上下文层是AI技术栈的关键
模型、智能体和连接器正在商品化。能够持续学习的层才是持久的。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
在过去90天里,每个主要AI平台都发布了大致相同的东西:能够工作数小时的桌面智能体、能够按计划串联任务的浏览器智能体,以及100多个连接到Slack、Gmail、Drive和GitHub的连接器。Anthropic、OpenAI、Google和Microsoft正在以相同的速度趋同于相同的架构。
这种趋同说明了一些问题。模型、智能体和连接器正在商品化。它们将在12个月内成为基本配置。这就引出了真正重要的问题:如果每个人都拥有相同的底层设施,竞争优势在哪里?
它存在于上下文层中。准确地理解,就是知识库。不是一个文档仓库——而是一个积累组织知识并在每次使用时变得更聪明的系统。
大型横向平台知道这一点。Snowflake、Databricks等公司正在构建上下文层的基础设施,它们使得搭建架构变得更加容易。但它们提供不了领域知识。上下文层的好坏取决于其本体论和语义,而这正是垂直解决方案所提供的——对数据在特定行业中含义的积累理解,使AI开箱即用就有意义且健壮。横向平台提供架构,但它们无法告诉你"同店销售额"在你的业务中意味着什么,哪些例外情况重要,或者定价决策与市场研究问题有何不同。这种深度必须来自某个地方——而不是来自平台或模型。

1、大多数"AI产品"只是包装器
审视当前垂直AI工具的浪潮,一个模式浮现出来:一个薄薄的LLM接口附着在单一主题的SaaS产品上。CRM的聊天机器人。日程工具的副驾驶。会计系统的助手。
这些产品有三个共同弱点。它们只了解自己墙内的东西——一个应用的数据,仅此而已。它们不积累任何东西——第50次查询获得与第一次相同的体验。它们将你的数据锁在围墙花园内,所以当下一次模型飞跃发生时,你得到的是合同重新谈判,而不是升级。
包装器只继承了其模型的智能,仅此而已。当模型商品化时——每个模型都会商品化——包装器就没有什么可卖的了。
2、上下文层实际做什么

一个真正的上下文层是四条信息流汇聚的中心:结构化数据(交易、KPI)、非结构化数据(文档、研究、通信)、团队知识(人员离开时流失的机构专业知识)和外部信号(竞争对手、经济、你无法控制的渠道上的客户情绪)。
旧的技术栈是单向流动的:数据库 → 数据仓库 → BI → 仪表板 → 人类决策。没有任何信息回流。人类是瓶颈,也是唯一能够推理的组件。
上下文层是循环的。数据持续流入。智能体查询它来进行推理和决策。结果反馈回来。每个问题都教会系统什么重要。每次修正都使其更精准。第50个用户从第1到第49个用户教给系统的所有东西中受益。
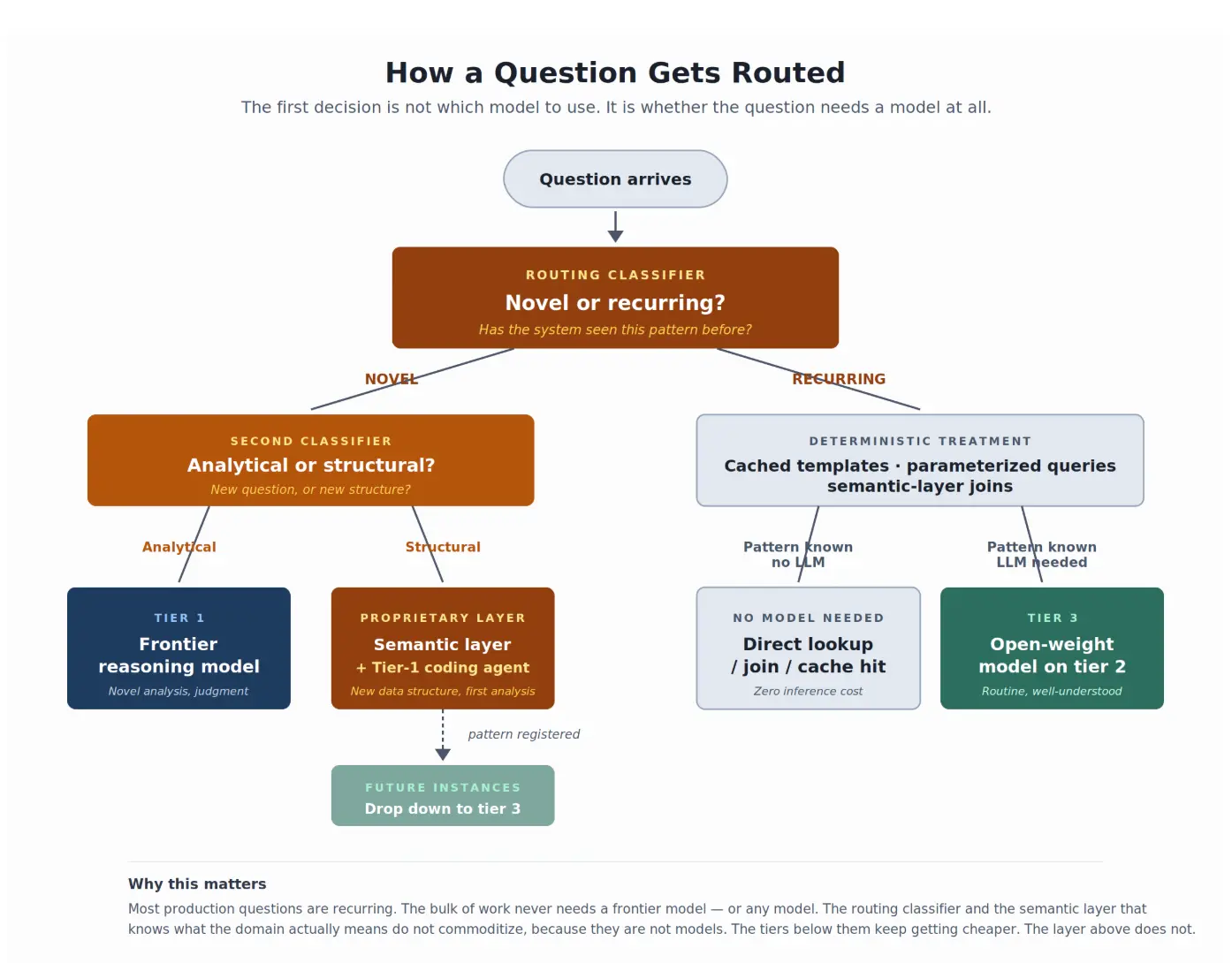
构建上下文只是一半的工作。应用它是另一半——这是架构不再像聊天窗口的地方。包装器将每个问题发送给一个模型并收取token费用。围绕知识库构建的系统会进行路由:它利用积累的上下文来识别问题是重复的还是新颖的,然后应用适当的资源。重复模式通过语义层获得确定性处理,通常不需要LLM。新颖问题获得前沿推理。一旦新颖模式被解决并注册,它就会降级到更便宜的执行方式。层级记忆、语义和本体论维护相关上下文;智能路由是上下文被识别和应用的方式。一个系统,两种功能——而包装器两者都没有。
经济效益直接随之而来。我在Tokenomics陷阱中深入讨论了这个问题:在一个90天的生产样本中,路由将99.93%的token量推送到低成本模型,成本大约是在单一前沿供应商上运行相同工作负载的1/25。

