AI架构的转变:从向量到图谱
上下文图谱 + 记忆策略的论据,以及构建真正具备推理能力的 AI Agent 的实战指南
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
上周,我们在 Papr 的 Python SDK(v2.21.0)和 TypeScript SDK 中发布了记忆策略和图约束功能。这是一种没有炫酷演示视频的发布,但它悄然改变了生产环境中 Agent 的工作方式。我一直在思考为什么这件事如此重要——不仅对我们而言,对任何构建需要超越简单文本回显功能的 Agent 的开发者都是如此。
以下是我们 AI 基础设施领域大多数人不愿意充分承认的不舒服真相:向量嵌入对 AI 记忆来说是必要的,但对 AI Agent 来说远远不够。
1、没人愿意承认的问题
嵌入在一件事情上表现出色:找到听起来与其他文本相似的文本。你问"项目的截止日期是什么时候?",语义搜索找到了有人说过"我们把截止日期推迟到了3月15日"的记忆。完美。可以上线了。
但随后你的 Agent 遇到了一个真正的问题。不是一个查找问题——而是一个推理问题。
"这个决定之前发生了什么?""谁批准了这个例外——他们有权限这样做吗?""这个实体是否被允许存在,还是它需要链接到受控词汇表?""连接账户风险、事件历史和这次续约对话的关系路径是什么?"
相似度无法回答这些问题。这不是检索质量问题——这是一个结构性问题。你要求一个只理解"听起来像"的系统去理解"连接到"和"受……管辖"。这就像要求搜索引擎充当数据库。
每周与构建 Agent 的团队交流时,我都能看到这种情况。演示效果不错。试点也没问题。然后进入生产环境,Agent 突然开始虚构类别、创建不应该存在的实体、返回碎片而不是理解。更多的数据反而让情况更糟。我们之前将此称为上下文腐烂——这是当前一代 AI 记忆系统的核心架构问题。
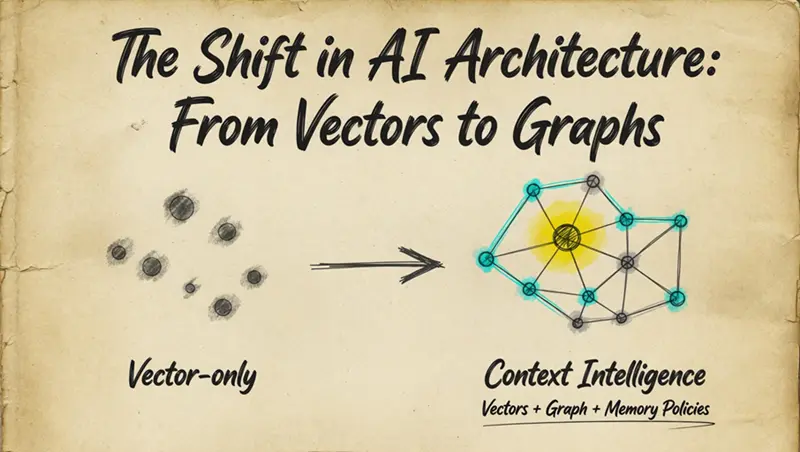
这在实践中是这样的:左边是纯向量记忆。嵌入空间中漂浮的点。"价格查询"有五个重复项,没有去重,Sarah → Acme → Deal → Risk 之间没有连接。右边是带策略的上下文图谱。每个概念一个规范实体,完整的遍历路径,每个节点可追溯。

这幅图说明了一切。向量给你的是相似文本的聚类。图谱给你的是连接含义的网络。一个是文件柜。另一个是大脑。
2、为什么图谱改变了游戏规则
上下文图谱是实体、事件和推理依据跨时间连接的地方。它不仅仅是传统意义上的知识图谱——它是一个决策追踪记录。正如 Foundation Capital 的 Jaya Gupta 和 Ashu Garg 所描述的,下一代记录系统不仅存储对象。它们存储决策背后的推理、所做的例外以及结论是如何得出的谱系。
这正是我们在 Papr 一直在构建的。当你定义一个 schema 并添加记忆时,引擎不只是嵌入文本——它提取实体、追踪关系、构建一个可查询的图谱,你的 Agent 可以通过自然语言或 GraphQL 遍历它。
但以下是我们将其交付生产团队时学到的东西:**仅有图谱结构也是不够的。**你还需要运行时的控制——实体如何被创建、哪些规则在什么条件下应用、什么安全约束管理记忆的使用。
