TurboOCR:优化杰作
设置并不容易。但当这个工具是对的工具时,它会以 10 倍的优势碾压竞争对手

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
TurboOCR 是 aiptimizer 团队的 C++20/CUDA/TensorRT 服务器,封装了与 PaddleOCR 相同的 PP-OCRv5 模型,声称在 FUNSD 表单上达到每秒 268 张图片。我们在 OmniDocBench 设置上运行它,测量到在基准测试的前 500 页英文页面上达到每秒 28 页。
比我们测试过的最快 VLM LightOnOCR 快五十三倍。在原始吞吐量上完胜。
关键问题是:达到每秒 28 页大约需要在全新机器上设置 90 分钟。它还在表格结构上得分为零。让我们来分析为什么、如何以及何时它才是真正正确的工具。
1、TurboOCR 到底是什么
它不是库。不是 Python 包。它是一个生产级 OCR 服务器,你作为 Docker 容器部署,通过 HTTP 或 gRPC 调用。底层,它封装了标准的 PaddleOCR 模型三件套:PP-OCRv5 检测、PP-OCRv5 识别(拉丁语 + 希腊语,836 个字符)、PP-DocLayoutV3 布局检测。与 pip install paddleocr 使用的模型相同。模型层没有任何新东西。
新的是模型层下面的所有东西。
1.1 推理栈重写
基线 PaddleOCR Python 通过 PaddlePaddle 的 Python 绑定运行推理,调用 PaddlePaddle 的 C++ 后端,分派到 cuDNN,最终运行 CUDA 内核。每一跳都是开销。TurboOCR 丢弃了整个管道并重建了它。
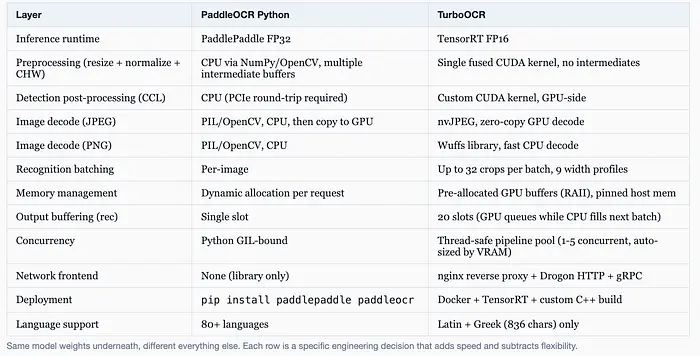
重写规模不小:
- ONNX 模型在首次启动时转换为 TensorRT FP16 引擎,按 GPU 架构缓存。这些引擎在纸上比 cuDNN 快约 30-50%。专门为你的 GPU 的 SM 版本编译(Ada Lovelace 为 SM89,Ampere 为 SM86)。不能跨 GPU 移植。
- 自定义 CUDA 预处理内核。代替标准的"CPU 调整图像大小、CPU 归一化、CPU 转置为 CHW、复制到 GPU"模式,TurboOCR 有一个单一融合内核
cuda_fused_resize_normalize_det,在 GPU 上一次完成所有三个操作。没有中间缓冲区。没有 PCIe 往返。 - GPU 端连通分量标记。PaddleOCR 的检测后处理通过 CCL 找到文本区域,这是一个传统上在 CPU 上运行的经典计算机视觉算法。TurboOCR 有一个自定义 CUDA 内核。又一个 PCIe 往返被消除。
- 多配置动态形状。识别模型内置 9 个不同宽度配置:320、480、800、1200、1600、2000、2500、3200、4000 像素。TRT 为每个配置编译最优内核。当裁剪输入时,自动选择正确的配置。没有冷内核。
- 预分配 GPU 缓冲区,固定主机内存。每个请求重用相同的内存。热路径上没有
cudaMalloc。固定主机内存启用从 GPU 到 CPU 的零拷贝 DMA。 - 20 槽识别输出缓冲区。GPU 可以在 CPU 仍在准备第 21 批时排队 20 批完成的输出。计算和 DMA 重叠,GPU 永远不会停顿。
- 管道池。由 VRAM 自动调整大小。在 16 GB GPU 上,你获得 5 个并发管道(每个 1.4 GB)。请求通过线程安全的 RAII 作用域句柄分派到各管道。基本上无锁。
- nvJPEG 用于 JPEG 解码,Wuffs 用于 PNG 解码。两者都是零拷贝。JPEG 字节通过网络缓冲区直接进入 GPU 内存,无需任何中间 PIL 或 OpenCV 步骤。
- nginx 反向代理在 Drogon HTTP 服务器前面,强制连接保持并吸收连接风暴...
