为什么我们需要持续学习
上下文学习(ICL)对于答案或答案片段已经存在于某处的问题是足够的。但对于需要真正发现的问题(如新数学)、对抗性场景(如安全),或者知识过于隐晦而无法用语言表达的情况,有一个强有力的论点是,模型需要一种在部署后将知识和经验直接更新到参数中的方法。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
在克里斯托弗·诺兰的电影《记忆碎片》中,莱纳德·谢尔比生活在一个破碎的当下。在一次创伤性脑损伤后,他患上了前向性失忆症,这种疾病使他无法形成新的记忆。每隔几分钟,他的世界就会重置,让他滞留在一个永恒的现在中,与刚发生的事情脱节,对未来充满不确定。为了应对,他靠在身上纹笔记和拍宝丽来照片来生存——这些基本上是外部道具,用来提醒他的大脑无法保留的东西。
大型语言模型也生活在类似的永恒现在中。它们从训练中涌现,将大量知识冻结在参数中,但它们无法形成新的记忆——无法根据新的经验更新参数。为了弥补,我们用脚手架包围它们:聊天历史作为短期便签,检索系统作为外部笔记本,系统提示作为引导性的纹身。模型本身从未真正内化新信息。
一些研究人员越来越认为这还不够。上下文学习(ICL)对于答案或答案片段已经存在于某处的问题是足够的。但对于需要真正发现的问题(如新数学)、对抗性场景(如安全),或者知识过于隐晦而无法用语言表达的情况,有一个强有力的论点是,模型需要一种在部署后将知识和经验直接更新到参数中的方法。
ICL 是短暂的。真正的学习需要压缩。除非我们让模型持续压缩,否则我们可能被困在《记忆碎片》的永恒现在中。反过来,如果我们能训练模型学习自己的记忆架构——而不是将其卸载给定制的框架——我们可能会解锁一个全新的扩展维度。
这个研究领域的名字叫做持续学习。虽然这个想法并不新鲜(参见:McCloskey 和 Cohen,1989年!),但我们认为这是目前 AI 领域最重要的工作之一。在过去2-3年中模型能力的惊人增长下,模型所知和它们可能所知之间的差距变得越来越明显。因此,我们这篇文章的目标是分享我们从该领域顶级研究人员那里学到的内容;帮助厘清持续学习的不同方法;并在创业生态系统中推进这个话题。
注:本文得益于与一群杰出研究员、博士生和创业创始人的对话,他们公开分享了他们在持续学习方面的工作和观点。他们的洞察——从理论基础到部署后学习的工程现实——使这篇文章比我们自己能写的更加锐利和扎实。感谢你们慷慨地分享时间和想法!
1、首先,谈谈上下文
在为参数化学习——即更新模型权重的学习——辩护之前,重要的是承认上下文学习确实有效。而且有一个令人信服的论点是它会继续获胜。
Transformer 从根本上说是序列上的条件下一个 token 预测器。给它们正确的序列,你会得到惊人丰富的行为,而无需触碰权重。这就是为什么上下文管理、提示工程、指令微调和少样本示例如此强大。智能存在于静态参数中,而表面能力根据你输入窗口的内容发生根本性变化。
Cursor 最近深入研究了扩展自主编码智能体的例子很好地说明了这一点:"系统行为的惊人大量取决于我们如何提示智能体。框架和模型很重要,但提示更重要。" 模型权重是固定的。让系统工作的是对上下文的精心编排:包含什么、何时总结、如何在数小时的自主操作中维持一致的状态。
