端到端可微分自动驾驶
大融合:当所有子系统合为一体

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
在自动驾驶的早期,软件栈看起来像工厂的流水线:
- 摄像头捕捉像素
- 感知模块检测车道
- 预测模块预估行人和车辆
- 规划模块计算轨迹
- 控制模块调整转向和油门
每个阶段都是手工设计的。每个阶段将输出传递给下一个,像脆弱的多米诺骨牌。
如果车道检测稍有偏差 → 规划器产生不安全的路径。如果预测器误判了一辆车 → 控制器可能过度转向。误差级联放大。
这种模块化流水线功能强大,但很脆弱。
1、现代自动驾驶:统一时代
约在2022–2025年间,一种新的理念出现了:
"与其分别优化五个子系统,不如训练一个统一的大脑,让它们联合学习。"
这是以下技术背后的哲学:
- Tesla 的端到端神经管道
- Wayve 的 LINGO 系列
- UniSim、UniDrive
- Dreamer 风格的潜在空间智能体
- 用于样本高效控制的 TD-MPC
而现在,在这个博客系列中,你的自动驾驶汽车达到了这个水平。
第6篇博文正是汽车从"模块"进化为一个单一神经有机体的时刻。
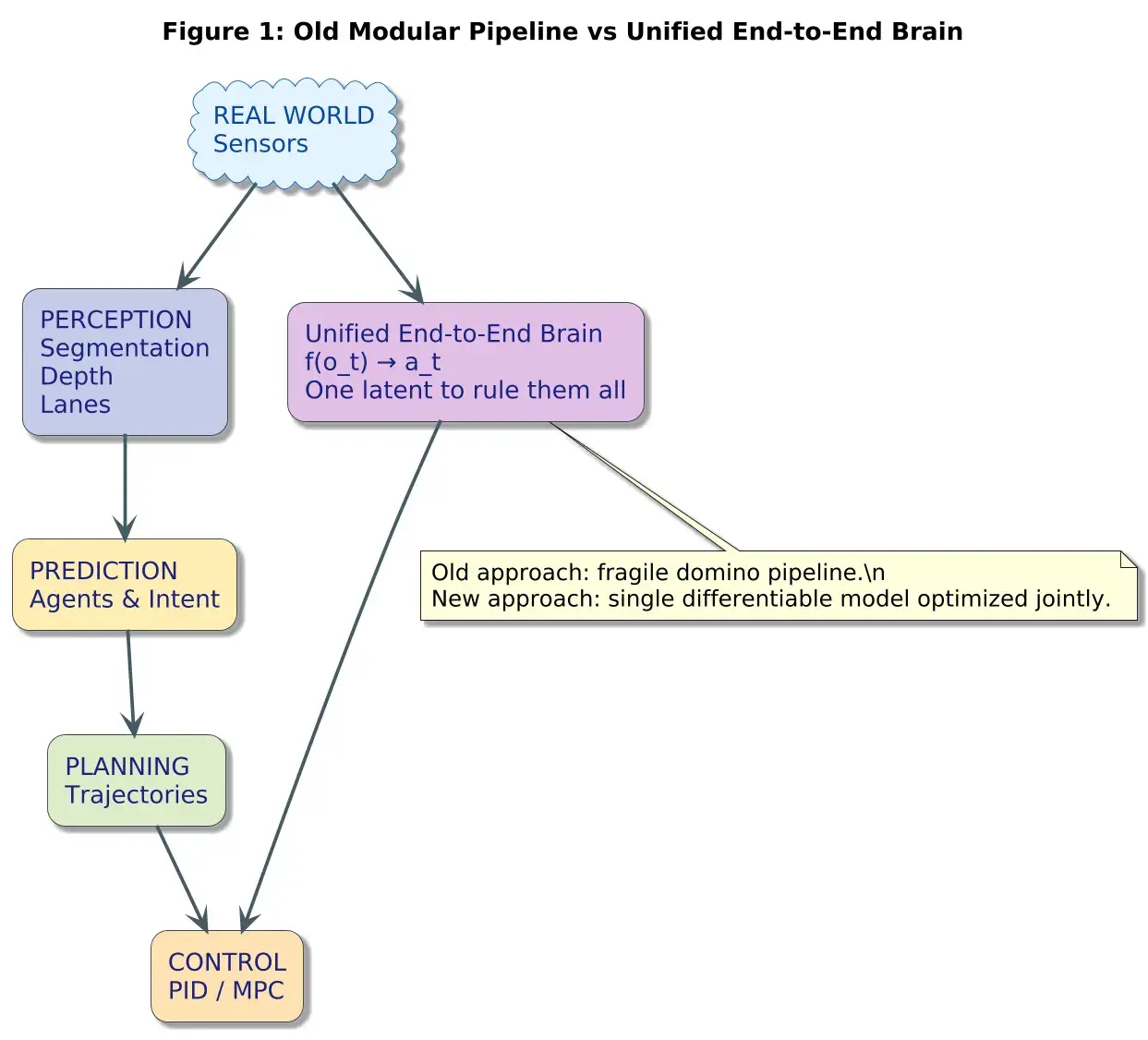
2、为什么统一改变了一切
问题1:误差累积
如果感知偏差5厘米 → 预测出错 → 规划出错 → 控制出错。
问题2:模块之间没有梯度
规划器无法告诉感知哪些特征重要。感知无法知道它的误差是否会在下游产生影响。
问题3:训练目标不匹配
感知学习的是分割精度,但规划需要的是安全、进展和舒适——而不是分割的IoU。
解决方案:端到端优化
现在损失函数变成了:
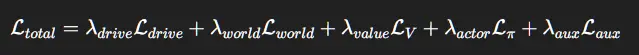
这意味着:
- 感知编码器接收规划梯度
- 世界模型接收控制梯度
- 策略直接接收感知特征