再读一遍那个列表。这是"当有人真正关心延迟时,生产 GPU 推理是什么样子"的教科书范例。大多数推理服务器最多做到其中一半。TurboOCR 全部做到了。
1.2 为什么每一项都很重要
现在。让我们分析对吞吐量数学影响最大的几项。
TensorRT FP16 引擎是最大的赢家。
PaddleOCR Python 通过 cuDNN 在 FP32 下运行。切换到 FP16 将内存带宽需求减半,这实际上是小型视觉模型的瓶颈。cuDNN 是通用卷积库;TensorRT 在你的精确 GPU 上对每一层的每个候选内核进行性能分析,并选择最快的一个。在检测模型上的差异通常是 3-5 倍延迟降低。
在具有九个配置的识别模型上,接近 8 倍,因为 TRT 可以将识别头激活融合到 transformer 编码器的输出矩阵乘法中。
GPU 端 CCL 比你想象的更重要。
PaddleOCR 的检测产生每个像素的概率热图。经典后处理对其进行阈值化,运行连通分量标记以找到文本区域,然后按大小和形状过滤。在 CPU 上,960x960 热图 CCL 大约需要 15 毫秒。
这是每个请求每次推理和下一次之间的 15 毫秒延迟。在每秒 28 页的速度下,仅 CCL 就会是 420 毫秒/秒的瓶颈,使吞吐量减半。TurboOCR 的自定义内核在 GPU 上不到 1 毫秒完成。低于阈值。瓶颈转移到别处。
预分配缓冲区和多槽输出是第二重要的。
每个 cudaMalloc 都是 GPU 内存分配器上的锁。在并发下,分配器争用。TurboOCR 在启动时预分配所有内容,并通过 RAII 作用域句柄重用。
识别的 20 槽输出缓冲区是酷的部分:GPU 可以排队 20 批完成的输出数据,而 CPU 仍在准备第 21 到 40 批。你的 CPU 而不是 GPU 成为瓶颈,这正是你在 4090 上想要的。
nvJPEG + Wuffs 图像解码器是较小的改进,但在每秒 28 页时很重要。
标准管道在 CPU 上进行 JPEG 解码(OpenCV 调用 libjpeg-turbo),然后 cudaMemcpy 将解码像素传输到 GPU。nvJPEG 直接在 GPU 硬件上解码 JPEG,解码后的字节永远不会离开 GPU 内存。
在 3 MB JPEG 以每秒 28 页的速度下,大约节省了 84 MB/秒的 PCIe 流量,加上 CPU 周期。
重要的不是任何一个优化的大小。而是堆叠。
1.3 我的测试中的实测结果
在我们的 OmniDocBench 样本上(500 页英文页面,16 个并发 HTTP 请求,RTX 4090 笔记本):
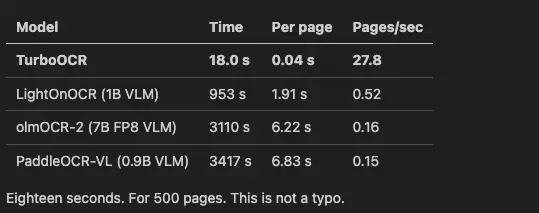
十八秒。500 页。这不是打字错误。
2、README 中没有提到的设置
但是等等。在你获得每秒 28 页之前,你要付出代价。我们将介绍 README 没有提到的内容,因为这是你决定是否采用时最关键的部分。
步骤 1:Docker 镜像是私有的
README 引导你一行命令:docker pull ghcr.io/aiptimizer/turboocr:v2.0.0 然后用 GPU 标志运行。该注册表有身份验证。匿名拉取返回 unauthorized。你必须注册获取访问权限或从源代码构建。我们从源代码构建了。
步骤 2:C++ 编译
docker build -f docker/Dockerfile.gpu -t turbo-ocr . 拉取 NVIDIA TensorRT 基础镜像(约 15 GB),安装约 40 个 apt 包,从源代码克隆并编译 Drogon 1.9.12,获取 CMake 3.31.6,获取 ONNX Runtime 1.22.0,然后对 TurboOCR C++/CUDA 源代码运行 cmake && make -j$(nproc)。
我们的首次构建失败了。apt-get 在 TensorRT 26.03 基础镜像中遇到了过期的包索引,以退出码 100 死掉了。重试成功。第二次构建:在 16 核机器上约 25 分钟,主要在链接期间受 CPU 限制。
最终镜像:12.2 GB。
