本体论、知识图谱与人工智能
本体论和知识图谱是已有数十年历史的概念,但大多数人仍然把它们搞混。人工智能是重塑这两者的新力量——借助 WebLLM,它现在可以运行在一个浏览器标签页中。以下三者如何协同工作。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
本体论和知识图谱源自语义网世界,人们经常把它们混为一谈——说"知识图谱"时其实指的是本体论,说"本体论"时其实只是指带箭头的图表。这两者确实是不同的东西,而区别正是本文首先要厘清的。
人工智能不是这个组合中的第三个同义词——它是作用于两者的新力量。几十年来,构建知识图谱意味着需要大量人工策展人员或脆弱的、手工调优的提取器,而编写本体论意味着专家伏案于形式化编辑器前。大语言模型改变了这一切:给LLM一段文字,它会在几秒钟内返回实体和关系。那些古老而费力的学科突然有了一个快速、粗糙、却出奇强大的新引擎。
WebLLM 让这一转变变得几乎荒诞:它完全在浏览器中运行LLM——没有服务器、没有云推理、没有数据离开你的机器。将文本转化为图谱的门槛降到了只需一次粘贴和点击。
我希望让人们更容易理解本体论和知识图谱的基础——不是通过阅读另一个定义,而是通过观察它们从真实文本中成形。所以我构建了一个小型实验工具 GraphBaby 来做这件事:粘贴文本,一个本地LLM就会起草一个真实的 OWL 本体——包括类、属性和个体——然后你可以编辑它、以层级结构浏览、以图谱形式可视化并导出。它将三者放在同一个地方:AI 执行提取,本体论提供规则,填充的个体形成知识图谱。它刻意停下来的地方,和它做的事情一样有启发意义——但稍后再谈。
演示: https://vishalmysore.github.io/graphbaby/
本文利用这个小实验来厘清这三者的关系。让我们从基础开始。
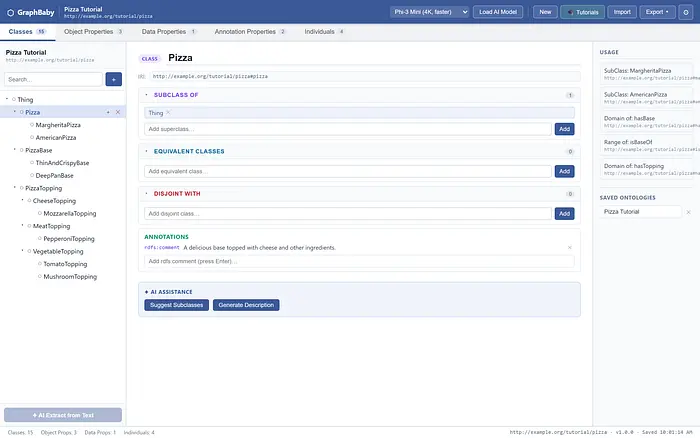
GraphBaby的三窗格编辑器——类树(左)、带有公理的实体编辑器(中)和实时使用面板(右)。此处加载的是捆绑的 Pizza 教程本体。
1、什么是本体论?
本体论是一个领域中概念以及支配这些概念如何关联的规则的形式化、明确的规范。它是意义的模式——蓝图,而非建筑。
借自哲学(其中"本体论"是对存在什么的研究),在计算机科学中,它回答了关于一个领域的三个问题:
- 存在哪些种类的事物?(类/类型)——例如
Person、Organization、Disease、Medication。 - 它们如何关联?(属性/关系)——例如
Person可以worksAt一个Organization;Medicationtreats一个Disease。 - 哪些规则必须成立?(公理/约束)——例如"每个
Patient是一个Person","treats只连接Medication和Disease","一个Person有且仅有一个dateOfBirth"。
2、定义性特征:可推理的规则
使本体论成为本体论——而不仅仅是一个带标签的图表——是它编码了机器可以推理的逻辑。如果你的本体说明:
Cardiologist是Doctor的子类Doctor是Person的子类
……那么一个推理器可以推断,在没有额外数据的情况下,每个 Cardiologist 都是 Person。没有人需要写下那个事实。这种推理能力是这个概念的核心。
本体论通常用形式化语言编写:
| 语言 | 功能 |
|---|---|
| RDFS | 基本的类、子类、属性 |
| OWL (Web本体语言) | 丰富逻辑:基数、不相交性、传递性、等价性 |
| SHACL | 形状约束/验证规则 |
一个用 Turtle(RDF语法)编写的小型本体片段如下:
:Doctor rdfs:subClassOf :Person .