- 所有子系统学习一个共享的潜在表征 z
这就像让五个孩子分别学习五门独立科目,与教一个孩子掌握一项协调运动技能之间的区别。
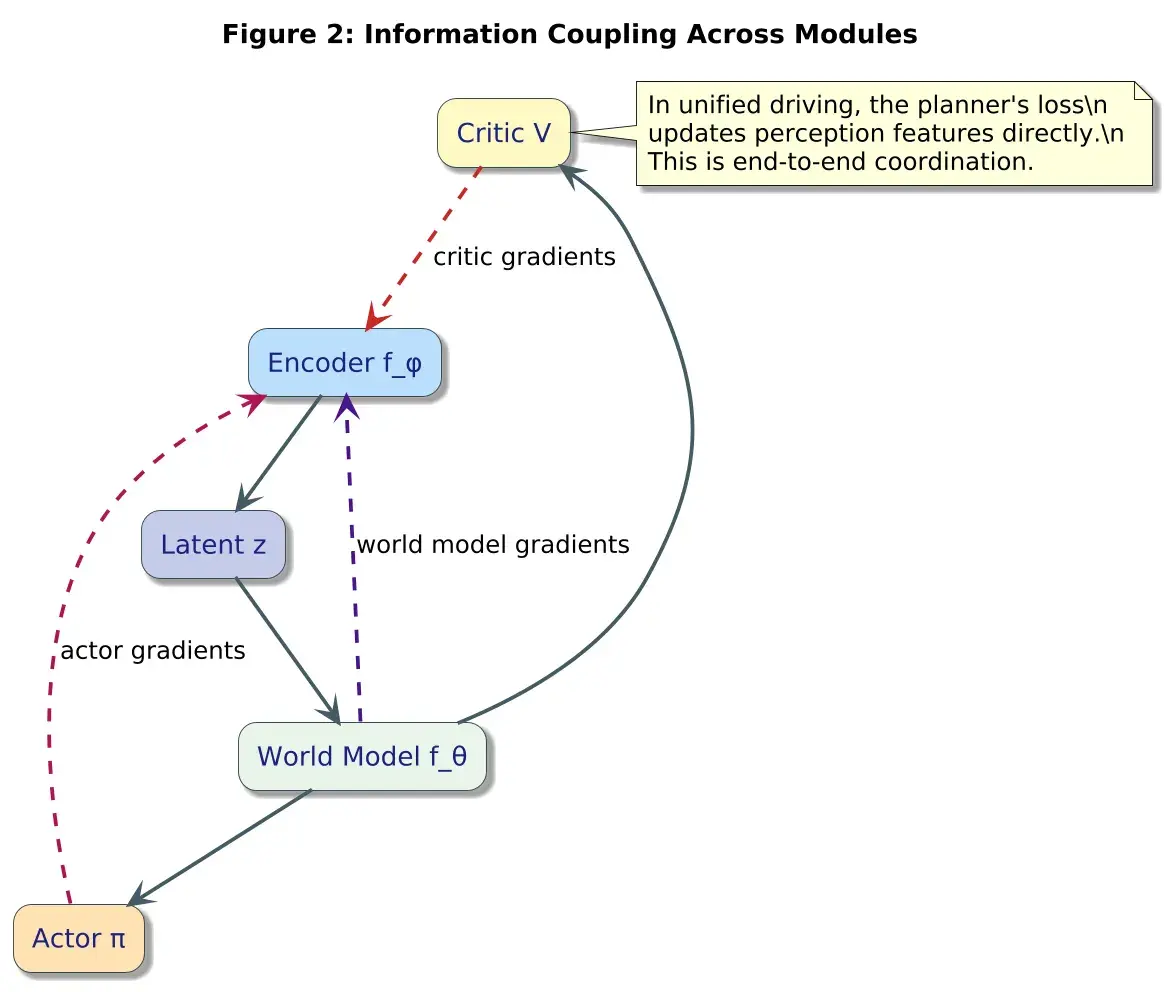
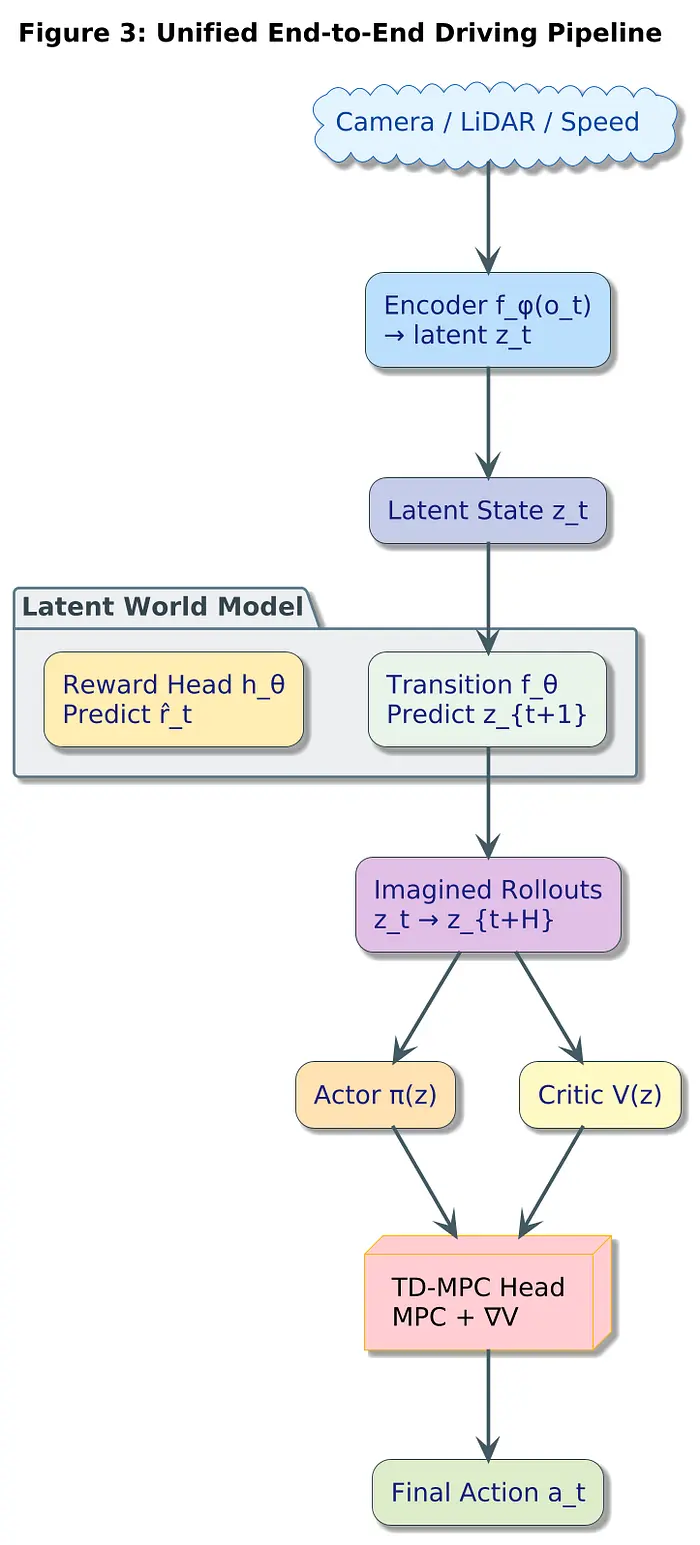
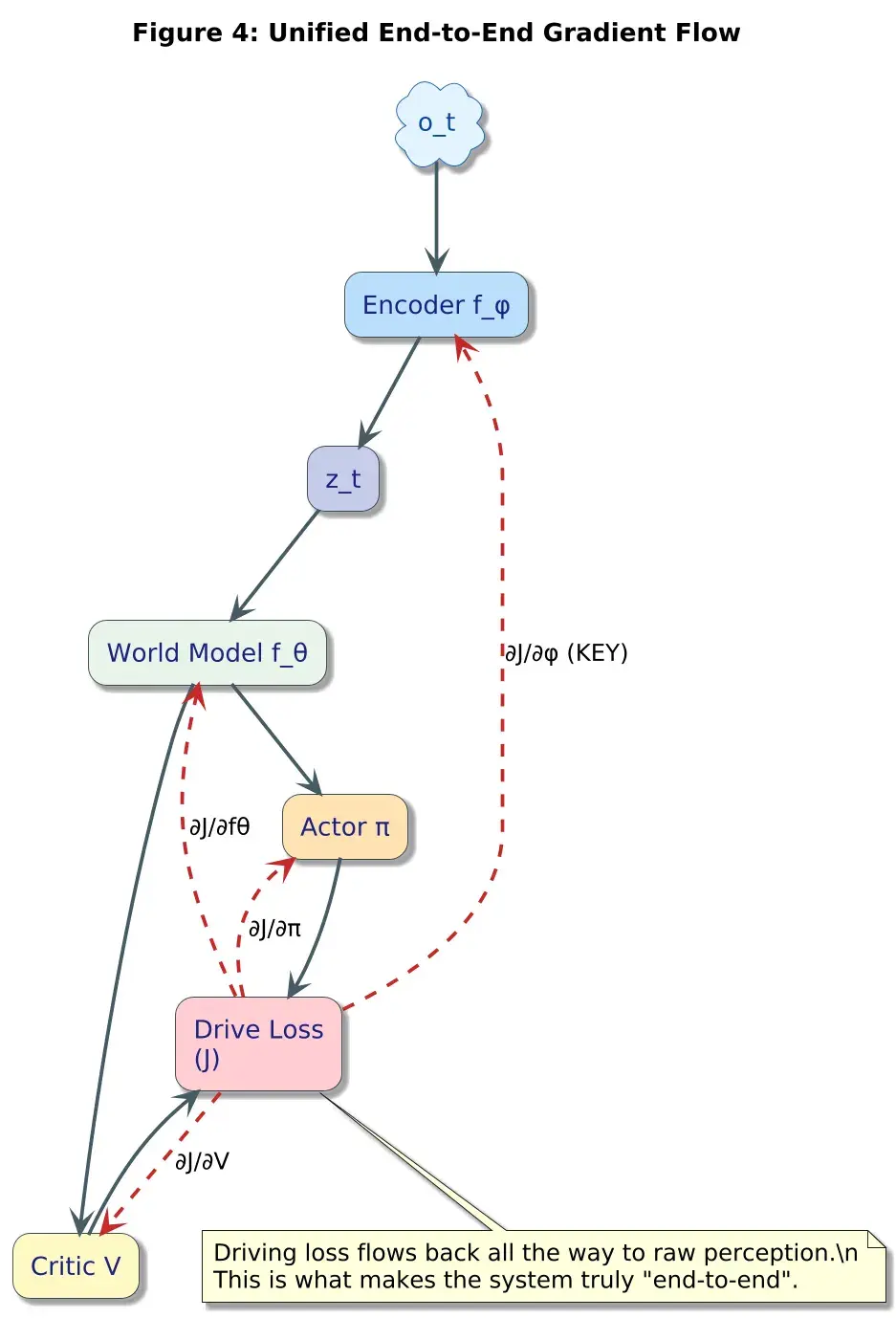
3、统一架构:一个单一的可微分循环
我们把第1–5篇博文中的所有内容连接成一个连续的计算图:
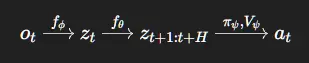
逐步解析:
3.1 编码器(感知)
提取紧凑的潜在信念状态:
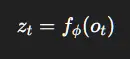
这取代了:
- 车道检测
- 可行驶区域地图
- 语义分割
- 深度预测
全部融合到一个潜在表征中。
3.2 世界模型
预测未来的潜在状态和奖励:

与第3篇博文相同。
3.3 想象推演
在潜在空间内模拟未来:
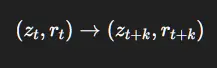
与 Dreamer 类似。
3.4 参与者(策略)
直接从潜在状态生成动作:
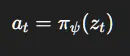
3.5 评论家(价值函数)
预测长期回报:
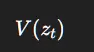
3.6 TD-MPC 头部
融合 MPC 规划与价值梯度:
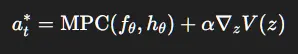
这稳定了控制。
3.7 辅助感知头
用于训练稳定性:
- 未来占用率
- 碰撞时间(TTC)地图
- 车道偏离
- 交通灯状态
- 行人接近度
所有这些共同塑造 z_t。
4、端到端损失函数(完整数学)
主目标函数:

其中:
4.1 世界模型损失
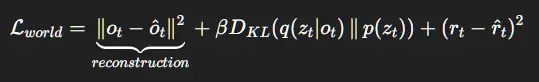
4.2 参与者损失
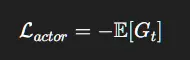
4.3 评论家(TD)损失
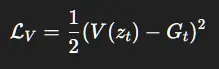
4.4 辅助损失

4.5 安全损失(可微分!)
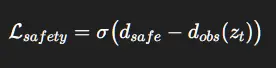
其中 σ(⋅) 是 softplus。
所有梯度都反向传播到:
- 编码器权重
- 世界模型
- 演员
- 评论家
这就是真正的端到端优化。
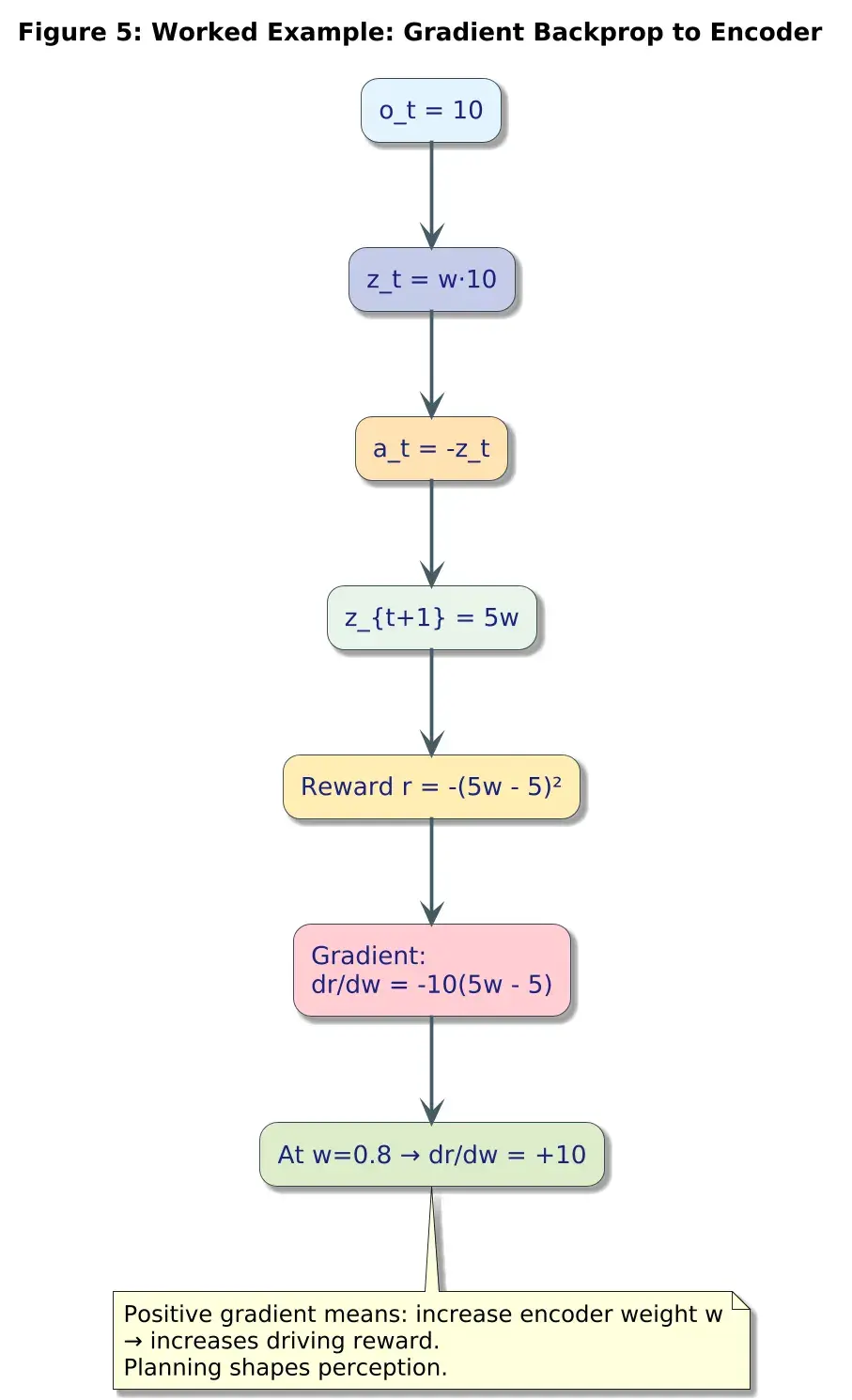
5、数值示例1:感知通过控制损失来学习
这是核心思想:规划梯度流入感知权重。
设:
- 观测 o_t = 10
- 编码器:z_t = f_φ(o_t) = w · o_t,其中 w 可训练
- 世界模型:z_{t+1} = z_t + 0.5a_t
- 策略:a_t = -z_t
- 奖励:r_t = -(z_{t+1}-5)²
我们要计算:
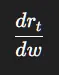
第1步:计算 z_t
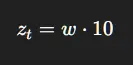
第2步:策略输出动作
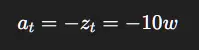
第3步:世界模型预测

第4步:奖励函数
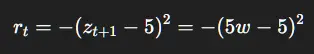
第5步:计算梯度
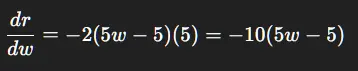
取 w = 0.8:
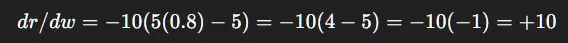
含义: 增大编码器权重 w 会增加奖励。规划损失直接塑造感知!