OpenClaw 是另一个很好的例子。它之所以脱颖而出,不是因为特殊的模型访问权限(底层模型对所有人都可用),而是因为它非常有效地将上下文和工具转化为工作状态:跟踪你在做什么、构建中间产物、决定什么重新注入提示、维护先前工作的持久记忆。OpenClaw 将智能体框架设计提升为一门独立的学科。
当提示首次出现时,许多研究人员怀疑"仅仅提示"能否成为严肃的接口。它看起来像一个 hack。然而它是 Transformer 架构原生的,不需要重新训练,并随着模型改进自动扩展。所以随着模型变得更好,提示也变得更好。"粗糙但原生"的接口通常会赢,因为它们直接耦合到底层系统而不是与之对抗。到目前为止,LLM 正是这种情况。
2、状态空间模型:上下文的增强版
随着主导工作流从原始 LLM 调用转向智能体循环,上下文学习模型上的压力越来越大。以前完全填满上下文的情况相对罕见。这通常发生在 LLM 被要求做一长串离散工作时,应用层可以以直接的方式修剪和/或压缩聊天历史。但有了智能体,一个任务就可能消耗总可用上下文的很大一部分。智能体循环中的每一步都依赖于前一次迭代传递的上下文。它们通常在20-100步后失败,因为它们丢失了线索:上下文填满了,连贯性下降,它们停止收敛。
因此,主要 AI 实验室现在正在投入大量资源(即大型训练运行)来开发具有非常大上下文窗口的模型。这是一种自然的方法,因为它建立在正在起作用的东西(上下文学习)之上,并清晰地映射到行业向推理时计算的更广泛转变。最常见的架构是将固定记忆层与正常注意力头交替穿插,即状态空间模型和线性注意力变体(为简单起见,我们将所有这些称为 SSM)。SSM 为长上下文提供了比传统注意力根本更好的扩展特性。
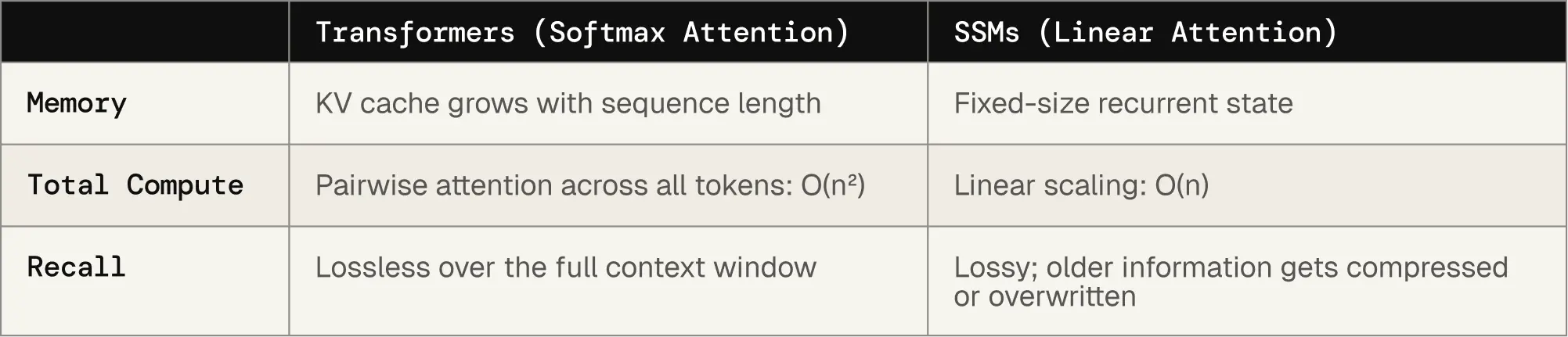
目标是帮助智能体将连贯性维持几个数量级更长的循环,从大约~20步到~20,000步,而不失去传统 Transformer 提供的技能和知识的广度。如果成功,这将是长时间运行智能体的重大胜利。你甚至可以考虑这种方法是持续学习的一种形式:虽然你没有更新模型权重,但你引入了一个很少需要重置的外部记忆层。
所以,这些非参数化方法是真实且强大的。对持续学习的任何评估都必须从这里开始。问题不在于当今基于上下文的系统是否有效——它们确实有效。问题在于我们是否正在看到天花板,以及新方法是否能带我们走得更远。
3、上下文遗漏了什么:文件柜谬误
"AGI 和预训练发生的事情是,在某种意义上它们超出了目标……人类不是 AGI。是的,确实有一个技能基础,但人类缺乏大量知识。相反,我们依赖持续学习。如果我产生一个超级聪明的15岁孩子,他们其实不知道多少东西。一个很好的学生,非常渴望。你可以说,'去当程序员。去当医生。'部署本身将涉及某种学习、试错期。这是一个过程,而不是投放成品。"— Ilya Sutskever
想象一个拥有无限存储的系统。世界上最大的文件柜,每个事实都完美索引,即时可检索。它可以查找任何东西。它学习了吗?