步骤 3:TRT 引擎编译
你闪亮的新 Docker 容器启动了。好的。现在 TensorRT 必须将 ONNX 模型编译为 GPU 架构特定的引擎。README 说"大约 90 秒"。在笔记本 4090 上是:
- det.onnx → det.trt:约 5 分钟
- rec.onnx → rec.trt:约 20 分钟(九个宽度配置,每个需要自己的内核选择过程)
- cls.onnx → cls.trt:约 1 分钟
大约 25 分钟。然后管道预热(约 1 分钟)。现在你准备好了。
除了你还没准备好。
步骤 4:布局模型不在那里
健康端点返回 ok。你用 ?layout=1 发送第一个请求以获取文档区域。你得到:
{"error":{"message":"Layout requested but server was not started with ENABLE_LAYOUT=1"}}
嗯。README 说布局默认启用。
为什么它在要求一个环境变量?你深入挖掘。你意识到:布局 ONNX 模型没有打包在 Docker 镜像中。Dockerfile 构建了二进制文件但没有人把 models/layout/layout.onnx 放进 /app/models/layout/。错误消息在谎报问题所在。
好的。仓库有 scripts/export_pp_doclayoutv3.py。
运行它。它需要 paddlepaddle + paddlex + paddle2onnx + onnxsim + onnx。安装这些。运行脚本。它从 Paddle 的模型中心下载 PP-DocLayoutV3 权重(约 200 MB),然后:
Step 2: paddle2onnx export
paddle2onnx failed and no console script fallback found
脚本尝试 python -m paddle2onnx,这在 paddle2onnx 2.1 中不存在。你必须绕过脚本直接调用 CLI。然后运行 onnxsim 简化图(2818 → 1321 节点)。现在你有一个 124 MB 的 layout.onnx 放在你的主机上。
复制到运行中的容器:
docker exec turboocr mkdir -p /app/models/layout
docker cp /tmp/layout.onnx turboocr:/app/models/layout/layout.onnx
docker restart turboocr
步骤 5:布局 TRT 编译
容器重启。布局 ONNX 现在存在了。TensorRT 必须编译它。布局模型 124 MB,大约是 OCR 模型的 25 倍。它有从批次 1 到 8 的多配置。
在我们的 GPU 上十五分钟。
你坐在那里看 nvtop 显示 75% GPU 利用率的锯齿模式几秒钟,然后降到零,重复。这是 TRT 在每个批次大小配置中为每一层分析每个候选内核。数百个微基准测试。每个峰值是一次内核对决。每个谷值是优化器决定哪个赢了。看一次很有趣;等它完成很乏味。
总设置时间:90 分钟
加起来。Docker 构建 25 分钟。首次 TRT 引擎 25 分钟。布局 ONNX 导出 + 注入 10 分钟。布局 TRT 编译 15 分钟。人工调试未记录的空白 15 分钟。算作从动手到运行第一个真实请求需要 90 分钟的挂钟和键盘时间。
作为对比,我们早期比较中最快的 VLM 替代方案是 LightOnOCR:docker compose up -d lightonocr 使用现有的 compose 文件,约 60 秒拉取 vLLM 基础镜像(已缓存),45 秒 vLLM 加载 1B 模型,准备就绪。总时间:大约 2 分钟。
九十分钟对比两分钟。这就是 53 倍速度优势的设置时间成本。
3、TurboOCR 的优势
公平地说。性能不是噱头。工程确实是世界级的。以下是你用设置痛苦换来的东西:
极致吞吐量
在真实文档图像上测量到每秒 28 页。他们发布的基准测试在稀疏图像(单行文本)上达到每秒 1,200+ 页。你不会遇到 vLLM 式的每请求延迟悬崖。最坏情况的延迟仍然很快。
