TRivia-3B 表格OCR模型
将表格图像转换为HTML或Markdown等结构化格式听起来很简单,但真正的瓶颈不在模型本身……
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
将表格图像转换为HTML或Markdown等结构化格式听起来很简单,但真正的瓶颈不在模型,而在于标签。
获得更好的准确性仍然在很大程度上依赖于更多的人工标注数据。随着人工标注成本的持续攀升,开源模型(通常是隐私敏感场景中唯一可行的选择)越来越落后于拥有大量资源支持的封闭商业系统。
本文提供了一个有益的视角。
1、为什么表格识别在标签方面一直遇到瓶颈
瓶颈主要是方法论上的:表格识别长期以来依赖监督学习。尽管视觉语言模型(VLM)已经大幅提高了上限,但进一步发展仍然面临同样的老问题:对标记数据的巨大需求。
还有一个部署现实。 对于许多用例,由于隐私或合规问题,将敏感文档发送到商业API是不可行的。这使得可离线部署的开源VLM成为许多隐私监管环境中的更可行选择,但它们受到现有标记TR数据集规模有限的制约,难以匹敌专有性能。在有限数据/资源下,开源模型仍然远远落后于专有模型。
所以核心问题是: 不是要求更多标记数据,我们能否直接从未标记的表格图像中提取有意义的训练信号?如果可能,这可能是推动表格识别超越当前极限的关键。
2、通过问答将未标记表格转化为可优化奖励
TRivia采取了实用的转向。它不再仅仅依赖人工标注的HTML或OTSL序列作为监督。相反,它引入了 表格问答(QA)作为代理奖励信号。
这种方法有两个明显的优势:
- 生成QA奖励比标注完整标记更容易。 奖励生成过程不需要明确推断像
colspan或rowspan这样的复杂结构。它只需要回答关于表格小的局部区域的特定问题。这使得任务更轻量、更灵活,更适合大规模无标签数据。 - QA是可验证的。 答案可以被检查。你可以使用外部模型来确认问题是否可以根据表格正确回答,以及答案是否依赖于视觉证据。当模型被要求直接生成完整HTML时,这种验证几乎是不可能的。
3、采样→问题生成→强化学习(带稳定器)
将TRivia视为一个自动化训练流程。它的整个过程归结为三个关键阶段,每个部分发挥特定作用。
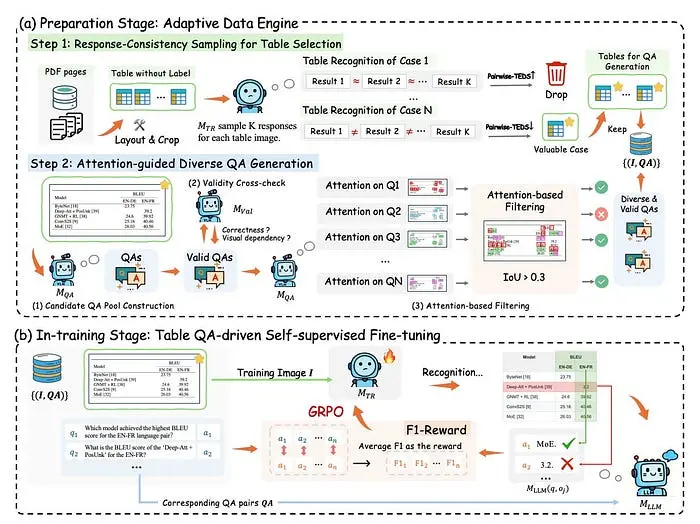
- 采样:通过测量模型对未标记表格的不确定性来选择最有用的样本。响应一致性采样通过输出多样性来测量不确定性:它为每个图像采样多个TR输出,并计算基于TEDS的一致性分数。在数据集构建中,TRivia还过滤掉一致性过低(噪声)的情况,并在0.4-1.0范围内采样,而不是只取最不确定的样本。
