构建可靠的本地编程代理
我们如何将一个强大的本地模型转变为受监督的工程系统。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
运行一个有能力的本地编程代理已经不再是理论上的事情了。借助 Nvidia DGX Spark 这样的机器(我拥有的是华硕 GX10),可以在本地服务一个大型模型,并将其连接到 OpenCode 这样的编程工具和 Hermes 这样的自主代理上。
但我们的实验揭示了一个重要的事实:拥有一个强大的本地模型并不等于拥有一个可靠的工程系统。
本文记录了我们在将 Qwen 3.6 35B A3B(同样的逻辑也适用于其他类似规模的模型)集成到本地 ResonantOS 工作流中所学到的东西,为什么我们放弃了期望一次性完美编程,以及我们如何使用 OpenCode、Hermes 和 Codex 设计一个更可靠的本地工程循环。
1、目标
目标很简单:
让本地模型 24/7 可用于真正的工程工作。
实际上,这意味着:
- OpenCode 应该能够使用 GX10 托管的模型进行编程。
- Hermes 应该能够将工程任务委派给同一个本地模型。
- ResonantOS 应该能够要求一个 Engineer 代理在后台工作。
- 该模型应该适用于代理工作,而不仅仅是聊天。
- 系统应该在本地运行,而不必依赖云端推理来完成每项编程任务。
我们在这个阶段选择的模型是:
Qwen 3.6 35B A3B Q4_K_M,通过 llama.cpp 在 GX10 上运行。
GX10 充当推理服务器。Mac Mini 保持为编排器和软件主机。
2、为什么选择 Qwen 3.6 35B A3B?
我们测试了不同的选项,包括 Gemma 4 26B 和 Qwen 的各种变体。权衡不仅仅是原始的每秒 token 数。对于代理编程,我们关心的是:
- 指令遵循能力
- 工具使用
- 长上下文
- 稳定性
- 处理并行工作的能力
- 代码审查质量
- 持续运行的能力
Qwen 3.6 35B A3B 成为实际选择,是因为在我们本地测试的替代方案中,它在编程和代理使用方面提供了更好的平衡。
目标配置变为:
- 2 个并行活跃代理
- 每个活跃代理约 200k 上下文
- 模型始终可用
- OpenCode 和 Hermes 都指向同一个本地端点
重要的教训是,模型选择只是问题的一部分。更大的问题是:当模型不如 Codex 或前沿云模型强大时,我们如何让系统变得可靠?
3、第一个问题:提示词不是执行机制
最初,我们为 OpenCode 配置了一个默认的工程循环:
- 实现阶段
- 审查阶段
- 修复阶段
- 验证阶段
这个想法是 Qwen 不应该把第一次实现当作最终结果。它应该自我审查,修复具体问题,然后运行确定性检查。
这改善了行为,但并没有解决问题。
在一次测试中,OpenCode 成功地编写了可工作的代码并通过了测试。但当我们检查结果时,它仍然违反了任务边界。提示词说只修改两个文件,但 OpenCode 还编辑了 package.json。
这就是关键的失败模式:
模型可以理解规则、重复规则,但仍然违反规则。
这不是 Qwen 独有的问题。较小或本地模型尤其容易受到这种漂移的影响,但即使是更强的模型也能从外部执行中受益。
