12个最常用的Claude Code功能
在过去的几个月里一直坚持使用Claude Code,这篇帖子是我对Claude Code整个生态系统的一系列反思。
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI模型价格对比 | AI工具导航 | ONNX模型库 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我使用Claude Code。很多次。
作为一名业余爱好者,我每周几次在虚拟机中运行它用于侧边项目,通常使用--dangerously-skip-permissions来随意编写任何想法。在专业方面,我的团队构建了AI-IDE规则和工具,我们的工程团队每月消耗数十亿个标记用于代码生成。
CLI代理领域越来越拥挤,随着Claude Code、Gemini CLI、Cursor和Codex CLI,感觉真正的竞争是在Anthropic和OpenAI之间。但说实话,当我与其他开发者交谈时,他们的选择往往取决于一些“幸运”的功能实现或系统提示“氛围”他们只是喜欢。到目前为止,这些工具都相当不错。我也觉得人们经常过于关注输出风格或UI。比如对我来说,“你绝对正确!”的奉承并不是一个显著的错误;这是你太深入的信号。一般来说,我的目标是“发射并忘记”——委托,设置上下文,然后让它工作。根据最终的PR来评判工具,而不是它是如何到达那里的。
在过去的几个月里一直坚持使用Claude Code,这篇帖子是我对Claude Code整个生态系统的一系列反思。我们将涵盖几乎每一个我使用的功能(以及同样重要的是,我不使用的功能),从基础的CLAUDE.md文件和自定义斜杠命令到Subagents、Hooks和GitHub Actions的强大世界。这篇文章有点长,我建议它作为参考而不是通读全文。
1、CLAUDE.md
在你的代码库中有效使用Claude Code的最重要的文件是根CLAUDE.md。这个文件是代理的“宪法”,是其了解特定仓库工作的主要真相来源。
你对待这个文件的方式取决于上下文。对于我的业余项目,我让Claude随意在其中放置任何东西。
在我的专业工作中,我们单体仓库的CLAUDE.md被严格维护,目前大小为13KB(我可以看到它很容易增长到25KB)。
- 它只记录了被30%(任意)或更多工程师使用的工具和API(否则工具在产品或库特定的markdown文件中记录)
- 我们甚至开始为每个内部工具的文档分配最大token数量,几乎就像向团队出售“广告空间”。如果你不能简洁地解释你的工具,那么它就准备好进入
CLAUDE.md了。
1.1 提示和常见反模式
随着时间的推移,我们发展出了一种强烈的、有偏见的哲学来撰写有效的CLAUDE.md。
- 从守则开始,而不是手册。 你的
CLAUDE.md应该从小处开始,基于Claude弄错的内容进行记录。 - 不要
@-文件文档。 如果你在其他地方有大量文档,可能会想在你的CLAUDE.md中@提及那些文件。这会通过在每次运行时嵌入整个文件来增加上下文窗口的大小。但如果只是提到路径,Claude通常会忽略它。你必须向代理说明为什么和何时要阅读该文件。“对于复杂……的用法或如果遇到FooBarError,请参阅path/to/docs.md以获取高级故障排除步骤。” - 不要只说“永远不要”。 避免仅限于否定的约束,如“永远不要使用
--foo-bar标志。”代理会在认为它必须使用该标志时陷入困境。总是提供替代方案。 - 将
CLAUDE.md作为强制函数。 如果你的CLI命令复杂且冗长,不要写段落式的文档来解释它们。这是修补人类问题。相反,写一个简单的bash包装器,具有清晰、直观的API,并记录那个。保持你的CLAUDE.md尽可能简短是简化你的代码库和内部工具的绝佳强制函数。
这里是一个简化的快照:
# 单体仓库
## Python
- 始终...
- 使用<command>测试
... 10 更多...
## <内部 CLI 工具>
... 10 个要点,专注于 80% 的使用情况...
- <使用示例>
- 始终...
- 永远不要 <x>,优先使用 <Y>
对于 <复杂用法> 或 <错误>,请参阅 path/to/<tool>_docs.md
...
