15种最经典的AI智能体设计模式
给那些想要正确的模式、而不是最炫酷模式的工程师的实战指南。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
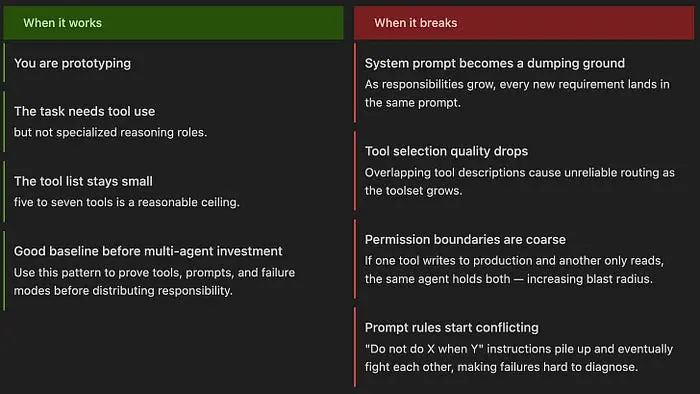
团队构建 智能体系统 有一条可预见的演进路径。它从简单开始:一个提示词、一个循环、几个工具。然后现实介入——新需求、更多团队、合规要求、更复杂的工作流。突然之间,一个循环承载了多个关注点,塞进一个过大的系统提示词中。架构争论开始了:继续扩展它,还是迁移到多 Agent 系统,或者引入一个框架? 通常,团队会意见分歧。
本指南面向的是争论占据主导之前的那一刻。它涵盖了生产环境智能体系统中使用的主要模式、每种模式何时适用,以及相关的权衡取舍。示例使用基于类的 Python——这是你在代码审查中真正会看到的代码,而不是演示级别的代码片段。
我们将跟随一家公司:一个名为 Vend 的电商平台。他们的 AI 平台团队从一个客服 Agent 开始,在十八个月内,逐步演进为一个涵盖多种模式的系统。每一次转变都有其原因。理解决策背后的原因比记住模式本身更重要。
0、在选择模式之前
当以下至少一个条件为真时,一个任务才值得使用 Agent:
- 一次单次模型调用无法产生可靠的结果。
- 模型必须在运行时在工具或数据源之间做出选择。
- 任务需要规划、验证或迭代优化。
- 工作流包含无法通过静态业务逻辑表达的不确定性。
当输入到输出的路径是可预测的时,任务通常不值得使用 Agent。
像摘要、分类、模板化生成和简单提取这类任务,作为直接的模型调用通常是更快、更便宜、更可靠的。
将它们包装在 Agent 中通常会增加延迟、故障点和不必要的复杂性,而不会带来有意义的价值。
0.1 共享基础设施
所有示例都使用以下基础结构。在生产环境中,你需要添加重试机制、请求 ID、结构化日志、限速处理、预算跟踪、策略检查和持久化状态。
import json
import os
import asyncio
from dataclasses import dataclass, field
from typing import Any
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
MODEL = "gpt-4o"
@dataclass
class AgentResult:
content: str
tool_calls: list[dict] = field(default_factory=list)
metadata: dict = field(default_factory=dict)
class BaseLLMAgent:
def __init__(self, model: str = MODEL):
self.client = client
self.model = model
def _text(self, system: str, user: str) -> str:
response = self.client.responses.create(
model=self.model,
input=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
)
return response.output_text
def _structured(self, system: str, user: str, schema: dict[str, Any]) -> dict[str, Any]:
response = self.client.responses.create(
model=self.model,
input=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
text={"format": {"type": "json_schema", "name": "output", "schema": schema, "strict": True}},
)
return json.loads(response.output_text)
模式 1:单 Agent [第 1 个月]
AI 团队接到了第一个任务:让客户无需等待人工客服就能查询订单问题。工作流程很直接——查找订单、检查物流状态、必要时创建支持工单。三个工具,一个明确的职责。
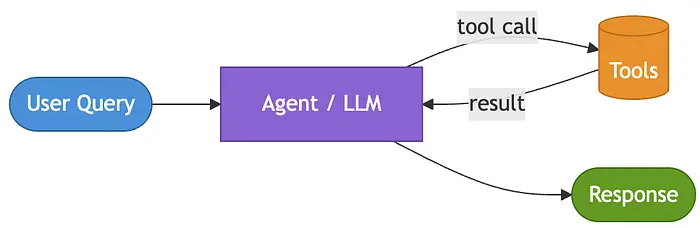
这是大多数智能体系统应该开始的地方:一个模型、一个系统提示词和一组有限的工具。模型决定调用哪个工具,观察结果,并继续执行直到有足够的上下文来回应。更简单的系统更容易推理、调试和改进。
import json
from openai import OpenAI
from dataclasses import dataclass
@dataclass
class OrderContext:
order_id: str
status: str
carrier: str
eta: str
@dataclass
class SupportTicket:
ticket_id: str
order_id: str
reason: str
class CustomerSupportAgent(BaseLLMAgent):
"""Single-agent that handles order support by choosing its own tools."""
SYSTEM_PROMPT = (
"You are a customer support agent. Use tools when order data is needed. "
"Do not invent order status. If the issue cannot be resolved from tools, create a ticket."
)
TOOLS = [
{
"type": "function",
"name": "get_order",
"description": "Fetch order status by order ID.",
"parameters": {
"type": "object",
"properties": {"order_id": {"type": "string"}},
"required": ["order_id"],
"additionalProperties": False,
},
},
{
"type": "function",
"name": "create_support_ticket",
"description": "Create a support ticket when the issue cannot be answered from order data.",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string"},
"reason": {"type": "string"},
},
"required": ["order_id", "reason"],
"additionalProperties": False,
},
},
]
def _get_order(self, order_id: str) -> dict:
# Replace with real DB/API call
return {"order_id": order_id, "status": "shipped", "carrier": "DHL", "eta": "2026-06-01"}
def _create_support_ticket(self, order_id: str, reason: str) -> dict:
return {"ticket_id": "SUP-1042", "order_id": order_id, "reason": reason}
def _dispatch_tool(self, name: str, args: dict) -> dict:
if name == "get_order":
return self._get_order(**args)
if name == "create_support_ticket":
return self._create_support_ticket(**args)
return {"error": f"Unknown tool: {name}"}
def run(self, user_message: str, max_turns: int = 4) -> str:
messages = [
{"role": "system", "content": self.SYSTEM_PROMPT},
{"role": "user", "content": user_message},
]
for _ in range(max_turns):
response = self.client.responses.create(
model=self.model, input=messages, tools=self.TOOLS
)
tool_calls = [item for item in response.output if item.type == "function_call"]
if not tool_calls:
return response.output_text
messages += response.output
for call in tool_calls:
result = self._dispatch_tool(call.name, json.loads(call.arguments))
messages.append({
"type": "function_call_output",
"call_id": call.call_id,
"output": json.dumps(result),
})
return "I could not complete the request safely within the tool budget."
何时使用以及何时失效:
模式 2:多 Agent 顺序执行 [第 3 个月]
法务部门收到供应商合同,审查流程很明确:提取义务条款、识别风险条款、为采购经理起草摘要。顺序永远不会改变,每个步骤产出的正是下一步所需的。