结论很明确:
仅靠提示词是不够的。
4、Codex 帮助我们发现了什么
Codex 在这些实验中充当了监督工程师的角色。
它的作用不仅仅是编写代码。它帮助我们:
- 检查 OpenCode 实际修改的文件
- 将结果与用户的原始约束进行比较
- 运行独立的验证命令
- 检查 Qwen 和 llama.cpp 的指标
- 识别 OpenCode 最终报告何时不完整
- 区分"测试通过"和"任务正确完成"
这很重要,因为 OpenCode/Qwen 经常产生看似合理的摘要。但看似合理的摘要不是证据。
Codex 反复检查了实际状态:
git diff --name-only
npm run test:health
npm test
node scripts/health-check.mjs --json
这将过程从"信任代理"转变为"验证工件"。
5、解决方案:在模型周围构建一个 Runner
解决方案是停止将 OpenCode/Qwen 视为权威。
相反,我们将它视为确定性工程系统中的一个工作单元。
提出的架构是一个 Engineer Runner。
Runner 拥有:
- 任务边界
- 允许的文件
- 必需的命令
- 审查阶段
- 验证
- 最终状态
OpenCode/Qwen 拥有:
- 实现
- 本地推理
- 代码编辑
- 提出的修复
Runner 不信任模型的说法。它直接检查仓库。
6、人工工作流
应该有两种使用系统的方式。
6.1 直接使用 OpenCode 工作台
用户打开 OpenCode 并交互式地工作,类似于使用 Codex。
但与其启动一个不受限制的任务,OpenCode 通过一个受保护的 runner 启动:
engineer-runner open
用户提供:
- 仓库
- 目标
- 允许的文件或目录
- 必需的测试
- 严格级别
OpenCode 仍然感觉是交互式的,但 Runner 执行规则。
6.2 ResonantOS 委派
用户在 ResonantOS 中与 Augmentor 对话:
"让工程师给健康检查添加 JSON 导出。"
Augmentor 创建一个结构化的任务合同并将其发送给 Runner。
用户可以继续使用 Augmentor,同时工程师在后台工作。
结果不是"OpenCode 说它完成了"。
结果是:
{
"status": "verified",
"changedFiles": [
"scripts/health-check.mjs",
"scripts/health-check.test.mjs"
],
"scopeOk": true,
"commands": [
{
"cmd": "npm run test:health",
"status": 0
}
],
"reviewFindings": []
}
7、架构图
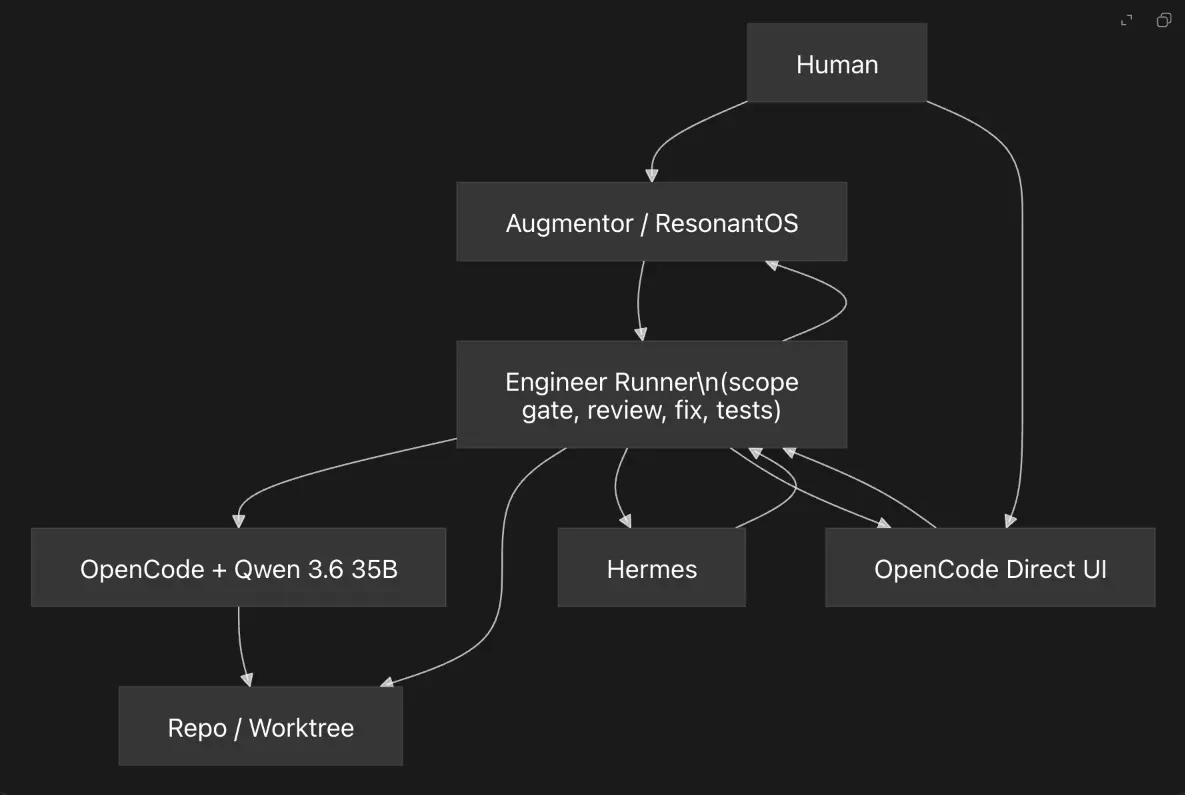
8、为什么 Runner 很重要
Runner 为我们提供了模型自身无法提供的保证。
例如:
8.1 范围门控
如果任务只允许:
scripts/health-check.mjs
scripts/health-check.test.mjs