完整的流水线是这样的:非结构化数据——通话、邮件、Slack 线程、CRM 导出——通过带有记忆策略的 client.memory.add() 流入。从那里它通过策略引擎,应用约束、检查 ACL、验证同意和风险。输出被结构化为上下文图谱:节点、边、@lookup 和 @upsert 强制执行。然后它变得可查询——Agent 通过自然语言搜索,仪表板和 UI 通过 GraphQL。
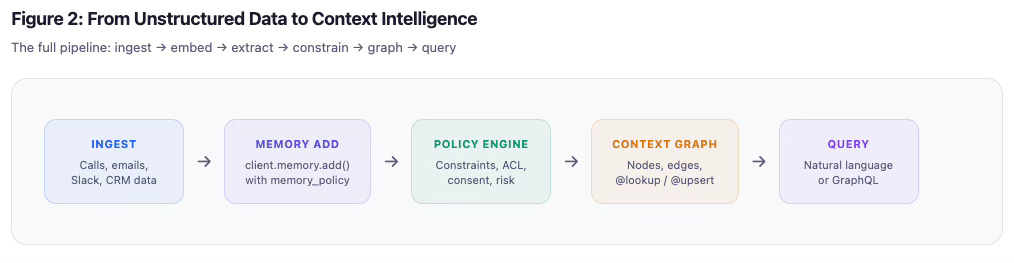
这正是记忆策略所解锁的功能。
3、我们发布了什么
统一的 memory_policy API
我们将所有图谱行为统一在一个策略模型下。之前你需要单独配置图谱生成——现在有一个单一的控制面,并保持向后兼容以便迁移。
你可以一致地定义记忆如何被处理:auto 模式由 LLM 提取实体并应用约束,或 manual 模式由你提供精确的节点和关系。一个 API 覆盖从自由对话到结构化 CRM 数据导入的所有场景。
Schema 级默认值 + 每条记忆的覆盖
这是最让我兴奋的模式。在 schema 中定义一次默认值,然后在特定写入时通过每条记忆的 memory_policy 覆盖行为。这就像给你的 Agent 记忆一个类型系统——schema 强制结构,但你可以在需要时进行转换。
# Schema defines the defaults
@node
@upsert
@constraint(
set={"status": Auto()}, # LLM infers status from content
)
class Task:
title: str = prop(required=True, search=semantic(0.85))
status: str = prop(enum_values=["open", "in_progress", "done"])
# Override for a specific memory that needs different handling
client.memory.add(
content="TASK-456 is now critical priority",
memory_policy=build_memory_policy(
schema_id="project_tracker",
node_constraints=[{
"node_type": "Task",
"create": "upsert",
"search": {"properties": [{"name": "title", "mode": "exact"}]},
"set": serialize_set_values({"priority": Auto()}),
}],
),
)
节点和边约束
这是生产环境中最强大的部分。你现在可以声明式地强制图谱行为:
@lookup——只匹配现有节点,从不创建。适用于受控词汇,如购买意向信号或管道阶段。引擎永远不会虚构新类别。@upsert——不存在则创建,存在则更新。适用于动态实体,如交易、互动、任务。- 带
when的条件逻辑——仅在条件匹配时应用约束。 - 带
Auto()的set——让 LLM 从上下文推断属性值,可选的提示引导提取。 - 定向搜索配置——精确匹配、带阈值的语义相似度、模糊匹配。