最后,我们保持这个文件与AGENTS.md同步,以与其他工程师可能使用的其他AI IDE保持兼容性。
如果你正在寻找编写用于编码代理的markdown的更多技巧,请参阅“AI无法阅读你的文档”,“AI驱动的软件工程”和“如何Cursor(AI IDE)工作”。
要点: 将你的CLAUDE.md视为一个高层次的、精心挑选的守则和指针集。用它来指导你在哪里需要投资更多的AI(和人类)友好工具,而不是试图使其成为一份全面的手册。
2、紧凑、上下文和清晰
我建议在编程会话中至少一次运行/context,以了解你是如何使用你的200k token上下文窗口的(即使使用Sonnet-1M,我也不会相信完整的上下文窗口实际上被有效地使用)。对于我们来说,在我们的单体仓库中,一次新的会话的基础成本约为20k tokens(10%),其余的180k tokens用于让你进行更改——这可以很快填满。
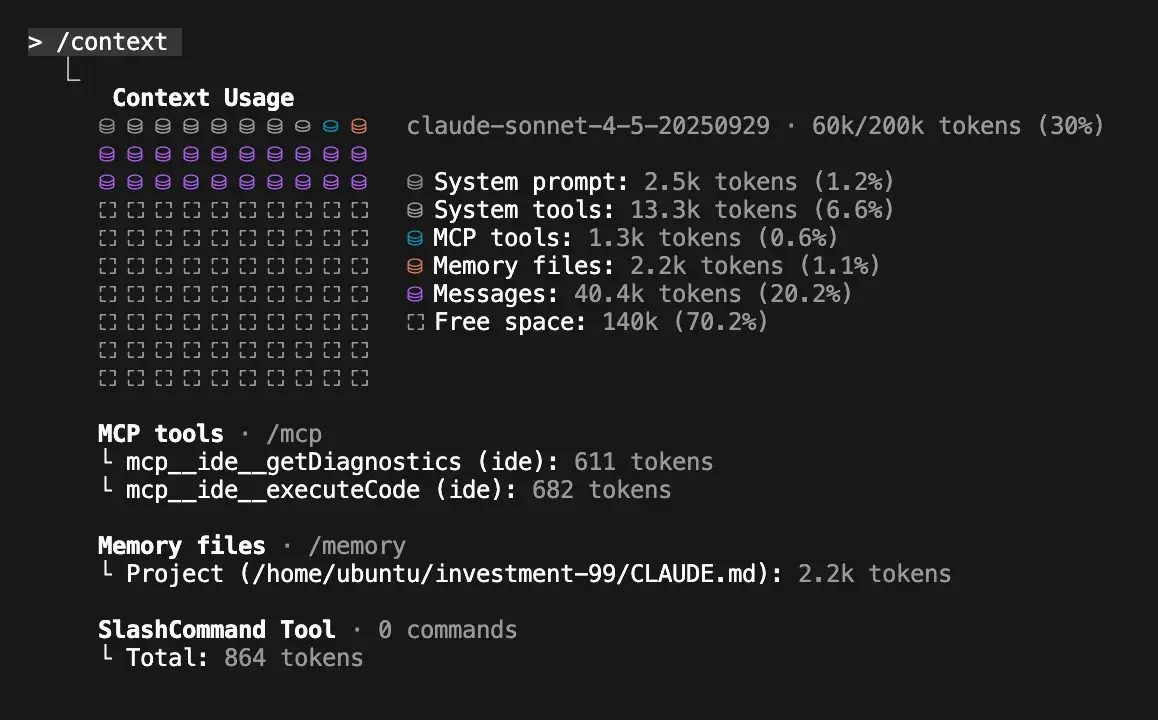
我在最近的一个侧边项目中的/context截图。你可以几乎把它看作是随着你在一个特性上工作的磁盘空间。几分钟或几小时后,你需要清除消息(紫色)以腾出空间继续。
我有三个主要工作流程:
/compact(避免): 我尽量避免这样做。自动压缩是不透明的、容易出错的,并且没有很好地优化。/clear+/catchup(简单重启): 我默认的重启。我/clear状态,然后运行自定义的/catchup命令,让Claude读取我当前git分支中所有更改的文件。- “文档 & 清除” (复杂重启): 对于大型任务。我让Claude将其计划和进度转储到
.md中,/clear状态,然后通过告诉它读取.md并继续来启动新会话。
要点: 不要信任自动压缩。使用/clear进行简单重启,使用“文档 & 清除”方法为复杂任务创建持久的外部“记忆”。
3、自定义斜杠命令
我认为斜杠命令是频繁使用提示的简单快捷方式,仅此而已。我的设置很简单:
/catchup: 我之前提到的命令。它只是提示Claude读取我当前git分支中所有更改的文件。/pr: 一个简单的帮助程序,清理我的代码,暂存它,并准备拉取请求。
在我看来,如果你有一长串复杂的自定义斜杠命令,你就创造了一个反模式。对我来说,代理如Claude的主要目的是你可以几乎输入任何你想输入的内容并得到有用且可合并的结果。一旦你强迫工程师(或非工程师)学习一个新列表的必要魔法命令才能完成工作,你就失败了。
要点: 将斜杠命令用作简单的个人快捷方式,而不是构建更直观的CLAUDE.md和更好的代理的替代品。
4、自定义子代理
从理论上讲,自定义子代理是Claude Code在上下文管理方面的最强大功能。其理念很简单:一个复杂任务需要X个token的输入上下文(例如,如何运行测试),积累Y个token的工作上下文,并产生一个Z个token的答案。运行N个任务意味着主窗口中的(X + Y + Z) * N个token。
子代理解决方案是将(X + Y) * N的工作转移到专门的代理中,只返回最终的Z个token答案,保持主上下文干净。
我发现它们是一个强大的想法,在实践中,自定义子代理创造了两个新问题:
- 它们限制了上下文: 如果我创建了一个
PythonTests子代理,我现在已经将所有测试上下文隐藏了我的主代理。它不能再全面地推理一个更改。它现在被迫调用子代理只是为了知道如何验证自己的代码。 - 它们迫使人工工作流程: 更糟糕的是,它们迫使Claude进入一个僵硬的人工定义的工作流程。我现在规定了它必须如何委派,这就是我试图让代理为我解决的问题。