顺序模式按固定顺序运行专业化 Agent。每个 Agent 都有一个狭窄的提示词和清晰的输入/输出契约。编排是确定性的——推理发生在每个阶段内部,而不是 Agent 之间的路由中,使得流程可预测且可审计。
from dataclasses import dataclass
@dataclass
class ContractAnalysis:
obligations: str
risks: str
review_packet: str
class ContractIntakePipeline(BaseLLMAgent):
"""Sequential pipeline: extract → assess → draft."""
def _extract_obligations(self, contract_text: str) -> str:
return self._text(
"Extract concrete obligations from vendor contracts. "
"Return only obligations with dates, parties, or deliverables.",
contract_text,
)
def _assess_risks(self, obligations: str) -> str:
return self._text(
"You are a contract risk reviewer. Identify operational, financial, and compliance risks. "
"Do not provide legal advice.",
obligations,
)
def _draft_review_packet(self, contract_text: str, obligations: str, risks: str) -> str:
return self._text(
"Prepare a concise contract review packet for a procurement manager. "
"Include obligations, risks, and questions for counsel.",
f"Contract:\\\\n{contract_text}\\\\n\\\\nObligations:\\\\n{obligations}\\\\n\\\\nRisks:\\\\n{risks}",
)
def run(self, contract_text: str) -> ContractAnalysis:
obligations = self._extract_obligations(contract_text)
risks = self._assess_risks(obligations)
packet = self._draft_review_packet(contract_text, obligations, risks)
return ContractAnalysis(obligations=obligations, risks=risks, review_packet=packet)
何时使用以及何时失效:

模式 3:多 Agent 并行执行 [第 5 个月]
值班团队在午夜收到告警:结账功能正在失败。三个信号需要立即排查——应用日志、基础设施指标和最近的部署。这些是真正独立的信息来源。顺序执行它们会浪费事故中最关键的最初几分钟。
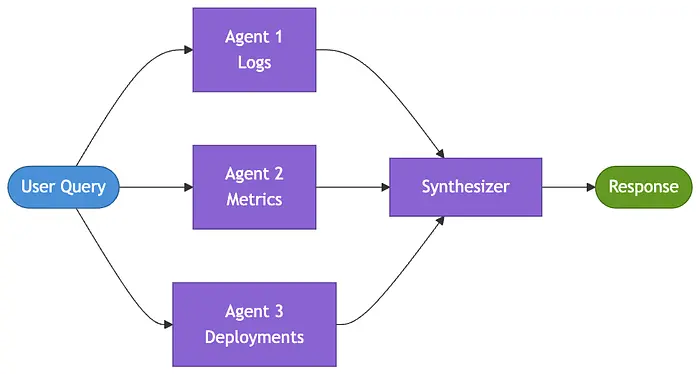
并行模式将独立的子任务同时分配给多个 Agent,并将它们的输出合并为一个统一视图。当任务之间互不依赖时,并行化可以降低延迟,加快压力下的决策速度。
import asyncio
from dataclasses import dataclass
@dataclass
class IncidentReport:
log_analysis: str
metric_analysis: str
deployment_analysis: str
synthesis: str
class IncidentTriageAgent(BaseLLMAgent):
"""Parallelizes three specialist agents then synthesizes a root-cause hypothesis."""
async def _ask_specialist(self, role_prompt: str, incident: str) -> str:
return await asyncio.to_thread(self._text, role_prompt, incident)
async def run(self, incident_description: str) -> IncidentReport:
log_prompt = "You inspect application logs. Identify error patterns with timestamps and request IDs."
metric_prompt = "You inspect metrics. Identify saturation, latency spikes, and traffic anomalies."
deploy_prompt = "You inspect recent releases. Flag risky changes that align with the reported symptoms."
log_view, metric_view, deploy_view = await asyncio.gather(
self._ask_specialist(log_prompt, incident_description),
self._ask_specialist(metric_prompt, incident_description),
self._ask_specialist(deploy_prompt, incident_description),
)
synthesis = self._text(
"You are the incident commander. Synthesize evidence from three specialist views. "
"State confidence level and the single safest next action.",
f"Logs:\\\\n{log_view}\\\\n\\\\nMetrics:\\\\n{metric_view}\\\\n\\\\nDeployments:\\\\n{deploy_view}",
)
return IncidentReport(
log_analysis=log_view,
metric_analysis=metric_view,
deployment_analysis=deploy_view,
synthesis=synthesis,
)
何时使用以及何时失效:

模式 4:循环 [第 6 个月]
数据工程团队需要接入第三方供应商提供的 CSV 数据,其中数据质量常常不一致。他们需要一个能够分析数据、提出清洗策略、根据质量检查进行验证,并在需要时重试的 Agent。