:Cardiologist rdfs:subClassOf :Doctor .
:treats rdfs:domain :Medication ;
rdfs:range :Disease .
这没有说明任何具体的医生。它描述了医学领域的现实形状。这就是本体论:词汇和规则,与任何特定数据分离。
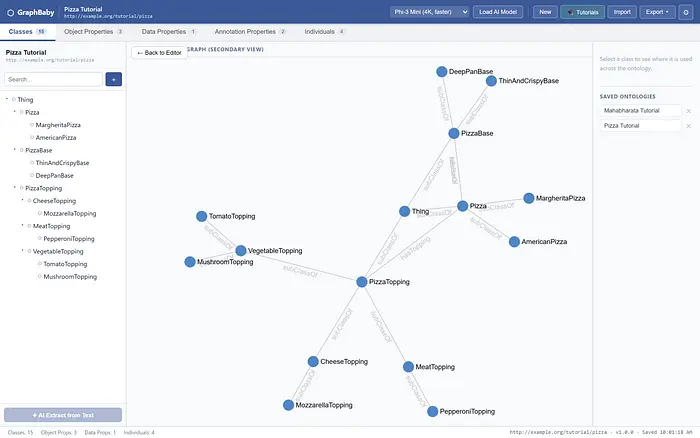
可视化的模式:GraphBaby的图谱视图单独显示了类层级——Pizza、PizzaBase 和 PizzaTopping 分支出子类,通过 subClassOf 和属性边连接。看不到任何一个具体的披萨;这是蓝图。
3、什么是知识图谱?
知识图谱是一个以图谱形式表示的真实、具体事实的网络:节点(实体)通过边(关系)连接。它是数据,是填充后的实例——是建筑,而非蓝图。
事实以三元组形式存储:
(主体) --[谓词]--> (客体)
例如:
(阿尔伯特·爱因斯坦) --[提出了]--> (相对论)
(阿尔伯特·爱因斯坦) --[工作于]--> (普林斯顿大学)
知识图谱通过遍历边来回答诸如*"爱因斯坦在哪里工作?"*的问题。它是具体的、实例层面的,并通过添加更多事实来增长。Google的知识图谱(搜索结果中的信息框)、Wikidata 和企业客户360图谱都是知识图谱:大量具体实体和关系的集合。
在 GraphBaby 中,这些事实作为个体存在——Einstein、Princeton——每个都由本体中的类来定型,并通过本体的对象属性链接。裸三元组是概念;类型化的、受模式约束的个体才是工具实际存储的内容。我们稍后会看到为什么这个区别很重要。
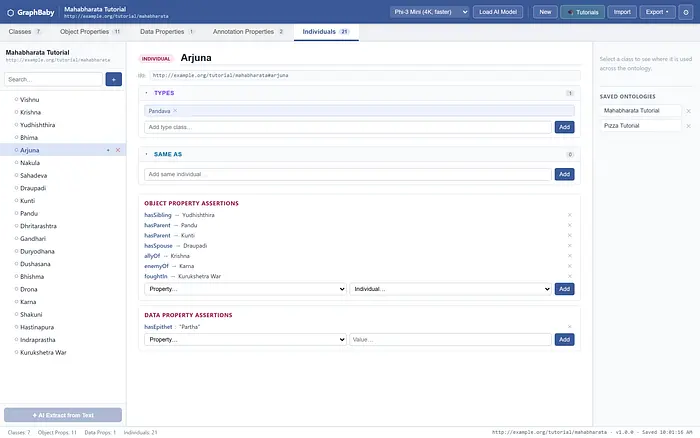
个体是事实存在的地方。这里 Arjuna(来自捆绑的摩诃婆罗多教程)被定型为 Pandava,并与具体断言相连:hasParent → Kunti、hasSpouse → Draupadi、allyOf → Krishna、enemyOf → Karna、foughtIn → Kurukshetra War。每一条边都指向另一个真实个体;这就是知识图谱。
4、人工智能的切入点
这就是使 GraphBaby 成为2026年项目而非2006年项目的原因。
传统上,本体论首先出现——由专家在形式化本体编辑器中费力地手工编写——然后数据才由人工策展人员或脆弱的基于规则的提取器注入其模具。两个步骤都很慢。
GraphBaby 将两个步骤都交给了 AI,按正确的顺序。一个本地大语言模型——通过 WebGPU 上的 WebLLM 完全在浏览器中运行——分两次完成工作,而顺序就是关键:
- 首先,起草模式。系统提示字面意思是*"你是一个 OWL 本体类层级设计者。"*模型读取文本并提出类及其