90% 字符准确率的拉丁语 OCR
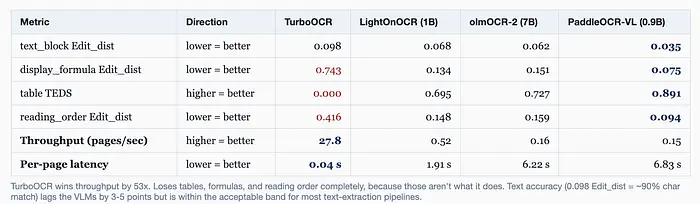
在 OmniDocBench 的英文文本上,编辑距离为 0.098。翻译一下:TurboOCR 正确复现页面上大约 90% 的字符。这低于 VLM(LightOnOCR 93%,PaddleOCR-VL 96%),但在大多数文本提取用例的可接受范围内。
布局检测
PP-DocLayoutV3 将区域标记为 doc_title、paragraph_title、text、table、formula、abstract、figure_title、header、footer 等 16 个其他类别。每个 OCR 结果通过 layout_id 标记它所属的布局区域。你可以使用分类跳过页眉和页脚,或按区域类型分割下游管道。
内置 PDF 支持
/ocr/pdf 接受 PDF 并通过 pdftoppm 并行渲染页面(16 个守护进程,4 个工作线程,通过 /dev/shm)。四种模式:完全 OCR、仅文本层(对原生数字 PDF 快 10 倍)、自动(启发式)、自动验证(OCR 加文本层健全检查)。
Prometheus 指标
/metrics 端点提供请求计数器、延迟直方图、VRAM 使用量。结构化 JSON 日志。放在你的负载均衡器后面,可观测性开箱即用。这是生产级代码。
gRPC 支持
除了端口 8000 上的 HTTP,还有端口 50051 上的 gRPC 服务器共享相同的管道池。如果你的消费者已经是 Go 或 Rust 服务网格,你可以完全跳过 HTTP 开销。.proto 文件在仓库中,所以任何语言的代码生成都是十分钟的事。
4、TurboOCR 的不足
然后是它做不到的事情。这些不是 bug。它们是设计选择。但它们很重要。
没有表格结构(这很重要)
PDF 中的表格是一组行、列和合并单元格。TurboOCR 看到每个单元格内的文本,并将整个区域标记为 layout_id=3, class=table。但它给你的是扁平字符串。没有 <tr>,没有 <td>,没有行边界。
如果你想要 HTML 表格输出,你需要自己从边界框构建:按 y 坐标聚类得到行,在每行内按 x 排序得到列,生成标记。经典的从边界框重建表格。对简单有边框的表格有效,对有合并单元格、跨列表头或无边框格式的表格会失败。
我们在 OmniDocBench 上的测量:TEDS 分数 0.000。因为我们没有构建表格重建器。同一基准测试中的 VLM 得分 0.695 到 0.891。
公式没有 LaTeX
TurboOCR 是字符级 OCR 引擎。它看到 ∫f(x)dx 作为字形序列并按字面转录。VLM 看到同样的东西并输出 \int f(x) \, dx,因为它被训练输出 LaTeX。我们的公式编辑距离:0.743(差)。LightOnOCR:0.134(好)。
如果你的下游用途是渲染数学,你需要 VLM,不是 OCR 引擎。
阅读顺序仅限空间排序
PP-DocLayoutV3 给你布局区域,但输出中区域的顺序基本上是"检测器先找到什么"。没有逻辑说"对于双栏论文,在开始右栏之前先读完整个左栏。"你需要自己构建。我们的阅读顺序编辑距离是 0.416,意味着大约 40% 的块在多栏页面上最终处于错误位置。VLM 做好了 3-5 倍,因为它们在文档结构上训练,而不仅仅是视觉文本。
仅拉丁语 + 希腊语
836 个字符。英语、德语、法语、意大利语、波兰语、捷克语等。没有中文。没有日文。没有韩文。没有阿拉伯文。如果你需要这些,就到这里为止了。底层 PP-OCRv5 有多语言变体,但 TurboOCR 只发布拉丁语版本。
没有 Python API
你不能 from turbo_ocr import TurboOCR。它不存在。唯一的接口是 HTTP 服务器(或 gRPC)。你总是部署一个容器,总是通过网络与它通信。如果你想内联集成到 Python 管道中,你做不到。你通过 requests.post() 集成。
5、值得吗?