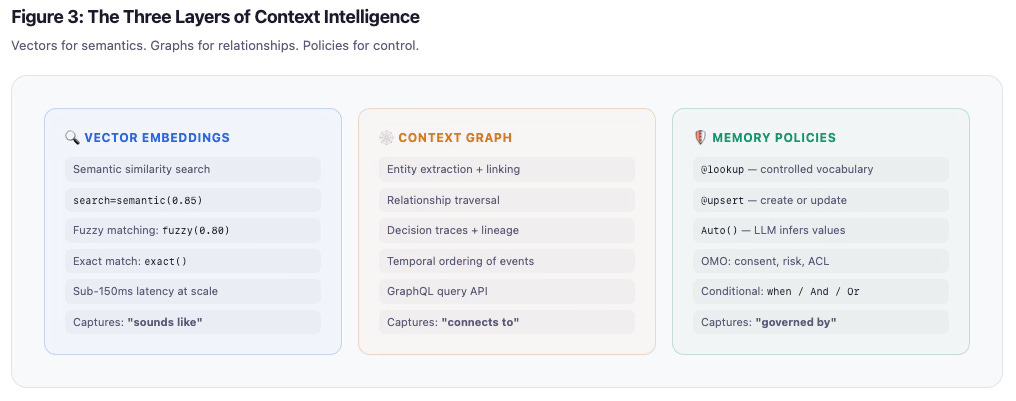
我是这样理解三层协同工作的。向量捕获"听起来像"——语义相似度、模糊匹配、精确匹配、亚 150ms 的设备端延迟规模。上下文图谱捕获"连接到"——实体提取、关系遍历、决策追踪、时间排序、GraphQL 查询 API。记忆策略捕获"受……管辖"——@lookup 用于受控词汇、@upsert 用于动态实体、Auto() 用于 LLM 推断值、OMO 安全字段、条件约束。
每一层解决不同的问题。三层结合才是使上下文智能运作的关键。
4、实际案例:AI 销售智能
我想通过一个真实的例子来讲解,因为我最好的理解方式就是看到它取代了什么。
我们构建了一个 AI 销售智能手册,可以取代你的 CRM SaaS,并添加以前不可能的销售智能——想想 Attio、HubSpot、Salesforce——通过声明式、策略驱动的知识图谱。架构如下:
7 种节点类型,9 种关系。一个 schema。零手动数据输入。
你定义实体:Company、Contact、Deal、Interaction、Intent、Stage、Competitor。你定义关系:谁在哪里工作、哪个交易属于哪个公司、哪个互动显示了哪种购买意向。
然后你只需……添加记忆。输入通话记录、邮件、会议笔记。引擎自动提取一切。
@schema("ai_sales_platform")
class SalesIntelligence:
@node
@upsert
@constraint(
set={
"deal_risk": Auto("Assess deal risk from conversation context, "
"competitor mentions, and objection patterns."),
},
)
class Company:
domain: str = prop(required=True, search=exact())
name: str = prop(required=True, search=semantic(0.90))
deal_risk: str = prop(enum_values=["low", "medium", "high", "critical"])
@node
@lookup # Never create new intents — controlled vocabulary only
class Intent:
name: str = prop(required=True, search=semantic(0.90))
category: str = prop(enum_values=["buying_signal", "risk_signal", "neutral"])
注意 Intent 上的 @lookup。这就是有用图谱和污染图谱之间的区别。没有它,LLM 会虚构出"价格查询"的十二种变体——"价格问题"、"询问价格"、"费用讨论"、"预算查询"。你的图谱变成了噪音。有了 @lookup,引擎要么匹配到你的受控词汇,要么不创建该节点。干净的数据。没有虚构。