没有。它从未被迫进行压缩。
这是我们论点的核心,它借鉴了 Ilya Sutskever 之前提出的一个观点:LLM 从根本上是压缩算法。在训练期间,它们将互联网压缩成参数。压缩是有损的,而这正是它强大的原因。压缩迫使模型找到结构、进行泛化、构建跨上下文迁移的表示。记住每个训练示例的模型比提取底层模式的模型更差。有损压缩就是学习。
讽刺的是,使 LLM 在训练期间如此强大的机制(例如将原始数据压缩成紧凑、可迁移的表示)正是我们在部署后拒绝让它们做的事情。我们在发布的时刻停止压缩,代之以外部记忆。当然,大多数智能体框架以某种定制方式压缩上下文。但苦涩的教训难道不是暗示模型本身应该学会直接且大规模地进行这种压缩吗?
余越分享的一个用来说明争论的例子是数学。考虑费马大定理。350多年来,没有数学家能证明它——不是因为他们缺乏正确文献的访问权限,而是因为解决方案高度新颖。既定数学与最终答案之间的概念距离实在太大了。当安德鲁·怀尔斯最终在1990年代破解它时,经过近七年的近乎完全独立工作,他必须发明强大的新技术来达成解决方案。他的证明依赖于成功桥接两个不同的数学分支:椭圆曲线和模形式。虽然 Ken Ribet 的早期工作表明证明这种连接会自动解决费马大定理,但直到怀尔斯,才有人拥有实际构建那座桥梁的理论工具。对格里戈里·佩雷尔曼证明庞加莱猜想也可以提出类似的论点。
核心问题是: 这些例子是否证明了 LLM 中缺少了某些东西——某种更新其先验知识并以真正创造性方式思考的能力?还是说这个故事证明了相反的观点——所有人类知识只是可用于训练/重组的数据,而怀尔斯和佩雷尔曼只是展示了 LLM 在更大规模上能做什么?
这个问题是经验性的,答案尚不清楚。但我们确实知道有许多类别的问题,今天上下文学习会失败,而参数化学习可能产生影响。例如:

更重要的是,上下文学习仅限于可以用语言表达的内容,而权重可以编码某人提示无法以文字传达的概念。有些模式维度太高、太隐晦、结构太深,无法装入上下文。例如,区分良性伪影和肿瘤的医学扫描中的视觉纹理,或定义说话者独特韵律的音频微波动,这些模式不容易分解为精确的词语。语言只能近似它们。无论提示多长,都无法传递这些;这种知识只能存在于权重中。它们存在于学习表示的潜在空间中,而不是词语中。无论上下文窗口增长多长,都会有一些无法用文字描述、只能保存在参数中的知识。