说实话,对你们中的大多数人来说,说不准。以下是盈亏平衡数学。
VLM 替代方案
如果你今天通过 OCR 管道处理文档,你可能关心两件事:吞吐量和准确性。假设你有一百万页要处理。运行它们:(来自我的实验)
- TurboOCR 以 28 页/秒 = 10 小时。设置:90 分钟。
- LightOnOCR 以 0.52 页/秒 = 22 天。设置:2 分钟。
- PaddleOCR-VL 以 0.15 页/秒 = 77 天。设置:10 分钟。
在一百万页上,TurboOCR 的设置成本摊薄到可以忽略不计,吞吐量优势巨大。有意义。
现在把规模降到 10,000 页:
- TurboOCR:6 分钟推理。设置:90 分钟。总计:96 分钟。
- LightOnOCR:5.3 小时推理。设置:2 分钟。总计:5.3 小时。
仍然是 TurboOCR 赢,但优势不那么显著了。而且你得到更差的准确性和没有表格。
在 1,000 页时:
- TurboOCR:36 秒推理。设置:90 分钟。总计:91 分钟。
- LightOnOCR:32 分钟。设置:2 分钟。总计:34 分钟。
LightOnOCR 赢。TurboOCR 的设置税在小批量上杀死了速度优势。
交叉点大约在 100,000 页。低于此,TurboOCR 的设置时间吞噬了速度优势。高于此,它开始回本。
何时 TurboOCR 是正确的工具
- 处理数百万页拉丁文字文本用于训练语料库、搜索索引或合规存档
- 你更关心吞吐量而非结构(表格、公式、阅读顺序是锦上添花)
- 你已经有NVIDIA GPU,带 CUDA 12.x,且熟悉 TensorRT
- 你将其部署为长期运行的服务,而不是一次性批处理
- 你的安全/运维团队接受 C++ 二进制 + Docker 容器在数据流中
- 你的内容是拉丁语或希腊语
如果所有这些都成立,TurboOCR 就是正确的工具,它会在几周内回本。
何时 TurboOCR 是错误的工具
- 你的工作负载从未超过 10 万页
- 你需要表格、公式或保留阅读顺序
- 你有中文、日文、韩文或任何非拉丁文字
- 你想要
pip install就完事 - 你没有专用 GPU 服务器或相应预算
- 你团队中没有 C++ 或 TensorRT 专业知识(总会有东西出问题,到时候你需要它)
- 你处于研究/笔记本工作流中,每 2 分钟的设置比 10 小时的推理更重要
十次中有九次,看到 TurboOCR README 的从业者会属于第二组。
50 倍的加速是真实的,但对他们的实际问题来说这是错误的指标。
有一个中间地带值得命名
我们还没测试过的 Python 原生一级选项:RapidOCR(PaddleOCR 模型的 ONNX Runtime 封装,约 15 页/秒,pip install)、Tesseract(2-5 页/秒,apt install)、Surya(5-10 页/秒,pip install)。
这些给你比 PaddleOCR Python 5 倍到 30 倍的加速,零 Docker、零 TensorRT、零 C++ 编译。对于大多数非 VLM 用例,其中一个可能是你真正的答案,不是 TurboOCR。
6、你用 TurboOCR 真正得到的是什么
剥离营销和基准图表。采用 TurboOCR 时你实际上买到的是什么?
你买到两样东西:
原始吞吐量和零 Python
吞吐量就是图表显示的。零 Python 不那么明显但几乎同样重要。Python 的 GIL 将单进程并发限制在 CPU 密集型工作的核心数量左右;对于 GPU 密集型推理服务器稍好但仍有限。TurboOCR 的线程池是无锁 C++,使用固定内存,无头运行。你的 Python GIL 限制的消费者而不是服务器成为瓶颈。这在规模上是真正的架构优势。
你不是在买准确性、可移植性、灵活性、语言覆盖、文档理解或开发者人体工程学。
这些是代价。TurboOCR 是一项承诺。知道你为什么选择它。
7、给实践者的结论
TurboOCR 是系统工程的杰作。优化工作是合法的,代码质量很高,性能声明是真实的。团队显然知道他们在做什么。
然而,对于绝大多数会安装它的人来说,它不是正确的工具。不是因为它不好。而是因为它很专业。它是一个高吞吐量的拉丁文本提取服务器,在那一件事情上异常出色。它不是文档解析器,不是多语言 OCR,不是笔记本友好的库。它是一个生产级部署,以数小时的设置为代价,并受设计限制。
如果你今晚要在一百万页的摄取管道上运行,停止阅读这篇文章,现在就部署它。如果你不是,部署 LightOnOCR 获取结构化输出,或 RapidOCR 获取快速原始文本,然后继续你的生活。如果你永远达不到盈亏平衡点,50 倍的加速毫无意义。
这是我的观点。你应该做你觉得舒适的事情。但不要因为基准图表漂亮而选择 TurboOCR。选择它是因为你的工作负载确实需要它做的事情,并且你能绕过它的限制。
原文链接: TurboOCR: A Masterpiece In Optimization OCRs 28 pages per second
汇智网翻译整理,转载请标明出处