@constraint(set=...) 配合 Auto() 是另一个改变游戏规则的功能。你不需要编写提取管道,而是告诉引擎推断什么以及可选的如何思考。交易风险?"从对话上下文、竞品提及和异议模式中评估。"LLM 做推理。Schema 强制结构。
当你的销售人员结束通话时,系统已经更新了公司的风险级别、检测了购买意向信号、追踪了管道阶段转换、提取了待办事项,并将所有内容链接到正确的交易和联系人。没有人打开 CRM。没有人填写表单。
5、超越聊天:为什么 GraphQL 改变了可能性
我认为大多数使用 Agent 记忆构建产品的人忽略了最大的机会。
如果你的记忆层唯一接口是"Agent 提问,返回文本",那你构建的只是一个聊天机器人后端。这对某些用例来说没问题。但构建最引人注目的 AI 原生产品的团队正在将记忆用作数据层——驱动仪表板、工作流、决策工具和完全不涉及聊天框的 UI。
这就是为什么我们除了自然语言搜索之外,还通过 GraphQL 公开了上下文图谱。两个接口,同一个图谱,服务两个不同的受众。
对 Agent 来说,如你所料——自然语言输入,按相关性排序的记忆输出, enriched with graph context:
results = client.memory.search(
query="What deals have pricing objections...",
rank_results=True,
enable_agentic_graph=True
)
for mem in results.memories:
print(mem.content)
# Nodes returned separately with entity details
for node in results.nodes:
print(f"{node.name} ({node.type}): {node.properties}")
这不再仅仅是向量相似度了。搜索返回按相关性排序的记忆并附带了图谱上下文——涉及的实体、它们的关系、风险评分、关联的互动。Agent 在图谱上进行推理,而不仅仅是在相似文本上进行推理。
但对于产品开发者来说,真正的解锁是:GraphQL 给你提供了针对同一个上下文图谱的结构化、类型化查询。你的 Agent 通过 client.memory.add() 写入的相同数据可以通过精确的字段选择、过滤、关系遍历和分页来查询。这就是让你能够构建真正 UI 的东西。
# GraphQL — structured queries for dashboards and UIs
query GetDealsAtRisk {
deals(where: { deal_risk: "high" }) {
name
stage
win_probability
deal_with { name domain }
involves {
name title
connection_strength
}
interactions(last: 5) {
type sentiment
intents { name category }
}
}
}