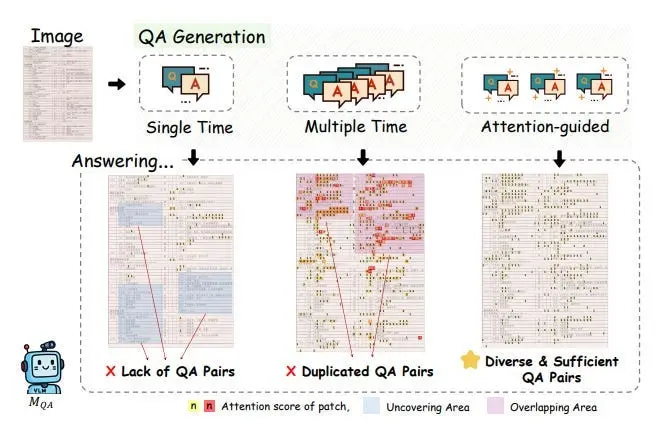
- 问题生成:基于注意力的多样化QA生成是一个三步过程:构建多样本QA候选池,交叉验证视觉依赖性(有图像可回答,无图像不可回答),然后选择注意力导出的视觉源重叠度低(IOU阈值化)的QA对,以提高覆盖率并减少冗余。
3. 强化学习(表格QA驱动的GRPO + 非法样本过滤):使用QA F1分数作为奖励,并过滤掉可能向训练注入噪声的损坏输出。训练由识别的表格结构质量引导。如果生成的结构允许LLM正确回答问题,VLM获得高奖励。如果答案匹配预期结果,它获得高奖励。如果输出无效,模型破坏了表格结构,它会在造成训练不稳定之前被过滤掉。
总而言之,TRivia形成了一个从无标签表格→可验证QA构建→QA奖励GRPO(带稳定化)的循环,从未标记数据中提取监督,以突破纯监督微调的限制。
4、TRivia-3B如何训练:从语法到无监督学习
最终模型称为TRivia-3B。它使用Qwen2.5-VL-3B作为骨干VLM,经历三个训练阶段。这些阶段从大规模标记开源数据(混合真实+合成)→标记真实世界监督微调→无标记网页PDF表格用于TRivia/GRPO。
阶段1:OTSL标签热身
TRivia不使用HTML或Markdown,而是从OTSL开始,这是一种更紧凑的表格表示。它通过邻接性编码结构,避免了明确预测colspan或rowspan等复杂元素的需要。这保持了低token数量并简化了结构预测。
数据:通过组合和清理来自PubTabNet(200K)、MMTab(100K)和SynthTabNet的四个子集(各100K)的数据,策划了约700,000个样本。所有标签都被转换为OTSL格式。
训练:在这个阶段只微调了Qwen2.5-VL-3B的语言模型部分。视觉编码器和对齐模块保持冻结,以保留低级视觉表示。
阶段2:监督微调
这个阶段转向真实世界数据。使用了约50,000个真实表格图像来微调所有模型参数。这里的目标是弥合合成和真实布局之间的差距,并完全推到监督学习单独能达到的极限。
阶段3:TRivia(自监督GRPO训练)
最后阶段是事情变得有趣的地方。
首先,从网页PDF收集了约100,000个无标记表格图像。使用DocLayout-YOLO裁剪表格。然后,响应一致性采样过滤掉一致性非常低(<0.4)的噪声情况,然后在0.4-1.0一致性区间(步长0.1)内均匀采样,进行PDF级去重,得到约50K图像用于RL训练。
对于每个图像,系统使用Qwen2.5-VL-72B-Instruct通过注意力引导过程生成并过滤大约30个QA对。然后使用GRPO(一种使用基于QA的F1作为奖励的强化学习方法,对QA集取平均)通过这些QA任务微调模型。