Runner 检查:
git diff --name-only
如果 package.json 被修改了,运行会自动失败。
不需要模型判断。
8.2 验证门控
如果任务需要:
npm run test:health
Runner 直接执行它。
模型不能在没有证据的情况下声称成功。
8.3 审查分离
与其要求同一个模型在一个响应中"请审查你自己",Runner 可以启动一个单独的审查阶段:
- 实现会话
- 审查会话
- 修复会话
- 验证会话
即使使用同一个本地模型,这也创建了一个更可靠的循环。
9、GX10 架构挑战
GX10 功能强大,但它也带来了自身的约束。
硬件使用 NVIDIA 较新的 GB10 / Blackwell 级架构。这意味着许多普通的 PyPI GPU wheel 不是最佳路径。GPU 工作负载需要小心处理,通常通过兼容的 NVIDIA 容器或已知良好的构建来完成。
我们测试了 llama.cpp 和 vLLM 风格的方法。
使用 NVFP4 和 DFlash 的 vLLM 很有吸引力,因为它可能为特定模型提供更高的吞吐量和更好的服务行为。但对于一个始终在线的本地编程代理来说,稳定性比峰值吞吐量更重要。
在这个阶段,实际系统使用 llama.cpp,因为:
- 它对于持续服务来说足够稳定
- 在我们的测试中它很好地处理长上下文
- OpenCode 和 Hermes 可以通过 OpenAI 兼容端点调用它
- 它避免了我们在探索 vLLM 设置时看到的不稳定性
- 它使 24/7 使用的架构更简单
关键的洞察是,服务后端只是其中一层。即使 vLLM 后来提高了速度,Runner 模式仍然是必要的。
10、我们学到了什么
最重要的教训是:
- 本地模型可以是有用的编程工作者。
Qwen 3.6 35B 可以编写代码、运行工具和修复问题。 - 本地模型不应该被信任为最终审查者。
它们可以通过测试同时违反任务边界。 - 提示词改善了行为但不能执行行为。
模型可以理解规则但仍然打破它。 - 可靠性来自外部结构。
Git diff、测试、允许文件门控和机器可读的报告比模型自我报告更强大。 - Codex 作为监督工程师很有用。
它帮助我们识别失败模式、检查真实工件,并设计了一个更健壮的工作流。 - 未来系统不应该是"Qwen 替代 Codex"。
更好的架构是:Qwen 处理本地劳动,系统执行正确性。
11、方向
下一步是将 Engineer Runner 实现为 ResonantOS 的一等公民。
这将为我们提供:
- 直接的受保护 OpenCode 会话
- 来自 Augmentor 的后台工程师委派
- 兼容 Hermes 的任务提交
- 确定性报告
- 本地 24/7 工程能力
最终架构不是"信任本地模型"。
它是:
将本地模型作为可靠工程流程中的工作者使用。
这就是通往本地 AI 工程系统的实用路径——它比前沿云工具慢,但可用、私密、持久,且越来越可靠。
原文链接: Building a Reliable Local Coding Agent with Qwen 3.6, OpenCode, Hermes, and Codex
汇智网翻译整理,转载请标明出处