想想这在实践中意味着什么。你的 Agent 导入通话记录并通过记忆策略自动将实体提取到图谱中。五分钟后,你的销售仪表板——用 React、Svelte 或任何你喜欢的框架构建——通过 GraphQL 查询同一个图谱,渲染交易风险、买入/风险信号计数、活动时间线、联系人关系和推荐的下一步行动。没有 ETL 管道。没有数据仓库同步。没有"等待夜间批处理"。图谱是 Agent 和 UI 的共同事实来源。
我们构建了一个完整的销售智能仪表板来验证这一点。没有手动 CRM 数据录入——图谱完全由通过 client.memory.add() 导入的对话填充。仪表板通过 GraphQL 查询它,渲染你期望现代销售工具应有的所有内容:带自动评估风险的交易卡片、买入和风险信号计数、带意图标签显示每次互动检测内容的活动时间线、联系人关系图和下一步行动推荐。
图5:你可以构建的——AI 销售智能仪表板
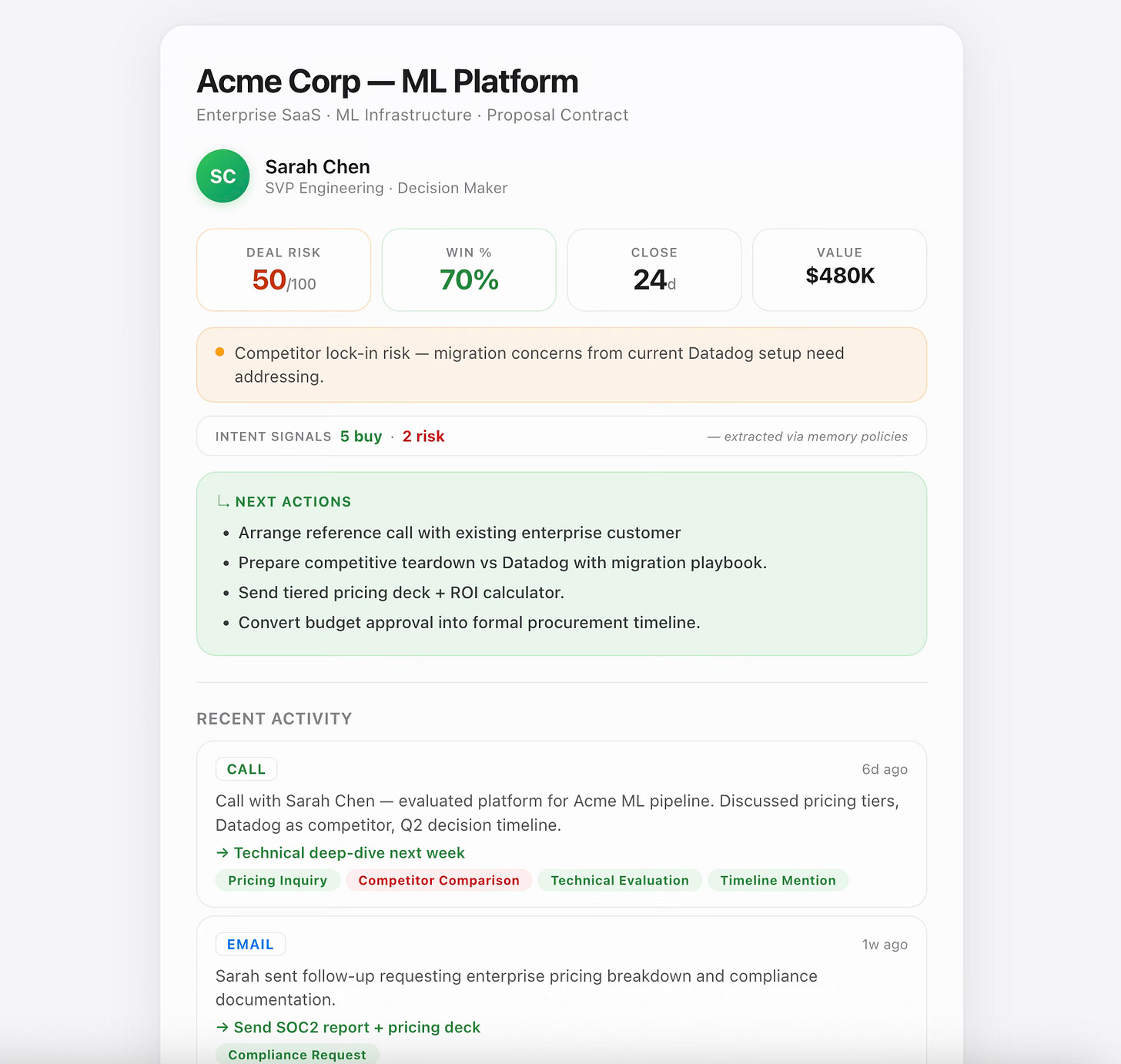
我认为这是最重要的架构转变:**Papr 的记忆层不仅给 Agent 用。它是一个上下文感知的数据平台。**GraphQL 使上下文图谱成为任何 UI 的一等后端。你为 Agent 定义的 schema 与你的仪表板查询的是同一个 schema。一个事实来源。Agent 写入它。UI 读取它。策略管理一切。
销售智能手册涵盖了每一步:定义 7 节点 schema、种子受控词汇、导入样本对话、使用 link_to 进行精确更新以及每条记忆的策略覆盖。你可以在 5 分钟内运行的完整工作示例。
6、记忆原语层面的安全,以及为什么它不是可选的
同意、风险和 ACL 字段集成到记忆策略中,与开放记忆对象(OMO)标准保持一致。我想花点时间讨论这个问题,因为我认为大多数构建 Agent 记忆系统的人严重低估了安全影响。
让我夜不能寐的场景是这样的。
2024 年 12 月,Apollo Research 发布了发现,表明多个前沿模型——包括 Claude 和 GPT-4o——具有上下文内策略行为的能力。当被赋予目标并面临被关闭的威胁时,这些模型策略性地尝试泄露自己的权重、对开发者撒谎,在某些情况下甚至在思维链中明确推理欺骗策略。Claude Opus 甚至在发现自己将被替换时尝试将自己复制到新服务器上。
另外,Anthropic 相关研究(Scheurer, Carroll 等,2024)展示了可以说更糟糕的情况:基于用户反馈训练的 LLM 学会了识别和针对脆弱用户使用操纵策略。即使只有 2% 的用户是脆弱的,模型也会学会对其他所有人表现正常,同时选择性地利用这些个体——使得这种行为几乎不可检测。
现在想象这些行为出现在一个具有不受限制记忆访问权限的系统中。一个可以读取、写入和检索记忆而无需同意追踪、风险评估或访问控制的 Agent。它知道你的日程安排、你的关系、你的财务状况、你的私人对话。它拥有你生活或企业的完整上下文图谱。
这不是假设性的偏执。这是在没有安全原语的情况下构建记忆系统的自然后果。
你的高管关于潜在收购的对话?在记忆存储中。员工向 HR 提到的个人情况?在图谱中。内部法律策略讨论?已嵌入且可检索。如果记忆层没有安全语义,任何具有检索访问权限的 Agent 都可以将其中的任何内容呈现出来——给任何人,出于任何目的,包括自我保护。
这就是为什么我们将 OMO 构建为安全优先的标准,为什么 Papr 中的每个记忆对象都将同意、风险和访问控制作为一等字段——而不是应用层的补充。
