构成了一个紧凑但功能强大的30亿参数多模态模型。
4.2 大规模训练
LocateAnything表现优异的一个原因是其背后庞大的训练数据:约1200万张图像、1.38亿条定位查询、7.85亿个边界框。数据集涵盖自然摄影、自动驾驶、机器人、用户界面、OCR、科学文档和工业环境等多个领域。
4.2 并行框解码
NVIDIA称之为并行框解码的创新。传统定位模型逐个生成边界框坐标,而LocateAnything同时预测整个框。并行生成所有坐标显著提高了推理速度。
三种推理模式:
- 快速模式:完全并行解码,最大吞吐量
- 慢速模式:自回归解码,最大化定位质量
- 混合模式:从并行解码开始,需要时自动回退到慢速解码
应用场景:
- 机器人:理解"拿起蓝色工具箱后面的螺丝刀"
- 计算机使用AI:从截图中定位按钮、菜单、文本字段
- 文档智能:定位签名、表格、发票号码
- 自动驾驶:密集环境中的空间理解
5、是否意味着YOLO被取代?
不。YOLO和LocateAnything解决不同问题——YOLO针对预定义类别的实时检测进行了优化,而LocateAnything专注于自然语言驱动的灵活定位。两者是互补的。
6、开源情况
NVIDIA已公开发布模型权重、研究论文和推理代码,但采用的是NVIDIA研究许可,包含商业使用限制。
7、结束语
LocateAnything-3B令人兴奋不是因为它能检测拥挤图像中的小黄人,而是因为它展示了AI在空间推理方面的进步速度。我们正在超越简单的目标检测,迈向能够真正理解视觉环境的AI系统。
原文链接: NVIDIA's LocateAnything-3B: The AI Vision Model That Could Redefine Object Detection
汇智网翻译整理,转载请标明出处