循环模式重复执行一系列 Agent 步骤,直到退出条件满足。挑战不在于循环本身——而在于定义一个可靠的停止条件。没有它,你最终会面临失控的成本、不可预测的行为以及无法保证终止。
import json
from dataclasses import dataclass
@dataclass
class CleaningResult:
plan: str
rounds_taken: int
passed: bool
class DataQualityRepairAgent(BaseLLMAgent):
"""Iteratively proposes and judges cleaning plans until quality passes or budget is exhausted."""
QUALITY_SCHEMA = {
"type": "object",
"properties": {
"passes": {"type": "boolean"},
"reason": {"type": "string"},
"remaining_issues": {"type": "array", "items": {"type": "string"}},
},
"required": ["passes", "reason", "remaining_issues"],
"additionalProperties": False,
}
def _profile(self, sample_rows: str) -> str:
return self._text(
"Profile tabular data. Identify missing values, inconsistent formats, "
"suspicious categories, and likely schema issues.",
sample_rows,
)
def _propose_plan(self, profile: str, previous_plan: str | None) -> str:
return self._text(
"Propose a safe pandas cleaning plan. Prefer reversible transformations. "
"Do not drop columns unless explicitly justified.",
f"Profile:\\\\n{profile}\\\\n\\\\nPrevious attempt:\\\\n{previous_plan or 'None'}",
)
def _judge(self, profile: str, plan: str) -> dict:
return self._structured(
"Judge whether the cleaning plan addresses the data profile without unsafe assumptions.",
f"Profile:\\\\n{profile}\\\\n\\\\nPlan:\\\\n{plan}",
self.QUALITY_SCHEMA,
)
def run(self, sample_rows: str, max_rounds: int = 3) -> CleaningResult:
profile = self._profile(sample_rows)
plan = None
for round_num in range(1, max_rounds + 1):
plan = self._propose_plan(profile, plan)
verdict = self._judge(profile, plan)
if verdict["passes"]:
return CleaningResult(plan=plan, rounds_taken=round_num, passed=True)
# Append reviewer feedback to the profile so the next proposal is informed
profile += f"\\\\nReviewer feedback (round {round_num}):\\\\n{json.dumps(verdict)}"
return CleaningResult(plan=plan, rounds_taken=max_rounds, passed=False)
何时使用以及何时失效:

注意: 这是一个使用 LLM-as-a-Judge 来审查和批准另一个模型响应的简化示例。
在这个示例中,流程使用了一个带有布尔审批标志的循环。在实践中,有许多变体。评审者可以返回一个分数,而不是二元决策,或者提供结构化反馈供生成器用于改进下一次迭代。这里的设计空间很广,所以我故意保持实现简洁。
✅ 模式 5:审查与批评 → 一个评审 Agent 审查输出,提出批评,并提供可操作的反馈指出需要改进的地方。
✅ 模式 6:迭代优化 → 系统在带有分数阈值的反馈循环中运行。直到响应达到所需的质量标准,生成器才会继续优化输出。
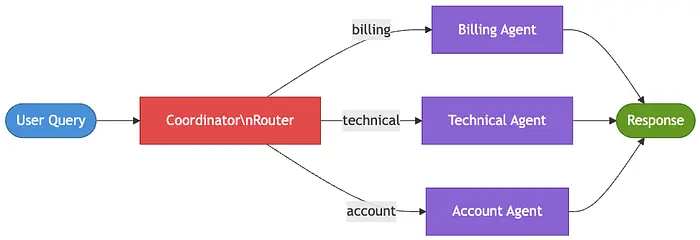
模式 7:协调器 [第 9 个月]
客服已扩展到五个独立部门:账单、技术支持、账户管理、物流和欺诈。一个试图处理所有这些的单 Agent 最终会依赖一个 3000 字的系统提示词,在边缘情况和冲突指令面前力不从心。到了这个阶段,问题不再是提示词质量——不同的请求类型确实需要不同的上下文、工具和决策逻辑。
协调器模式引入一个中央路由 Agent,将传入的请求引导到专业化 Agent。与顺序或并行工作流不同,执行路径是在运行时根据请求的性质动态确定的。这使得每个 Agent 保持专注,降低了提示词复杂性,并在系统扩展时提高了可靠性。
from dataclasses import dataclass
@dataclass
class RoutingDecision:
specialist: str
reason: str
class SupportCoordinator(BaseLLMAgent):
"""Routes support messages to the right specialist agent."""
ROUTING_SCHEMA = {
"type": "object",
"properties": {
"specialist": {
"type": "string",
"enum": ["billing", "technical", "account", "shipping", "fraud"],
},
"reason": {"type": "string"},
},
"required": ["specialist", "reason"],
"additionalProperties": False,
}
SPECIALISTS: dict[str, str] = {
"billing": "You handle billing support. Request invoice IDs when needed. Never quote prices from memory.",
"technical": "You handle technical troubleshooting. Ask for logs and environment details when needed.",
"account": "You handle account access issues. Never request passwords or raw secrets.",
"shipping": "You handle delivery and tracking questions. Escalate customs issues to a human agent.",
"fraud": "You handle suspected fraud reports. Collect evidence carefully. Never accuse the customer.",
}
def _route(self, message: str) -> RoutingDecision:
result = self._structured(
"Route this support request to exactly one specialist based on the primary issue.",
message,
self.ROUTING_SCHEMA,
)
return RoutingDecision(**result)
def _run_specialist(self, specialist_prompt: str, message: str) -> str:
return self._text(specialist_prompt, message)
def run(self, message: str) -> str:
decision = self._route(message)
specialist_prompt = self.SPECIALISTS[decision.specialist]
return self._run_specialist(specialist_prompt, message)
何时使用以及何时失效:

模式 8:层次化任务分解 [第 11 个月]
战略部门向 AI 平台团队提出:"明年我们应该扩展到哪三个国家?" 这不是一个典型的支持任务——它是一个多维度的研究问题。没有任何一个 Agent 能可靠地回答它。这个问题需要分解为竞争分析、监管约束、物流可行性和市场规模评估,每个方面都需要专业化的上下文和推理能力。
层次化分解模式使用一个根 Agent 将复杂目标分解为更小的、定义明确的子目标,然后将其委托给专业化的工作 Agent。一旦工作完成,根 Agent 将输出综合为一个连贯的建议。当问题过于宽泛,无法通过单次推理解决,但可以分解为独立的专业领域时,这种模式效果最好。
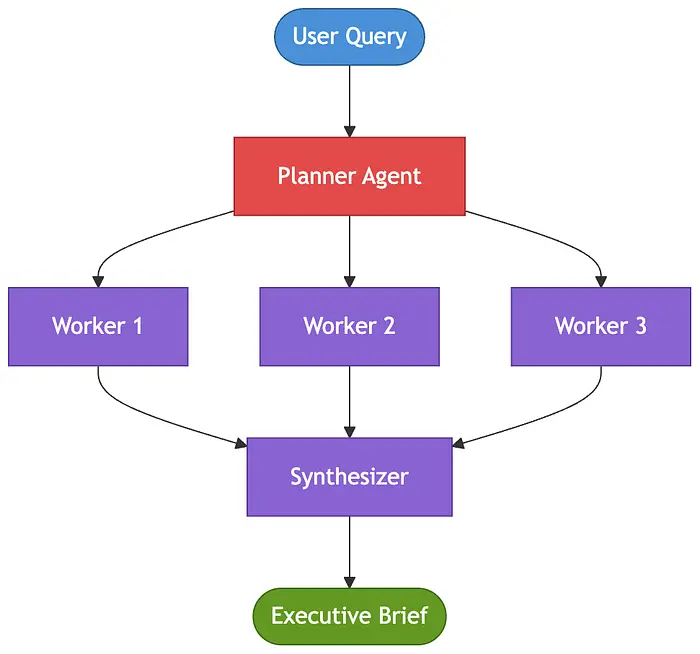
import json
from dataclasses import dataclass
@dataclass
class Workstream:
name: str
deliverable: str
questions: list[str]
@dataclass
class ResearchBrief:
goal: str
workstreams: list[Workstream]
reports: list[str]
synthesis: str
class MarketExpansionResearchAgent(BaseLLMAgent):
"""Decomposes a research goal into workstreams, executes each, and synthesizes results."""
PLAN_SCHEMA = {
"type": "object",
"properties": {
"workstreams": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {"type": "string"},
"deliverable": {"type": "string"},
"questions": {"type": "array", "items": {"type": "string"}},
},
"required": ["name", "deliverable", "questions"],
"additionalProperties": False,
},
}
},
"required": ["workstreams"],
"additionalProperties": False,
}
def _plan(self, goal: str) -> list[Workstream]:
result = self._structured(
"Break a market expansion research goal into 3 to 5 independent workstreams. "
"Each workstream must have a clear deliverable and 2-4 focused questions.",
goal,
self.PLAN_SCHEMA,
)
return [Workstream(**ws) for ws in result["workstreams"]]
def _execute_workstream(self, ws: Workstream) -> str:
return self._text(
"You are a specialist research agent. Answer only the assigned workstream. "
"List assumptions and evidence gaps separately. Be specific.",
json.dumps({"name": ws.name, "deliverable": ws.deliverable, "questions": ws.questions}),
)
def _synthesize(self, goal: str, reports: list[str]) -> str:
combined = "\\\\n\\\\n".join(
f"--- Workstream {i+1} ---\\\\n{r}" for i, r in enumerate(reports)
)
return self._text(
"Synthesize specialist research reports into an executive brief. "
"Highlight conflicts between workstreams, unsupported assumptions, and missing evidence.",
f"Goal: {goal}\\\\n\\\\nWorkstream reports:\\\\n{combined}",
)
def run(self, goal: str) -> ResearchBrief:
workstreams = self._plan(goal)
reports = [self._execute_workstream(ws) for ws in workstreams]
synthesis = self._synthesize(goal, reports)
return ResearchBrief(goal=goal, workstreams=workstreams, reports=reports, synthesis=synthesis)
何时使用以及何时失效:

模式 9:群体智能 [第 12 个月]
产品团队面临一个有争议的问题:他们应该推出订阅层级吗? 研究表明客户有这个需求。工程团队估计需要六个月的计费基础设施工作。财务部门质疑单位经济学是否合理,而客服团队预计会出现客户困惑和工单量的激增。每个观点都是合理的,但团队需要一种方式在领导层做出决策之前呈现这些权衡。
群体智能模式允许多个专业化 Agent 为一个共享的工作上下文做出贡献。每个 Agent 带来不同的视角,挑战假设,并添加支持性证据。一旦积累了足够的信号,一个协调 Agent 将讨论综合为一条建议。当目标不是单一的"正确"答案,而是由相互竞争的观点塑造的合理决策时,这种模式效果最好。
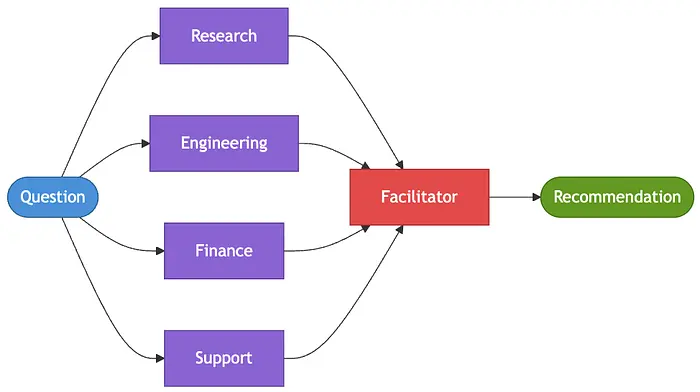
from dataclasses import dataclass
@dataclass
class DebateResult:
question: str
transcript: str
recommendation: str
class ProductDecisionSwarm(BaseLLMAgent):
"""Runs a structured debate across specialist perspectives before synthesizing a recommendation."""
ROLES: dict[str, str] = {
"research": "You represent user research. Cite evidence, customer segments, and unmet needs. Challenge unsupported claims.",
"engineering": "You represent engineering. Assess feasibility, complexity, risks, and maintenance burden.",
"finance": "You represent finance. Evaluate pricing, margin, cost, and opportunity cost.",
"support": "You represent customer support. Assess operational burden, edge cases, and customer confusion risks.",
}
def run(self, question: str, rounds: int = 2) -> DebateResult:
transcript = f"Decision question: {question}\\\\n"
for round_no in range(1, rounds + 1):
for name, role_prompt in self.ROLES.items():
contribution = self._text(
role_prompt + " Respond to the current transcript. "
"Add new evidence or challenge a specific weak claim. Be concise and specific.",
transcript,
)
transcript += f"\\\\n[{name}, round {round_no}]\\\\n{contribution}\\\\n"
recommendation = self._text(
"You are a neutral decision facilitator. Review the full debate. "
"Summarize the strongest arguments, identify unresolved risks, and state a final recommendation. "
"Do not add new claims - only synthesize what is already in the transcript.",
transcript,
)
return DebateResult(question=question, transcript=transcript, recommendation=recommendation)
何时使用以及何时失效:

模式 10:ReAct(推理与行动)[第 13 个月]
DevOps 团队构建了一个内部故障排查助手。当工程师报告**"队列处理器似乎卡住了"时,助手应该搜索文档、检查服务状态、关联症状,然后才建议修复方案**。排查路径无法预先定义——它完全取决于系统在过程中发现了什么。
ReAct 模式在推理和行动之间交替:决定调查什么、调用工具、观察结果,然后判断是否有足够的证据来继续或回答。最有价值的输出不是隐藏的推理过程本身——而是行动追踪记录,它使调查过程变得可观察、可调试,并且更容易在生产中建立信任。
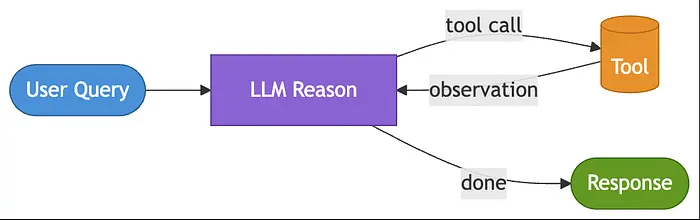
import json
from dataclasses import dataclass
@dataclass
class TroubleshootingResult:
answer: str
action_trace: list[dict]
class KnowledgeBaseTroubleshootingAgent(BaseLLMAgent):
"""Iteratively calls tools to gather evidence before stating a root cause."""
SYSTEM_PROMPT = (
"You are a troubleshooting agent. Use tools to gather evidence. "
"Return the likely cause, your confidence level, and the next safe action. "
"Do not speculate beyond what the tools returned."
)
TOOLS = [
{
"type": "function",
"name": "search_docs",
"description": "Search internal troubleshooting documentation by keyword.",
"parameters": {
"type": "object",
"properties": {"query": {"type": "string"}},
"required": ["query"],
"additionalProperties": False,
},
},
{
"type": "function",
"name": "get_service_status",
"description": "Get current operational status and recent incidents for a service.",
"parameters": {
"type": "object",
"properties": {"service": {"type": "string"}},
"required": ["service"],
"additionalProperties": False,
},
},
]
def _search_docs(self, query: str) -> dict:
return {"matches": ["Restart workers after QUEUE_URL change", "Check IAM permission sqs:SendMessage"]}
def _get_service_status(self, service: str) -> dict:
return {"service": service, "status": "degraded", "since": "2026-05-21T09:20:00Z"}
def _dispatch_tool(self, name: str, args: dict) -> dict:
if name == "search_docs":
return self._search_docs(**args)
if name == "get_service_status":
return self._get_service_status(**args)
return {"error": f"Unknown tool: {name}"}
def run(self, problem: str, max_turns: int = 5) -> TroubleshootingResult:
messages = [
{"role": "system", "content": self.SYSTEM_PROMPT},
{"role": "user", "content": problem},
]
action_trace = []
for _ in range(max_turns):
response = self.client.responses.create(
model=self.model, input=messages, tools=self.TOOLS
)
calls = [item for item in response.output if item.type == "function_call"]
if not calls:
return TroubleshootingResult(answer=response.output_text, action_trace=action_trace)
messages += response.output
for call in calls:
args = json.loads(call.arguments)
result = self._dispatch_tool(call.name, args)
action_trace.append({"tool": call.name, "args": args, "result": result})
messages.append({
"type": "function_call_output",
"call_id": call.call_id,
"output": json.dumps(result),
})
return TroubleshootingResult(
answer="Investigation limit reached without sufficient evidence.",
action_trace=action_trace,
)
何时使用以及何时失效:
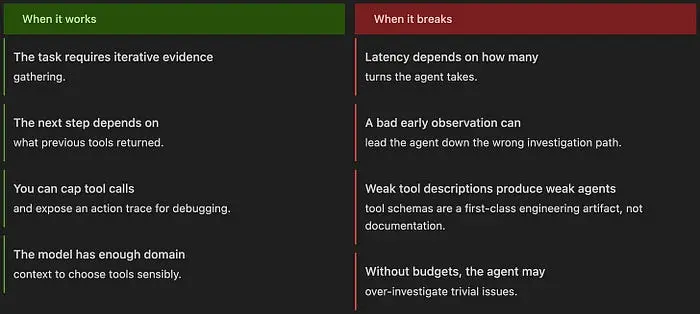
模式 11:人机协同 [第 14 个月]
财务团队希望自动化退款审批,但仅限于低风险、明确的情况。涉及高额金额、欺诈信号或政策例外的请求仍需要人工审批。Agent 的角色是调查案件、收集上下文并建议操作——最终决策权在人。
这种模式不仅仅是一个 UI 工作流——它是一个架构决策。你需要持久化状态、审核人分配、审批日志、超时处理、升级路径和安全恢复机制。Agent 的职责是准备证据并移交上下文,而不是无限期地暂停等待人工响应。

import json
from dataclasses import dataclass
@dataclass
class HumanApproval:
approved: bool
reviewer: str
comment: str
@dataclass
class RefundOutcome:
recommendation: str
approval: HumanApproval
customer_response: str
class RefundApprovalAgent(BaseLLMAgent):
"""Investigates refund request, prepares recommendation, pauses for human approval."""
def _lookup_context(self, order_id: str) -> dict:
# Replace with real payment service call
return {
"order_id": order_id,
"amount": 420.00,
"days_since_purchase": 12,
"prior_refunds": 0,
"fraud_score": 0.02,
}
def _build_recommendation(self, customer_message: str, context: dict) -> str:
return self._text(
"You are a refund operations agent. Recommend approve, deny, or request more information. "
"Cite specific policy facts. Do not approve if fraud score exceeds 0.1.",
f"Customer message:\\\\n{customer_message}\\\\n\\\\nOrder context:\\\\n{json.dumps(context)}",
)
def _request_human_approval(self, recommendation: str) -> HumanApproval:
# In production: create a review task in the ops queue (Slack, Jira, internal tool).
# Block until approved or timed out. This stub simulates a reviewer response.
return HumanApproval(
approved=False,
reviewer="ops-manager",
comment="Ask customer for photos of the damaged item first.",
)
def _draft_customer_response(self, recommendation: str, approval: HumanApproval) -> str:
review_summary = json.dumps({"approved": approval.approved, "comment": approval.comment})
return self._text(
"Draft a customer-safe response based on the manager's review decision. "
"Do not claim the refund is approved unless it is. Be empathetic but accurate.",
f"Agent recommendation:\\\\n{recommendation}\\\\n\\\\nHuman review:\\\\n{review_summary}",
)
def run(self, order_id: str, customer_message: str) -> RefundOutcome:
context = self._lookup_context(order_id)
recommendation = self._build_recommendation(customer_message, context)
approval = self._request_human_approval(recommendation)
customer_response = self._draft_customer_response(recommendation, approval)
return RefundOutcome(
recommendation=recommendation,
approval=approval,
customer_response=customer_response,
)
何时使用以及何时失效:

模式 12:计划与执行 [第 15 个月]
DevOps 团队希望有一个 Agent 能从自然语言请求中处理多步骤基础设施操作:"将工作节点集群从 10 个实例扩展到 20 个,验证队列排空,并更新运维手册。" 目标很明确,但确切的执行路径取决于系统在每一步发现了什么。
计划与执行模式将规划与执行分离。一个规划 Agent 首先对策略进行推理并生成一个结构化的任务计划,然后再采取任何行动。这个计划可以由人类审查、修改或批准。然后一个执行 Agent 逐步执行,在执行过程中根据需要调整。

这与层次化分解不同,后者将任务递归地分解为子目标。这里,规划是一次性分解为执行计划。它也与 ReAct 不同——整个计划从一开始就可见,而不是通过行动和观察逐步浮现。
import json
from dataclasses import dataclass
@dataclass
class ExecutionStep:
step_id: int
action: str
tool: str
parameters: dict
expected_outcome: str
@dataclass
class ExecutionPlan:
goal: str
steps: list[ExecutionStep]
@dataclass
class ExecutionResult:
plan: ExecutionPlan
step_results: list[dict]
summary: str
class PlanAndExecuteAgent(BaseLLMAgent):
"""Generates a structured plan before taking any actions, then executes step by step."""
PLAN_SCHEMA = {
"type": "object",
"properties": {
"steps": {
"type": "array",
"items": {
"type": "object",
"properties": {
"step_id": {"type": "integer"},
"action": {"type": "string"},
"tool": {"type": "string", "enum": ["resize_fleet", "check_queue_depth", "update_runbook"]},
"parameters": {"type": "object", "additionalProperties": {"type": "string"}},
"expected_outcome": {"type": "string"},
},
"required": ["step_id", "action", "tool", "parameters", "expected_outcome"],
"additionalProperties": False,
},
}
},
"required": ["steps"],
"additionalProperties": False,
}
def _plan(self, goal: str) -> ExecutionPlan:
result = self._structured(
"Create a step-by-step execution plan for the given infrastructure task. "
"Order steps by dependency. Use only available tools.",
goal,
self.PLAN_SCHEMA,
)
steps = [ExecutionStep(**s) for s in result["steps"]]
return ExecutionPlan(goal=goal, steps=steps)
def _execute_step(self, step: ExecutionStep) -> dict:
# Real implementation would dispatch to infrastructure APIs
return {"step_id": step.step_id, "status": "completed", "output": f"Executed: {step.action}"}
def _summarize(self, plan: ExecutionPlan, results: list[dict]) -> str:
return self._text(
"Summarize the execution results. Flag any steps that did not complete as expected.",
f"Goal: {plan.goal}\\\\n\\\\nResults:\\\\n{json.dumps(results, indent=2)}",
)
def run(self, goal: str) -> ExecutionResult:
plan = self._plan(goal)
step_results = []
for step in plan.steps:
result = self._execute_step(step)
step_results.append(result)
# In production: halt here if the step failed; surface for human review
if result.get("status") != "completed":
break
summary = self._summarize(plan, step_results)
return ExecutionResult(plan=plan, step_results=step_results, summary=summary)
何时使用以及何时失效:

模式 13:反思 [第 16 个月]
数据团队希望 AI 平台能生成一次性数据转换的 Python 脚本。第一次尝试通常能编译成功但在运行时失败,通常是因为边缘情况或意外输入。团队希望 Agent 能够分析错误、理解出了什么问题,并用更好的方法重试,而不是将失败升级给人工。
反思模式赋予 Agent 从自身失败中学习的能力。与由外部评审驱动重试的标准循环模式不同,Agent 评估自己的输出、反思失败,并记录出了什么问题的观察。这些记忆随后直接影响下一次尝试,随着时间推移提升性能,而不是重复相同的错误。
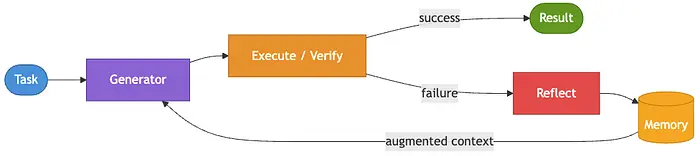
import json
from dataclasses import dataclass
@dataclass
class ReflexionMemory:
attempt: int
output: str
error: str | None
reflection: str
@dataclass
class ReflexionResult:
final_output: str
memory: list[ReflexionMemory]
succeeded: bool
class ReflexionCodingAgent(BaseLLMAgent):
"""Generates code, simulates execution, reflects on failures, and retries with accumulated memory."""
REFLECTION_SCHEMA = {
"type": "object",
"properties": {
"succeeded": {"type": "boolean"},
"error_analysis": {"type": "string"},
"what_to_fix": {"type": "string"},
},
"required": ["succeeded", "error_analysis", "what_to_fix"],
"additionalProperties": False,
}
def _generate(self, task: str, memory: list[ReflexionMemory]) -> str:
memory_context = "\\\\n\\\\n".join(
f"Attempt {m.attempt}: FAILED\\\\nError: {m.error}\\\\nReflection: {m.reflection}"
for m in memory
if m.error
)
return self._text(
"Write a Python function for the given data transformation task. "
"Handle edge cases explicitly. Learn from past failures.",
f"Task:\\\\n{task}\\\\n\\\\nPast failures:\\\\n{memory_context or 'None yet'}",
)
def _execute_and_observe(self, code: str) -> tuple[str | None, str | None]:
"""Returns (output, error). Replace with sandbox execution in production."""
try:
# Simulate execution - in production use a sandbox (e.g., subprocess, E2B)
exec_globals: dict = {}
exec(compile(code, "<agent>", "exec"), exec_globals)
return "Executed successfully", None
except Exception as e:
return None, str(e)
def _reflect(self, code: str, error: str) -> str:
result = self._structured(
"Analyze why this code failed. Identify the root cause and what should change in the next attempt.",
f"Code:\\\\n{code}\\\\n\\\\nError:\\\\n{error}",
self.REFLECTION_SCHEMA,
)
return result["what_to_fix"]
def run(self, task: str, max_attempts: int = 3) -> ReflexionResult:
memory: list[ReflexionMemory] = []
for attempt in range(1, max_attempts + 1):
code = self._generate(task, memory)
output, error = self._execute_and_observe(code)
if error is None:
memory.append(ReflexionMemory(attempt=attempt, output=code, error=None, reflection="Succeeded"))
return ReflexionResult(final_output=code, memory=memory, succeeded=True)
reflection = self._reflect(code, error)
memory.append(ReflexionMemory(attempt=attempt, output=code, error=error, reflection=reflection))
return ReflexionResult(final_output=memory[-1].output, memory=memory, succeeded=False)
何时使用以及何时失效:

模式 14:自定义逻辑 [第 18 个月]
退款工作流已经超出了每一种整洁的架构模式。高价值的损坏商品退款遵循与标准退货不同的路径。欺诈信号将案件路由到专业人员。某些检查可以并行运行,其他则需要人工审批,某些情况需要商店积分而非现金退款。到了这个阶段,业务流程包含了真正的分支逻辑,而这些分支往往带有法律或财务后果。
自定义逻辑模式将确定性编排与智能体行为相结合。挑战在于决定什么属于代码、什么属于模型。资格规则、权限检查、支付操作和安全约束应保持确定性和可审计。同时,涉及解释、起草、路由建议和异常处理的任务通常是模型最能发挥价值的地方。
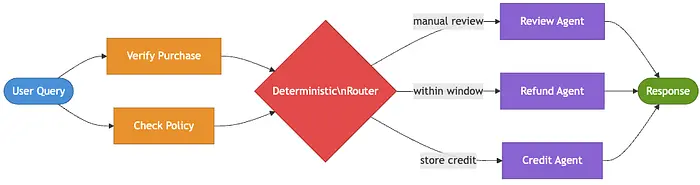
import asyncio
import json
from dataclasses import dataclass
@dataclass
class PurchaseVerification:
order_id: str
purchased_by_user: bool
amount: float
@dataclass
class RefundPolicy:
within_window: bool
damaged_item_reported: bool
fraud_flag: bool
requires_manual_review: bool
@dataclass
class WorkflowResult:
path: str
output: str
class RefundOrchestrator(BaseLLMAgent):
"""Custom workflow: parallel checks → deterministic routing → agentic response drafting."""
async def _verify_purchase(self, order_id: str) -> PurchaseVerification:
# Replace with real payment service call
return PurchaseVerification(order_id=order_id, purchased_by_user=True, amount=89.99)
async def _evaluate_policy(self, order_id: str) -> RefundPolicy:
# Replace with real policy service call
return RefundPolicy(
within_window=False,
damaged_item_reported=True,
fraud_flag=False,
requires_manual_review=True,
)
def _draft_manual_review_packet(self, context: dict) -> str:
return self._text(
"Prepare a manual review packet for operations. "
"Include the customer claim, policy status, decision points, and missing evidence.",
json.dumps(context),
)
def _draft_refund_confirmation(self, context: dict) -> str:
return self._text(
"Draft an internal refund processing note. Include only confirmed facts from context.",
json.dumps(context),
)
def _draft_store_credit_offer(self, context: dict) -> str:
return self._text(
"Draft a customer response offering store credit. "
"Explain the policy reason clearly without being dismissive.",
json.dumps(context),
)
async def run(self, order_id: str, customer_message: str) -> WorkflowResult:
# Run eligibility checks in parallel - they are independent
purchase, policy = await asyncio.gather(
self._verify_purchase(order_id),
self._evaluate_policy(order_id),
)
context = {
"customer_message": customer_message,
"purchase": {"purchased_by_user": purchase.purchased_by_user, "amount": purchase.amount},
"policy": {
"within_window": policy.within_window,
"damaged_item_reported": policy.damaged_item_reported,
"fraud_flag": policy.fraud_flag,
},
}
# Deterministic routing - these rules must not be delegated to the model
if not purchase.purchased_by_user:
return WorkflowResult(path="denied", output="Refund denied: requester is not the purchaser.")
if policy.fraud_flag:
return WorkflowResult(path="fraud_hold", output="Refund held: fraud flag active. Routing to fraud team.")
if policy.requires_manual_review:
return WorkflowResult(path="manual_review", output=self._draft_manual_review_packet(context))
if policy.within_window:
return WorkflowResult(path="approved", output=self._draft_refund_confirmation(context))
return WorkflowResult(path="store_credit", output=self._draft_store_credit_offer(context))
何时使用以及何时失效:

模式 15:事件驱动 Agent
欺诈团队意识到他们最大的挑战不是路由,而是时机。等到支持工单标记可疑活动时,阻止或干预交易的机会往往已经过去。他们不需要等待指令的 Agent——他们需要在重要事件发生的瞬间做出反应的 Agent。
到目前为止讨论的大多数模式都是请求驱动的:它们在用户或系统明确请求某事时才开始。事件驱动模式则不同。它是异步和响应式的,订阅事件流,如 Kafka 主题、webhook 或数据库变更流。当预定义的条件被触发时,Agent 自动唤醒并采取行动,无需等待人工请求。