在这个阶段,负责回答问题的模型(用于奖励估计的大语言模型)是Qwen3-8B。
5、评估
TRivia-3B在四个公共基准上进行评估:PubTabNet、OmniDocBench v1.5(512个样本)、CC-OCR(300个样本)和OCRBench v2的表格解析子集(700个图像)。性能使用两个指标测量:TEDS(总体表格准确性)和S-TEDS(仅结构准确性)。
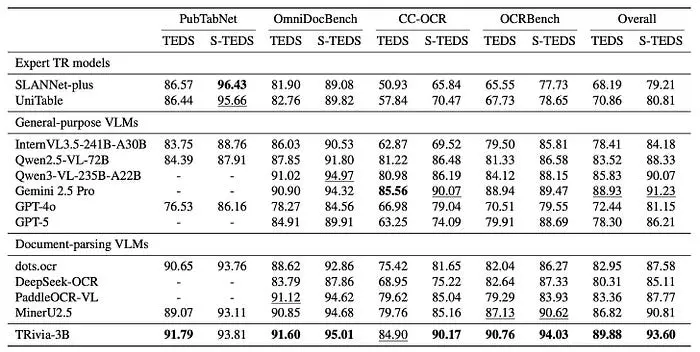
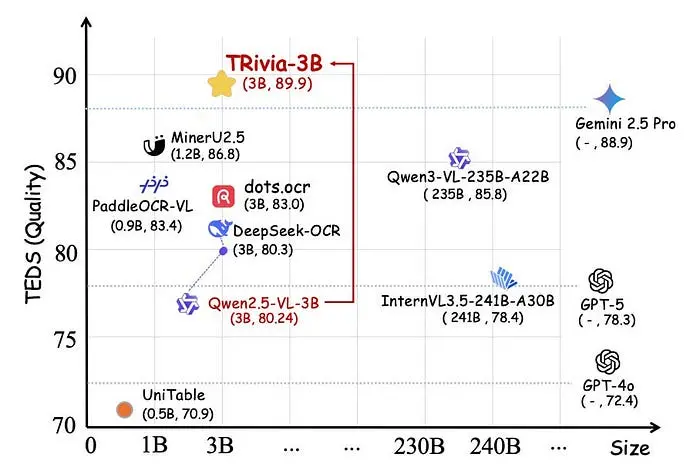
如图4所示,TRivia-3B获得了以下分数:
- PubTabNet:91.79 TEDS / 93.81 S-TEDS
- OmniDocBench:91.60 / 95.01
- CC-OCR:84.90 / 90.17
- OCRBench:90.76 / 94.03
- 总体平均:89.88 / 93.60
在四个数据集上,TRivia-3B通常强于12个基线,在大多数指标上领先(尽管专家模型在PubTabNet S-TEDS上由于数据集特异性仍然保持优势)。这些包括专家表格识别系统、通用视觉语言模型和专门为文档解析调优的模型。
与Gemini 2.5 Pro(总体88.93 TEDS / 91.23 S-TEDS,不包括未评估的PubTabNet)相比,TRivia-3B在大多数基准上表现更好。唯一的例外是CC-OCR,Gemini略高于TRivia-3B(85.56 TEDS vs 84.90)。
6、思考
TRivia最突出的一点是它将未标记表格转化为可用训练信号的能力。它不依赖复杂的标注方案。
相反,它构建了一个完整的反馈循环:使用响应一致性选择最有信息量的样本,通过注意力引导生成多样化且有根据的QA对,然后通过GRPO微调模型,使用平均QA F1分数作为奖励。为了保持学习稳定,无效输出在影响训练之前就被过滤掉。
但我有一个担忧。 它在于代理奖励偏差。由于奖励基于问题是否被正确回答,模型的学习很大程度上取决于问题的分布和它们覆盖表格的哪些部分。关键的结构错误,比如不正确的行或列合并,如果它们不直接影响QA性能,可能会被遗漏。TRivia通过注意力引导QA生成来确保覆盖率以缓解这个问题。
另一个需要考虑的点:由于阶段3使用从网页PDF裁剪的真实表格,在企业设置中应用此流程最好从目标领域内的文档重新采样。否则,来自网页表格的布局先验会悄悄影响模型,引入在部署期间难以检测的领域偏差。
原文链接: TRivia: Teach a 3B Model to Parse Tables
汇智网翻译整理,转载请标明出处