这就是端到端驾驶的核心。
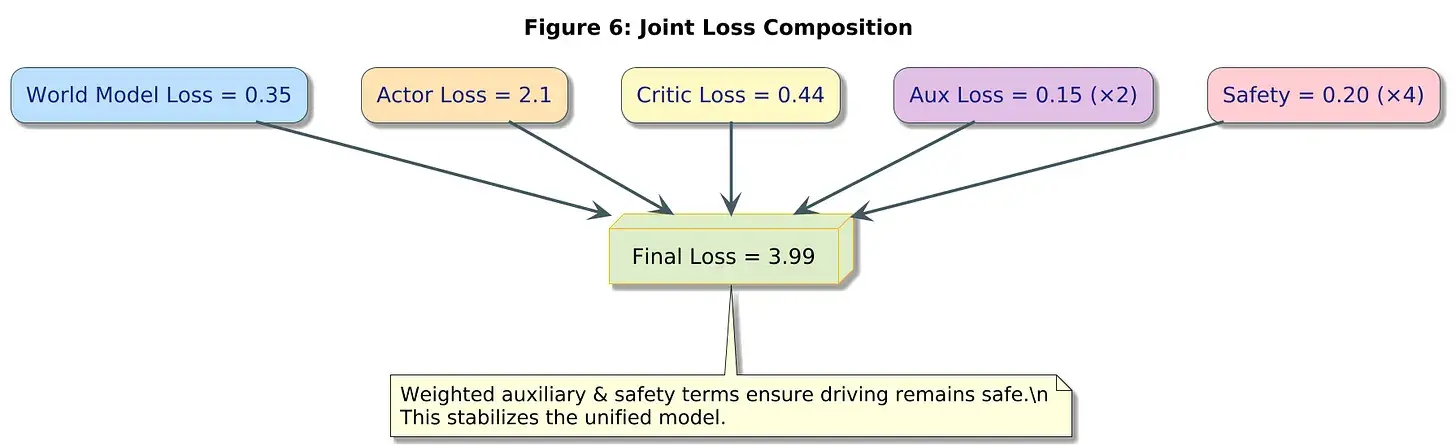
6、数值示例2:带辅助项的联合损失
设:
- 世界模型损失 = 0.35
- 演员损失 = −2.1(负值表示最大化)
- 评论家损失 = 0.44
- 车道偏离 = 0.15
- 安全惩罚 = 0.20
权重:
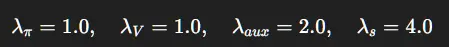
计算:

逐步计算:
- 2(0.15) = 0.30
- 4(0.20) = 0.80
所以:
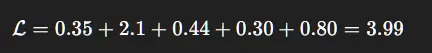
解读: 安全项主导损失(0.8)。参与者受到强烈激励去避免不安全状态。
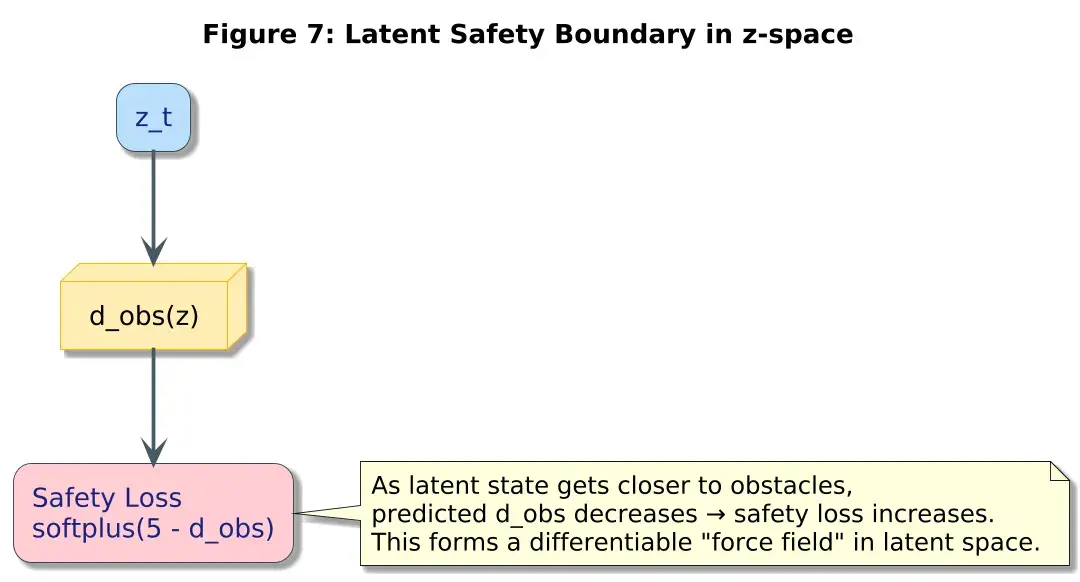
7、统一端到端学习中的安全性
安全变得可微分:

其中 d_obs 从潜在空间预测得到。
这产生了:
- 平滑的梯度
- 安全感知的潜在表征
- 隐式的碰撞边界
模型在潜在空间中学会了"危险"的含义。