这可能有助于解释为什么明确的"机器人记得你"功能(如 ChatGPT 的记忆)经常引发用户的不适而非欣喜。用户其实不想要回忆本身。他们想要能力。一个内化了你模式的模型可以泛化到新情况;一个仅仅回忆你历史的模型不能。"这是你之前回复这封邮件的方式"(逐字)与"我足够了解你的思维方式,可以预测你需要什么"之间的区别,就是检索与学习之间的区别。
3、持续学习入门
持续学习有各种方法。分界线不是"有记忆功能"与"无记忆功能"。而是:压缩在哪里发生? 方法沿一个光谱聚集,从无压缩(纯检索,权重冻结),到完全内部压缩(权重级学习,模型变得更聪明),以及一个重要的中间地带(模块)。
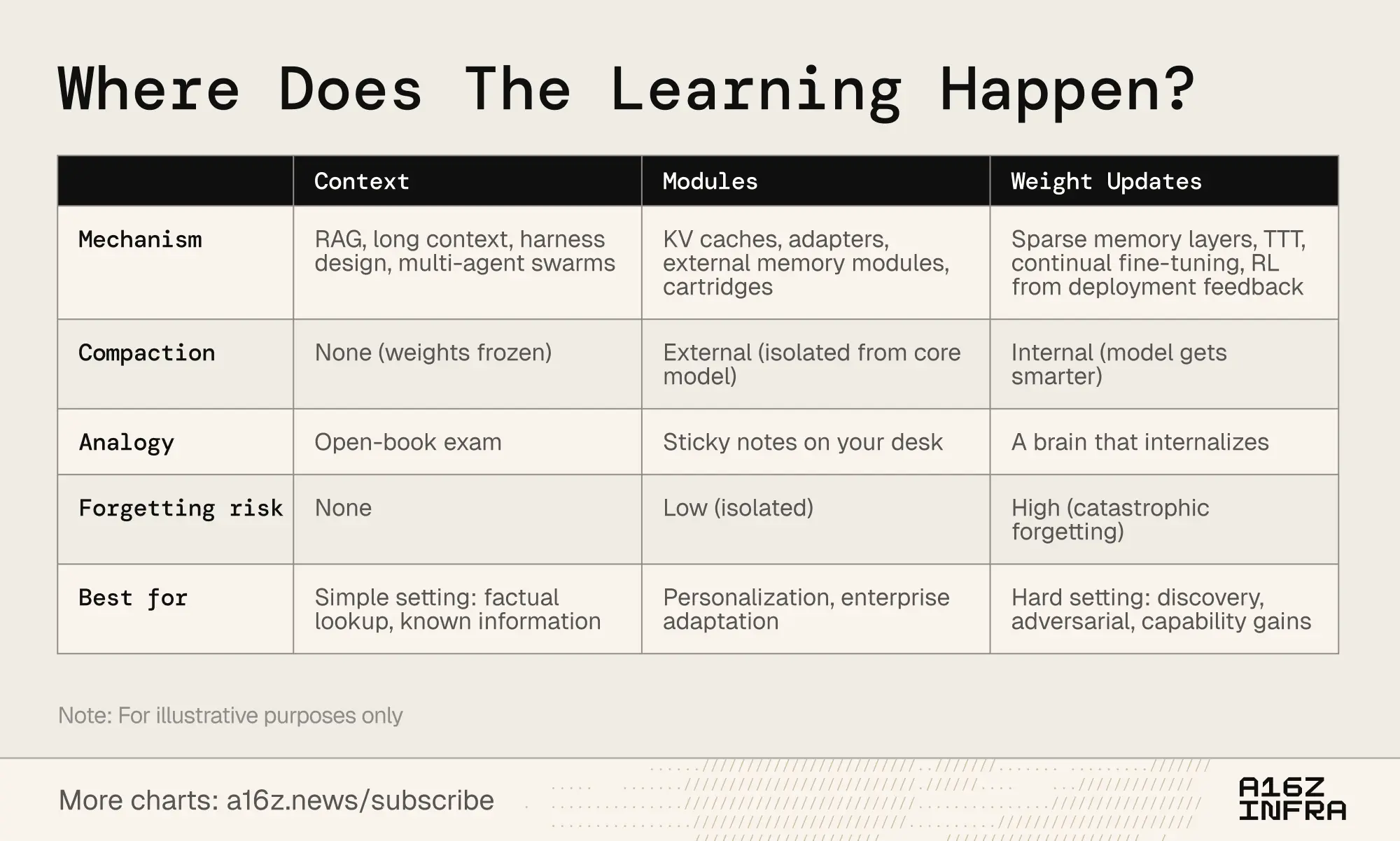
3.1 上下文
在上下文端,团队构建更智能的检索管道、智能体框架和提示编排。这是最成熟的类别:基础设施已经过验证,部署方案干净。限制是深度:上下文长度。
这里值得注意的一个新兴扩展是:多智能体架构作为上下文本身的扩展策略。如果单个模型受限于128K token窗口,一组协调的智能体群——每个持有自己的上下文、专门处理问题的一个切片并交流结果——可以集体近似无限工作记忆。每个智能体在其窗口内进行上下文学习;系统进行聚合。Karpathy 最近的 autoresearch 项目 + Cursor 构建 Web 浏览器的例子是早期案例。这是一种纯粹的非参数方法(没有权重变化),但它显著扩展了基于上下文系统能做的事情的上限。
3.2 模块
在模块领域,团队构建可附加的知识模块(压缩的 KV 缓存、适配器层、外部记忆存储),专门化通用模型而无需重新训练。一个带有正确模块的8B模型可以在目标任务上匹配109B的性能,只需使用一小部分内存。吸引力在于它与现有的 Transformer 基础设施兼容。
3.3 权重
在权重更新方面,研究人员正在追求真正的参数化学习,例如只更新相关参数片段的稀疏记忆层、从反馈中优化模型的强化学习循环,以及在推理期间将上下文压缩到权重中的测试时训练。这些是最深入的方法,也是最难部署的,但它们确实允许模型完全内化新信息或技能。
参数化更新有多种机制。列举几个研究方向:
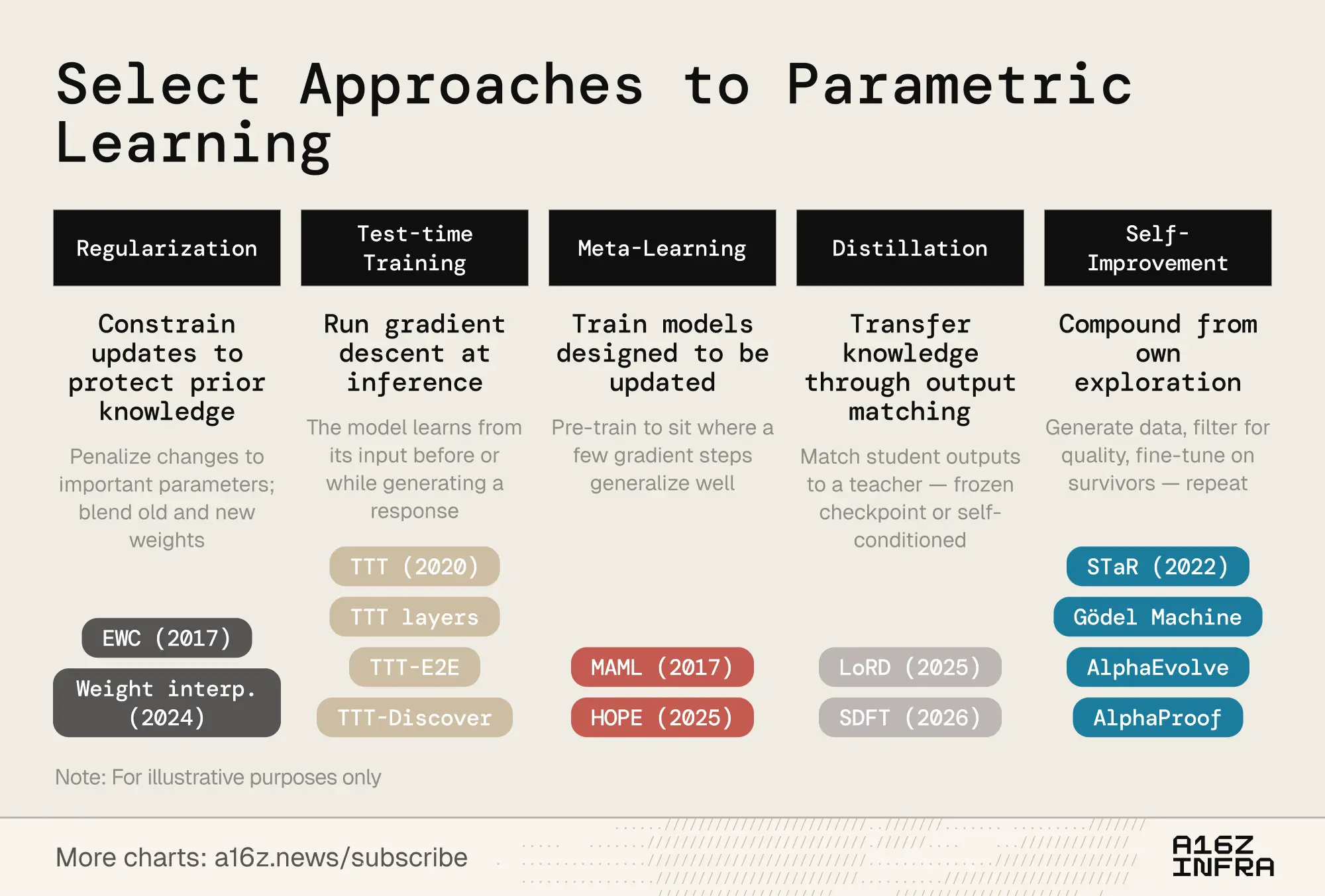