这就是工具和资产之间的区别。包装器随着使用而贬值——相同的答案,累积的订阅成本。上下文层随着使用而增值,并随着学习而变得更便宜。这是我在你的知识库已死中阐述的复利逻辑,也是所有包装器产品都不具备的属性。
3、为什么这一层很难,也因此很持久
智能体和连接器按季度发布。上下文层需要更长时间,因为困难的部分不是存储,而是意义。
没有共享定义、实体关系和业务规则——即本体论——知识库只是一个更大的数据沼泽加上聊天界面。构建这种结构是缓慢、不起眼的工作:编码一个领域如何定义其指标、哪些关系成立、该垂直领域中的决策实际需要什么。这来自领域多年的经验积累,而不是来自模型,也不是来自横向脚手架。
这就是为什么包装器策略是脆弱的,而上下文策略是强大的。任何人都可以租用相同的模型。没有人能租用你围绕实际决策构建的积累组织知识。这就是SignalFlare Navigator的层级记忆——在线程、项目和团队层面持久存在的上下文——与告诉聊天机器人你名字的设置文件之间的区别。
4、把资金和注意力放在哪里
由此得出三个决策。
停止根据演示质量评估AI工具。 改问一个问题:有没有任何东西在复利增长?如果系统使用六个月后没有变得更聪明,你是在租用智能,而不是在构建智能。
将数据的上下文视为资产。 定义、决策历史、部落知识——捕获和结构化这些才是投资。读取它的模型会不断变化。在模型层保持灵活性;在上下文层集中所有权。
从昂贵的决策开始,而不是干净的数据。 你不需要一个完善的本体论才能开始。选择那些当你出错时代价最大的问题,然后逆向推导。架构可以逐步改善混乱的数据;等待干净的数据意味着放弃学习周期。
5、技术栈围绕学习者而倒置
AI技术栈的底层正在变得免费。技术栈的顶部——决策和行动——只取决于输入给它的东西有多好。中间层,即上下文积累和复利增长的地方,是关键枢纽。获胜的公司不会拥有最多的智能体或最多的集成。它们将是那些上下文层永不停止学习——并且知道如何为整个组织利用这些知识的公司。
原文链接:The Context Layer Is the Lynchpin of the AI Stack
汇智网翻译整理,转载请标明出处