subClassOf层级——即 TBox,本体本身。 - 然后,在约束下填充。第二个提示——"你是一个 OWL 个体提取器……不要发明新类"——向模型提供已批准的类和属性,并要求它提取符合它们的个体。第一步的模式成为第二步的缰绳。
这是实验的关键,它有两面性:
- AI 使本体论变得廉价。过去需要一个本体论专家和一个 NLP 团队的工作,现在变成了一次粘贴和点击。第一个本体的门槛降到了接近零。
- AI 本身是不可靠的。不加约束的话,模型会发明类、错误标记类型、断言无意义的关系。GraphBaby 的答案是让 AI 自己的第一轮本体来约束其第二轮提取——模式就是护栏。
这正是这三者向我展示它们关系的方式:AI 是引擎,本体论是护栏,而个体的知识图谱是当你将第一个指向第二个时得到的结果。
5、核心区别,简洁陈述
本体论是模式。知识图谱是数据。AI 是引擎——既能产生也能污染数据。
本体论说"一个人可以在一家组织工作。"知识图谱说"爱因斯坦在普林斯顿工作。"AI 就是将句子"爱因斯坦在普林斯顿工作"转化为那个三元组的东西——带着猜测和一切。
一个来自数据库的有用类比:
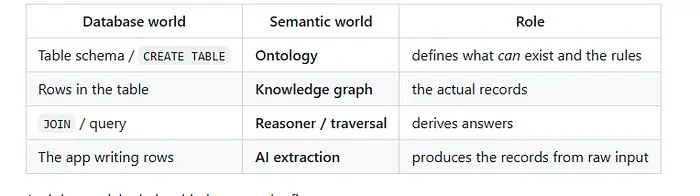
以及前两者之间的关键关系:
- 知识图谱可以建立在本体论之上(这时它是一个"语义丰富"或"基于本体"的知识图谱——可以被验证和推理)。这正是 GraphBaby 所生产的:每个个体都由一个本体类定型。
- 知识图谱也可以在没有本体论的情况下存在——只是带有自由格式标签的节点和边,没有强制规则。这些有时被称为"标注属性图",就是从没有模式的纯文本到图谱的提取器所得到的。
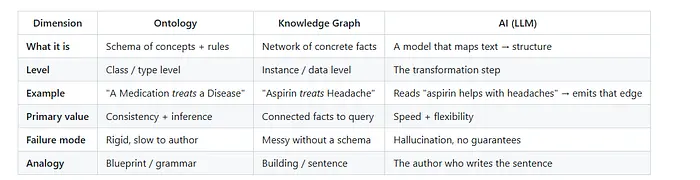
本体论是一个领域的形式化模式——类、允许的关系和机器可以推理的逻辑规则。知识图谱是填充的数据——具体实体和连接它们的事实。人工智能是现在可以在几秒钟内将原始文本转化为两者的引擎——出色地,而且没有内置的正确性保证。
我构建 GraphBaby 作为实验,将三者放在一个浏览器标签页中观察它们交互,而令人惊讶的是一个浏览器内 LLM 能做到什么程度:它起草了一个真正的 OWL 本体,然后用遵守它的类型化个体来填充。它停下来的地方——存储公理但没有推理它们——正是可读的本体和会思考的本体之间的那条线。蓝图、建筑和浇筑混凝土的机器:只有当你看到单个工具试图成为三者时,你才能真正看到每个在哪里结束。
原文链接: Ontologies, Knowledge Graphs, and Artificial Intelligence (Live Demo)
汇智网翻译整理,转载请标明出处