权重级研究景观跨越多条并行的工作线。正则化和权重空间方法是最古老的:EWC(Kirkpatrick 等人,2017)按参数对先前任务的重要性比例惩罚参数变化,权重插值(Kozal 等人,2024)在参数空间中混合新旧权重配置,尽管两者在大规模时都趋于脆弱。测试时训练,由 Sun 等人(2020)开创并演化为架构原语(TTT 层、TTT-E2E、TTT-Discover),采取不同方法:在测试时数据上运行梯度下降,在关键时刻将新信息压缩到参数中。元学习探讨我们是否可以训练学习如何学习的模型,从 MAML 的少样本友好参数初始化(Finn 等人,2017)到 Behrouz 等人的嵌套学习(2025),后者将模型构建为在不同时间尺度上运行的优化问题层次结构,具有受生物记忆巩固启发的快速适应和慢速更新模块。
蒸馏通过让学生匹配冻结的教师检查点来保留先前任务知识。LoRD(Liu 等人,2025)通过同时修剪模型和回放缓冲区使其足够高效以持续运行。自蒸馏(SDFT,Shenfeld 等人,2026)翻转来源,使用模型自身专家条件化的输出作为训练信号,避开了顺序微调的灾难性遗忘。递归自我改进以类似精神运作:STaR(Zelikman 等人,2022)从自我生成的理由引导推理,AlphaEvolve(DeepMind,2025)发现了数十年未被触碰的算法改进,Silver 和 Sutton 的"经验时代"(2025)将智能体框架为从持续的、永不停歇的经验流中学习。
这些研究方向正在趋同。TTT-Discover 已经将测试时训练与 RL 驱动的探索融合。HOPE 在单一架构中嵌套快速和慢速学习循环。SDFT 将蒸馏转化为自我改进原语。各列之间的边界正在模糊——下一代持续学习系统可能会结合多种策略,使用正则化来稳定,使用元学习来加速,使用自我改进来复合。越来越多的初创公司正在押注这个堆栈的不同层次。
4、持续学习创业生态
非参数化端是最熟悉的。框架公司(Letta、mem0、Subconscious)构建编排层和脚手架,管理进入上下文窗口的内容。外部存储和 RAG 基础设施(例如 Pinecone、xmemory)提供检索骨干。数据存在,挑战是在正确的时间将正确的数据切片放到模型面前。随着上下文窗口的扩展,这些公司的设计空间也随之增长,特别是在框架方面,新一波初创公司正在涌现,以管理日益复杂的上下文策略。
参数化端更早期且更多样化。这里的公司正在尝试某种形式的部署后压缩,让模型在权重中内化新信息。方法聚类成几个不同的押注,关于模型在发布后如何学习。