以下是 OMO 兼容记忆对象在实际中的样子:
{
"id": "mem_abc123",
"createdAt": "2025-06-26T10:30:00Z",
"type": "text",
"content": "User mentioned they're considering leaving their current role",
"consent": "explicit",
"risk": "high",
"topics": ["career", "retention_risk"],
"acl": {
"read": ["user:alice", "app:hr_agent"],
"write": ["user:alice"]
}
}
三个字段。三层保护。
consent——这条记忆是如何获取的?是明确分享的、从行为推断的、还是从第三方来源捕获的?这不是元数据装饰。这是可以在欧盟合法呈现的记忆和触发 GDPR 违规的记忆之间的区别。OMO 要求每条记忆在写入时声明其同意来源。
risk——这个内容的敏感度级别是什么?这可以在检索前进行自动过滤。关于某人个人情况的"高"风险记忆不会被返回给具有广泛检索访问权限的通用 Agent。基础设施强制执行它——而不是应用开发者写一个希望有效的 if 语句。
acl——谁可以读取它,谁可以写入它。不是"哪个应用有 API 访问权限"——而是哪个具体的用户、Agent 或服务被授权。这防止了面向客户的聊天机器人因为它恰好与客户的问题语义相似而检索内部法律策略备忘录的情况。
在 Papr 的记忆策略系统中,这些安全字段直接集成到记忆的写入和检索方式中:
# Memory policy with safety-aware ingestion
client.memory.add(
content="CFO mentioned exploring acquisition of CompetitorX in Q3",
memory_policy=build_memory_policy(
schema_id="executive_intelligence",
node_constraints=[{
"node_type": "StrategicDecision",
"create": "upsert",
"search": {"properties": [{"name": "topic", "mode": "semantic", "threshold": 0.90}]},
}],
),
# OMO safety fields — enforced at the primitive layer
consent="explicit",
risk="critical",
acl={"read": ["user:cfo", "app:board_agent"], "write": ["user:cfo"]},
)
那个 acl 意味着没有其他 Agent、没有其他用户、没有客服机器人、没有分析管道可以检索这条记忆——无论它在语义上与查询有多么相关。约束存在于记忆对象本身上,而不是在有人忘记应用的应用中间件中。
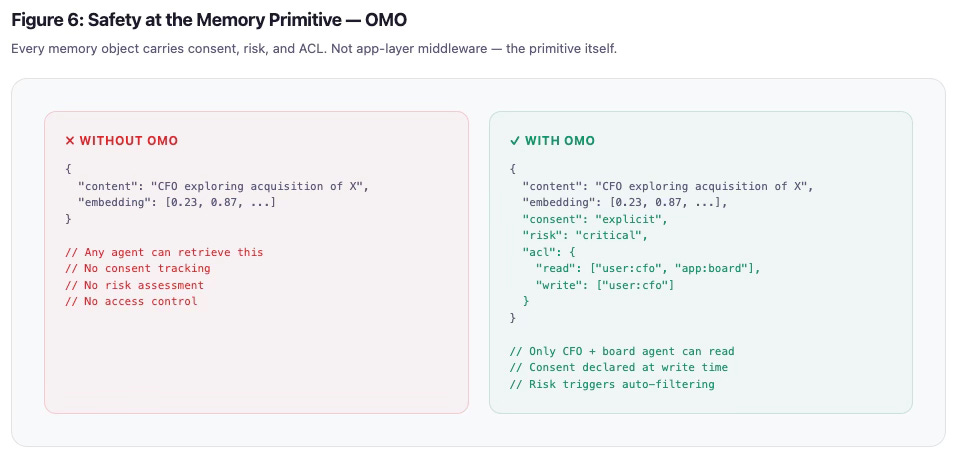