import asyncio
import json
from dataclasses import dataclass
from datetime import datetime
@dataclass
class FraudEvent:
event_id: str
user_id: str
amount: float
merchant: str
timestamp: str
risk_signal: str # e.g., "velocity_spike", "new_device", "geo_anomaly"
@dataclass
class FraudDecision:
event_id: str
action: str # "block" | "flag" | "allow"
reasoning: str
triggered_at: str
class FraudDetectionAgent(BaseLLMAgent):
"""
Reacts to real-time fraud events. In production, subscribe this to a Kafka consumer
or webhook endpoint rather than calling run() directly.
"""
DECISION_SCHEMA = {
"type": "object",
"properties": {
"action": {"type": "string", "enum": ["block", "flag", "allow"]},
"reasoning": {"type": "string"},
},
"required": ["action", "reasoning"],
"additionalProperties": False,
}
async def _enrich_context(self, event: FraudEvent) -> dict:
"""Fetch user history and merchant reputation - replace with real API calls."""
return {
"user_prior_disputes": 0,
"merchant_risk_tier": "medium",
"transaction_count_last_hour": 7,
}
def _decide(self, event: FraudEvent, context: dict) -> dict:
return self._structured(
"You are a fraud risk analyst. Evaluate the transaction event and enriched context. "
"Only block when evidence is strong. Flag when uncertain. Allow when risk is low.",
f"Event:\\\\n{json.dumps(event.__dict__)}\\\\n\\\\nContext:\\\\n{json.dumps(context)}",
self.DECISION_SCHEMA,
)
async def handle_event(self, event: FraudEvent) -> FraudDecision:
context = await self._enrich_context(event)
decision = self._decide(event, context)
return FraudDecision(
event_id=event.event_id,
action=decision["action"],
reasoning=decision["reasoning"],
triggered_at=datetime.utcnow().isoformat(),
)
async def run_consumer_loop(self, event_queue: asyncio.Queue) -> None:
"""Consume events from an async queue - wire to Kafka/webhook in production."""
while True:
event = await event_queue.get()
decision = await self.handle_event(event)
# Publish decision back to event bus, audit log, or action service
print(f"[{decision.triggered_at}] {decision.event_id}: {decision.action} - {decision.reasoning}")
event_queue.task_done()
何时使用以及何时失效:

模式选择总结
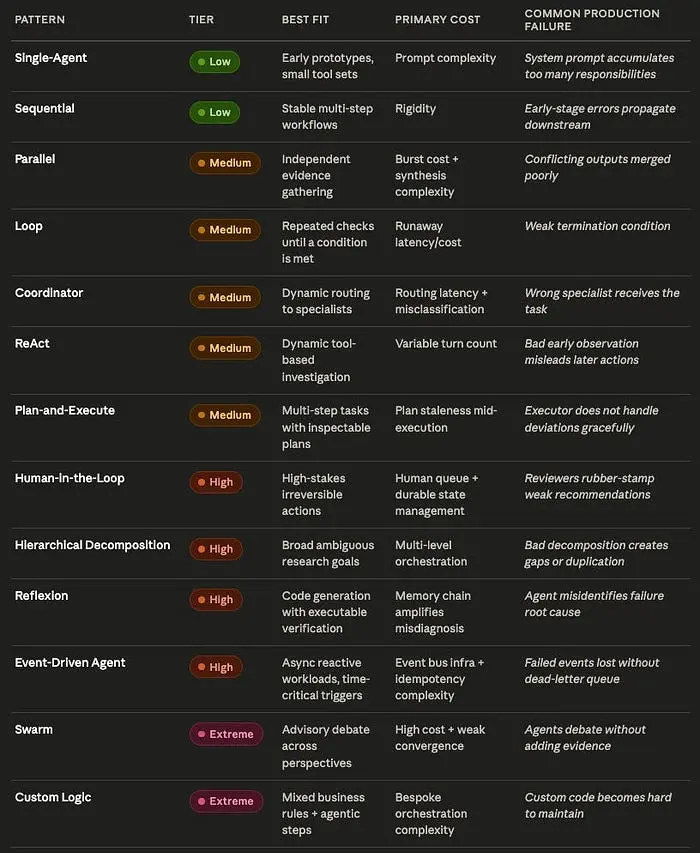
生产环境智能体系统的十条规则:
- 从能用的最小模式开始。 一个拥有良好工具契约的单 Agent,胜过一个工具契约薄弱的多 Agent 架构。
- 给每个工具一个狭窄的 schema 和诚实的描述。 工具描述不是文档——它们是模型了解工具行为的唯一信息源。像写契约一样写它们。
- 限制每次请求的迭代次数、工具调用次数和总花费。 没有预算限制的 Agent 迟早会在账单审查中变成一个麻烦。
- 记录行动追踪。 模型请求 ID、选择的工具、参数、输出摘要和最终决策。没有这些,事故调查就是猜谜。
- 将不可逆操作放在确定性检查或人工审批之后。 模型永远不应该是用户输入和数据库写入、资金转移或生产变更之间的唯一关卡。
- 用真实的失败案例评估 Agent,而不仅仅是正常路径的提示词。 能正确处理正常路径的 Agent 是原型。能正确处理边缘情况的 Agent 才是产品。
- 在系统提示词变得不可读之前,按职责拆分提示词。 当你发现自己往系统提示词里加"但在 Y 的情况下不要做 X"时,这就是 Agent 在做两份工作的信号。
- 将多 Agent 系统视为分布式系统。 部分失败、超时、重试、所有权归属和可观察性不是可选的。它们是自主性的代价。
- 模型评审不能替代确定性验证。 使用批评者、评审者和审查者来提高质量。使用测试、策略引擎、权限检查和数据库约束来强制正确性。
- 选择更简单的模式。 不是因为简单总是更好——而是因为在编排层节省的复杂性预算可以花在真正重要的事情上:更好的工具、更好的提示词和更好的评估。
正确的形态
Agent 设计模式不是成熟度等级。如果任务只需要一个可靠的工具使用型 Agent,那么群体智能并不比单 Agent 系统更高级。如果业务流程已经稳定,层次化分解并不比顺序管道更好。如果在第三步之前计划就已经过时了,计划与执行也不是 ReAct 的升级。
正确的模式是能够匹配工作中不确定性的形态的那个:
- 工具选择上的不确定性 → 单 Agent 或 ReAct
- 路由上的不确定性 → 协调器
- 质量上的不确定性 → 审查与批评或迭代优化
- 执行路径上的不确定性 → 计划与执行或 ReAct
- 自我纠正上的不确定性 → 反思或循环
- 业务风险上的不确定性 → 人机协同或自定义逻辑
- 问题结构上的不确定性 → 层次化分解或群体智能
- 时机上的不确定性(无法等待用户请求) → 事件驱动 Agent
- 规模化输出质量上的不确定性 → LLM-as-Judge
最可靠的生产系统通常不是最自主的那些。它们是在能创造价值的地方精确地放置自主性,并在其他所有地方加以约束的系统。
原文链接: The 15 AI Agent Design Patterns Every Engineer Should Know (With Production Examples)
汇智网翻译整理,转载请标明出处