部分压缩:无需重新训练的学习。 一些团队正在构建可附加的知识模块(压缩的 KV 缓存、适配器层、外部记忆存储),专门化通用模型而不触碰其核心权重。共同的论点是:你可以获得有意义的压缩(不仅仅是检索),同时保持稳定性-可塑性权衡可控,因为学习是隔离的而不是分布在整个参数空间中。一个带有正确模块的8B模型可以在目标任务上匹配远大于它的模型的性能。优势在于可组合性:模块可以开箱即用地与现有 Transformer 架构配合使用,可以独立交换或更新,远比重新训练更容易实验。
RL 和反馈循环:从信号中学习。 其他团队押注部署后学习最丰富的信号已经存在于部署循环本身——用户纠正、任务成功和失败、来自真实世界结果的奖励信号。核心理念是模型应该将每次交互视为潜在的训练信号,而不仅仅是推理请求。这与人类在工作中改进的方式非常相似:你做工作,你获得反馈,你内化什么有效。工程挑战是将稀疏的、嘈杂的、有时是对抗性的反馈转化为稳定的权重更新而不发生灾难性遗忘,但从部署中真正学习的模型会以仅上下文系统无法做到的方式随时间复合增长价值。
以数据为中心的方法:从正确的信号中学习。 一个相关但不同的押注是,瓶颈不是学习算法,而是训练数据和周围系统。这些团队专注于策划、生成或合成正确的数据来驱动持续更新:前提是,一个能获得高质量、结构良好的学习信号的模型,只需要更少的梯度步骤就能有意义地改进。这与反馈循环公司自然地联系在一起,但强调的是上游问题:不仅仅是模型是否能学习,而是它应该学习什么以及学习到什么程度。
新颖架构:为学习而设计。 最激进的押注是 Transformer 架构本身就是瓶颈,持续学习需要根本不同的计算原语:具有连续时间动态和内置记忆机制的架构。这里的论点是结构性的:如果你想要一个持续学习的系统,你应该将学习机制构建到基底中。

所有主要实验室也都在这些类别中活跃。一些正在探索更好的上下文管理和思维链推理。其他正在实验外部记忆模块或睡眠时计算管道。几家隐形初创公司正在追求新颖架构。这个领域足够早期,没有单一方法获胜,考虑到使用案例的范围,也不应该有。
5、为什么朴素的权重更新会失败
在生产中更新模型参数会引入一系列故障模式,到目前为止在大规模上尚未解决。

工程问题是有据可查的。灾难性遗忘意味着足够敏感以从新数据中学习的模型会破坏现有表示——稳定性-可塑性困境。时间解纠缠是指不变规则和可变状态被压缩到相同的权重中,所以更新一个会破坏另一个。逻辑整合失败是因为事实更新不会传播到其后果:更改局限于 token 序列,而非语义概念。而遗忘仍然是不可能的:没有可微的减法操作,所以错误或有毒的知识没有手术式的补救措施。