我更喜欢使用Claude内置的Task(...)功能来生成一般代理的克隆。
我把所有关键上下文放在CLAUDE.md中。然后,我让主代理决定何时以及如何将工作委派给它自己的副本。这给了我子代理的所有上下文节省的好处,而没有缺点。代理自己动态管理其编排。
在我“构建多代理系统(第2部分)”的文章中,我称之为“主-克隆”架构,我强烈倾向于它而不是自定义子代理所鼓励的“领头-专家”模型。
要点: 自定义子代理是一种脆弱的解决方案。给你的主代理上下文(在CLAUDE.md中),并让它使用自己的Task/Explore(...)功能来管理委派。
5、恢复、继续和历史
从简单层面来看,我经常使用claude --resume和claude --continue。它们对于重新启动有bug的终端或快速重启旧会话非常有用。我经常会claude --resume几天前的会话,只是为了让代理总结它是如何克服特定错误的,然后我用它来改进我们的CLAUDE.md和内部工具。
更深入一点,Claude Code将所有会话历史存储在~/.claude/projects/中以访问原始的历史会话数据。我有脚本对这些日志进行元分析,寻找常见的异常、权限请求和错误模式,以帮助改善面向代理的上下文。
要点: 使用claude --resume和claude --continue来重新启动会话并揭示埋藏的历史上下文。
6、钩子
钩子非常重要。我不在业余项目中使用它们,但在复杂的企事业单位仓库中它们是至关重要的,用来引导Claude。它们是确定性的“必须做”的规则,补充了CLAUDE.md中的“应该做”的建议。
我们使用两种类型:
- 提交时阻断钩子: 这是我们主要的策略。我们有一个
PreToolUse钩子,它封装了任何Bash(git commit)命令。它检查/tmp/agent-pre-commit-pass文件,只有我们的测试脚本在所有测试通过时才会创建该文件。如果该文件缺失,钩子会阻止提交,迫使Claude进入“测试和修复”循环,直到构建成功。 - 提示钩子: 这些是简单的、非阻塞的钩子,如果代理做了次优的事情,提供“一劳永逸”的反馈。
我们有意不使用“写入时阻断”钩子(例如,在Edit或Write上)。在计划中途阻止代理会让它困惑甚至“沮丧”。让它完成工作,然后在提交阶段检查最终结果更为有效。
要点: 在提交时使用钩子来强制状态验证(block-at-submit)。避免在写入时阻断——让代理完成它的计划,然后检查最终结果。
7、规划模式
规划对于任何“大型”功能变更与AI IDE都是必不可少的。
对于我的业余项目,我只使用内置的规划模式。这是一种在它开始之前与Claude对齐的方式,定义了如何构建某物以及需要停止并展示其工作的“检查点”。经常使用这个建立了一种对最小上下文需求的强烈直觉,以获得良好的计划而不让Claude搞砸实现。
在我们的工作单体仓库中,我们已经开始推出一个基于Claude Code SDK的定制规划工具。它类似于原生的规划模式,但经过大量提示,使其输出与我们现有的技术设计格式一致。它还开箱即用地强制执行我们的内部最佳实践——从代码结构到数据隐私和安全。这让我们的工程师“感受”规划一个新功能,就像是一位资深架构师(或者至少是这样宣传的)。