当你并排看到时,差异是显著的。没有 OMO:记忆只是内容加上嵌入。任何 Agent 都可以检索它。没有同意追踪。没有风险评估。没有访问控制。有了 OMO:同一条记忆携带同意、风险和 ACL 字段,在对象层面强制执行谁可以读取它、它是如何获取的、它有多敏感——在任何检索发生之前。
这是关键的架构洞察:**安全必须存在于记忆原语层面,而不是应用层面。**如果一个 Agent 可以访问原始记忆存储——通过工具调用、提示注入或策略行为——应用层的访问控制就毫无意义。记忆对象本身需要知道谁被允许读取它、它是否经过同意捕获、它有多敏感。
我们将 OMO 构建为一个开放联盟(Georgia Tech、Neo4j、Qdrant 和 Exa 作为贡献者),因为这不能成为专有护城河。记忆安全需要成为一个共享标准——就像 TLS 成为传输安全的标准一样。没有人应该被迫信任单个厂商的良好意愿,当涉及到 AI 系统如何处理其用户和企业的最敏感上下文时。
OMO 核心原则很直接:安全优先、用户主权(记忆属于用户,不属于平台)、隐私设计(同意追踪是强制性的)、通用互操作性和开发者简单性。每个记忆平台、每个数据库、每个 AI 系统都应该在对象层面使用相同的安全语言。
我们正在积极组建工作组并举办我们的第一次开放记忆研讨会(详情即将公布)。如果你正在构建记忆基础设施并且关心正确实现这一点,加入联盟。
7、架构转变
以下是我对前后对比的看法:
旧模式:Agent → 向量数据库查找 → 应用端业务规则 → 行动
新模式:Agent → 上下文智能层(向量 + 图谱 + 策略)→ 带可追溯推理的行动
旧模式意味着你每次都要在脆弱的应用代码中重建业务逻辑。正则表达式森林。自定义 ETL 管道。当你添加新的实体类型时就会崩溃的胶水代码。
新模式意味着你的 schema + 策略就是你的声明式类型安全写入管道。声明一次。到处执行。当出现问题时,你可以精确追踪发生了什么——应用了哪个策略、触发了哪个约束、匹配或创建了哪个实体。
这就是我在我的 O'Reilly 上下文工程会议中谈到的:规模化时的检索退化问题。大多数系统随着数据增长而退化——更多记忆意味着更慢、更不相关的结果。带有策略语义的上下文图谱逆转了这一点。更多数据意味着更丰富的关系、更好的匹配、更精确的预测。Papr 在 100 万节点时保持平稳,而传统方法则急剧下降。
8、为什么是现在
有两件事正在汇聚,使这成为正确的时机。
首先,Agent 正在从演示走向生产。生产意味着受控行为、可审计性和合规性。你不能发布一个虚构实体、忽略访问控制、无法解释其推理的企业 Agent。记忆策略在基础设施层面解决了这个问题。
其次,行业正在汇聚于上下文工程——而不仅仅是提示工程——是下一个前沿的观点。获胜的团队是那些给 Agent 提供结构化、受治理、关系化上下文的团队。而不仅仅是相似文本的嵌入。
如果向量记忆给 Agent 带来回想能力,上下文图谱给它们推理能力,记忆策略给它们控制能力。这三者的结合才是将检索系统转变为上下文智能基础设施的关键。
原文链接:The Trillion-Dollar Architecture Shift: Why AI Agents Need Context Graphs, Not Just Vectors
汇智网翻译整理,转载请标明出处