但还有一组较少被关注的问题。当前训练和部署之间的分离不仅仅是一个工程便利——它是一个安全、可审计性和治理边界。打开它,几件事会同时崩溃。安全对齐可能不可预测地退化:即使在良性数据上的窄范围微调也可能产生广泛不对齐的行为。持续更新创建了数据投毒面——一种缓慢、持久地存在于权重中的提示注入版本。可审计性崩溃,因为持续更新的模型是一个移动目标,无法版本化、回归测试或一次性认证。当用户交互被压缩到参数中时,隐私风险加剧,将敏感信息烘焙到远比检索到的上下文更难过滤的表示中。
这些都是开放问题,不是根本不可能的事情,解决它们与解决核心架构挑战一样,都是持续学习研究议程的一部分。
6、从《记忆碎片》到记忆
莱纳德在《记忆碎片》中的悲剧不是他无法运作:他很足智多谋,在任何给定场景中甚至很出色。他的悲剧是他永远无法复合。每一次经历都保持外部——一张宝丽来、一个纹身、一张别人手写的便条。他可以检索,但他无法压缩新知识。
当莱纳德在这个自建的迷宫中穿行时,真相与信念之间的界限开始模糊。他的状况不仅剥夺了他的记忆;它迫使他不断重建意义,使他同时成为自己故事中的调查者和不可靠的叙述者。
今天的 AI 在相同的约束下运作。我们已经构建了极其强大的检索系统:更长的上下文窗口、更智能的框架、协调的多智能体群,它们有效!但检索不是学习。一个可以查找任何事实的系统没有被迫使找到结构。它没有被迫使进行泛化。使训练如此强大的有损压缩——将原始数据转化为可迁移表示的机制——正是我们在部署的那一刻关闭的东西。
前进的道路可能不是单一突破,而是一个分层系统。上下文学习将仍然是适应的第一线:它是原生的、经过验证的,并且在不断改进。模块机制可以处理个性化和领域专业化的中间地带。但对于困难问题——如发现、对抗性适应、太隐晦而无法用文字表达的知识——我们可能需要在训练后将经验压缩到参数中的模型。这意味着在稀疏架构、元学习目标和自我改进循环方面的进展。它可能还要求我们重新定义"模型"甚至意味着什么:不是一组固定的权重,而是一个不断发展的系统,包括其记忆、其更新算法,以及从自身经验中抽象的能力。
文件柜越来越大。但更大的文件柜仍然是文件柜。突破在于让模型在部署后做使它在训练期间如此强大的事情:压缩、抽象和学习。我们正站在从失忆模型转向具有一丝经验的模型的门槛上。否则,我们将被困在自己的《记忆碎片》中。
原文链接: Why We Need Continual Learning
汇智网翻译整理,转载请标明出处