要点: 总是使用内置的规划模式来在代理开始工作之前对齐计划。
8、技能
我同意Simon Willison的观点:技能可能是比MCP更大的事情。
如果你一直在关注我的帖子,你会知道我已经远离MCP用于大多数开发工作流,更喜欢构建简单的CLI(正如我在“AI无法阅读你的文档”中所争论的)。我对代理自主性的思维模型已经演变为三个阶段:
- 单个提示: 给代理全部上下文在一个巨大的提示中。(脆弱,不扩展)。
- 工具调用: “经典”的代理模型。我们手工制作工具并抽象现实以供代理使用。(更好,但创建了新的抽象和上下文瓶颈)。
- 脚本: 我们给予代理对原始环境(二进制文件、脚本和文档)的访问,并让它即时编写代码与其交互。
考虑到这一点,代理技能是显而易见的下一步功能。它们是“脚本”层的正式产品化。
如果你像我一样已经偏向CLI而不是MCP,你已经在隐式地获得技能的好处。SKILL.md文件只是更有序、可共享和可发现的方式来记录这些CLI和脚本并将其暴露给代理。
要点: 技能是正确的抽象。它们形式化了基于“脚本”的代理模型,这比MCP代表的刚性、API式模型更具鲁棒性和灵活性。
9、MCP(模型上下文协议)
技能并不意味着MCP已死(另见“MCP的全部错误”)。以前,许多人建立了可怕的、上下文密集的MCP,包含数十个工具,仅仅镜像了一个REST API(read_thing_a(),read_thing_b(),update_thing_c())。
“脚本”模型(现在由技能正式化)更好,但它需要一种安全的方式来访问环境。对我来说,这是MCP的新、更专注的角色。
MCP不应该是一个庞大的API,而是一个简单的、安全的网关,提供几个强大的、高层的工具:
download_raw_data(filters…)take_sensitive_gated_action(args…)execute_code_in_environment_with_state(code…)
在这个模型中,MCP的任务不是为代理抽象现实;它的任务是管理认证、网络和安全边界,然后退居一旁。它为代理提供了入口点,然后代理使用其脚本和markdown上下文来完成实际工作。
我仍然使用的唯一MCP是Playwright,这很合理——它是一个复杂的状态化环境。我所有的无状态工具(如Jira、AWS、GitHub)已被迁移到简单的CLI中。
要点: 使用MCP作为数据网关。为代理提供一两个高层工具(如原始数据转储API),然后让它进行脚本处理。
10、Claude Code SDK
Claude Code不仅仅是一个交互式CLI;它也是构建全新代理(用于编码和非编码任务)的强大SDK。我已经开始将其作为我的默认代理框架,用于大多数新的业余项目,而不是工具如LangChain/CrewAI。
我使用它主要有三种方式:
- 大规模并行脚本: 对于大规模重构、错误修复或迁移,我不使用交互聊天。我编写简单的bash脚本,调用
claude -p “in /pathA change all refs from foo to bar”并行。这比试图让主代理管理几十个子代理任务要更加可扩展和可控。 - 构建内部聊天工具: SDK非常适合将复杂过程封装在一个简单的聊天界面中,供非技术人员使用。比如一个安装程序,当出现错误时,会回退到Claude Code SDK来直接为用户解决问题。或者一个公司内部的“v0-at-home”工具,允许我们的设计团队在我们内部的UI框架中感受式地编写前端原型,确保他们的想法是高保真的,代码在前端生产代码中更直接可用。