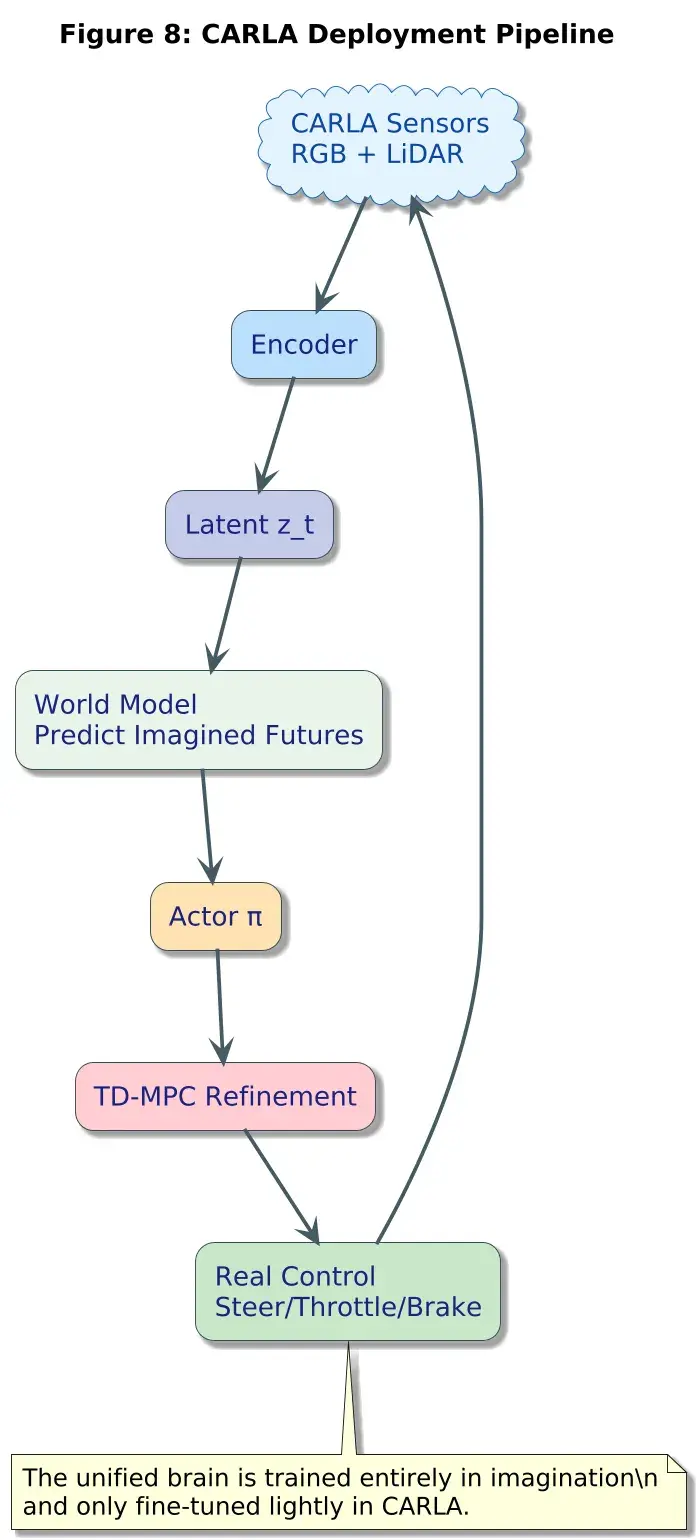
8、部署:当统一大脑在CARLA中驾驶
完全在想象空间内训练完成后:
- 将 CARLA 图像编码为 z
- 预测未来的 z
- 演员生成动作
- TD-MPC 进行精炼
- 在 CARLA 中执行动作
- 反馈循环
这个系统:
- 能即时适应天气变化
- 对新地图具有更好的泛化能力
- 避免了手工设计的脆弱规则
- 计算效率高(单次前向传播)
9、结束语
想象一下让五位音乐家独立学习:一个学小提琴,一个学鼓,一个学钢琴……然后强迫他们一起演奏。结果是混乱的,因为他们从未学习过如何协调。现在想象一下训练整个乐团一起演奏:每位音乐家都能听到其他人的声音,调整节奏、速度和和声。这就是端到端驾驶。所有组件作为一个统一整体共同学习。
原文链接:One Brain to Drive Them All: End-to-End Differentiable Autonomous Driving
汇智网翻译整理,转载请标明出处