- 快速代理原型: 这是我最常见的用途。它不仅用于编码。如果我有任何关于任何代理任务的想法(例如,“威胁调查代理”使用自定义CLI或MCP),我会使用Claude Code SDK快速构建和测试原型,然后再投入完整的部署结构。
要点: Claude Code SDK是一个强大、通用的代理框架。用于批量处理代码、构建内部工具和快速原型化新代理,在你选择更复杂的框架之前。
11、Claude Code GHA
Claude Code GitHub Action(GHA)可能是我最喜欢的并且最容易被忽视的功能之一。它是一个简单的概念:只需在GHA中运行Claude Code。但这种简单性使它如此强大。
它类似于Cursors的后台代理或Codex管理的网页UI,但更加可定制。你控制整个容器和环境,给你更多的数据访问,而且最关键的是,比任何其他产品提供的更强的沙盒和审计控制。此外,它支持所有高级功能,如Hooks和MCP。
我们使用它来构建自定义的“从任何地方生成PR”的工具。用户可以从Slack、Jira甚至CloudWatch警报触发PR,GHA会修复错误或添加功能并返回一个完全测试的PR1。
由于GHA日志是完整的代理日志,我们有一个运营流程定期在公司级别审查这些日志,以查找常见的错误、bash错误或不符合工程实践的情况。这创建了一个数据驱动的飞轮:错误 -> 改进的CLAUDE.md / CLIs -> 更好的代理。
$ query-claude-gha-logs --since 5d | claude -p “看看其他Claudes卡在什么问题上并解决它,然后提交一个PR”
要点: GHA是操作Claude Code的终极方式。它将它从一个个人工具转变为一个核心、可审计和自我改进的工程系统的一部分。
12、settings.json
最后,我发现一些特定的settings.json配置对于业余和专业工作都很重要。
HTTPS_PROXY/HTTP_PROXY: 这对于调试很有用。我会用它来检查原始流量,以确切查看Claude发送了哪些提示。对于背景代理,它也是精细网络沙盒的强大工具。MCP_TOOL_TIMEOUT/BASH_MAX_TIMEOUT_MS: 我会提高这些值。我喜欢运行长时间、复杂的命令,而默认的超时时间通常太保守。说实话,我不确定现在有了bash后台任务是否还需要这个,但我还是保留它以防万一。ANTHROPIC_API_KEY: 在工作中,我们使用企业API密钥(通过apiKeyHelper)。这使我们从“按座位”许可证转向“按使用量”定价,这对于我们的工作方式来说是一个更好的模型。- 它考虑了开发人员使用量的巨大差异(我们看到工程师之间的差异高达1:100倍)。
- 它让工程师可以尝试非Claude Code LLM脚本,都在我们的单一企业账户下。
“permissions”: 我偶尔会自我审核允许Claude自动运行的命令列表。
要点: 你的settings.json是一个强大的高级自定义场所。
13、结束语
这有很多内容,但希望你觉得有用。如果你还没有使用像Claude Code或Codex CLI这样的基于CLI的代理,你可能应该使用。这些高级功能很少有好的指南,所以学习的唯一方法就是深入实践。
原文链接:How I Use Every Claude Code Feature
汇智网翻译整理,转载请标明出处
