Physical AI Studio 模仿学习管道
Physical AI Studio 是一个端到端框架,用于通过人类示范的模仿学习来教导机器人。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
机器人技术传统上是一个高度确定性的世界。它需要精确性、同步性和通常以千赫兹频率运行的控制循环。AI 也在机器人技术中发挥了作用,但通常只是作为附加组件。旧的方法依赖于手动调整的感知、脆弱的状态机和仅在严格控制条件下才能工作的运动脚本。
在现实世界中,这很快就会崩溃。
这就是 Physical AI 背后的推动力:从数据中学习、融合感知和行动、并以足够快的速度闭合循环以发挥作用的系统。重心正在从手动编写机器人行为转向构建工作流,这些工作流可以随着任务、环境和现实世界约束的变化而持续地教导和重新教导机器人。
这种转变正是 Physical AI Studio 重要的原因。

Physical AI Studio 是一个端到端框架,用于通过人类示范的模仿学习来教导机器人。该仓库提供了 GUI 应用程序和 Python/CLI 接口,并强调了从示范记录到机器人部署的端到端路径。应用程序文档 特别涵盖了机器人和摄像头设置、数据集收集、模型训练和面向部署的工作流。
在这第一篇文章中,我们不想直接跳到数据集或策略名称。这不是大多数开发者真正开始的地方。当您第一次坐在机械臂前时,第一个问题更加直接:
如何正确连接机器人、摄像头和平台,以便开始收集有用的示范?
这就是本文的重点。
下面的流程遵循应用程序指南中 SO-101 设置的远程操作路径:创建项目、设置机械臂、添加摄像头、定义环境,然后收集示范数据。
1、启动 Physical AI Studio
在接触校准或远程操作之前,首要任务是让应用程序运行起来。
Physical AI Studio 提供了两种便捷的入门方式。要快速运行完整应用程序,您可以按照应用程序 README 中推荐的基于 Docker 的设置进行操作。如果您更喜欢更接近代码库,也可以使用本机开发流程,该流程使用 uv 运行后端,使用 Node.js 运行前端。用户指南提供了更多关于硬件需求的详细信息,包括如何在具有内置 GPU 加速的 Intel® Core™ Ultra 系统上或在具有独立 Intel® Arc™ 图形的平台上运行 Physical AI Studio——使用相同的总体设置体验。
如果您想要最快的应用程序启动路径,请从 Docker 开始:
git clone https://github.com/open-edge-platform/physical-ai-studio.git
cd physical-ai-studio/application/docker
cp .env.example .env
docker compose --profile xpu up
可用的配置文件选项有 — profile xpu、— profile cuda 和 — profile cpu。启动后,应用程序在 Docker 流程中运行在 http://localhost:7860。
如果您更喜欢以本机开发模式运行,必须先设置后端,然后启动用户界面前端:
cd application/backend
uv sync --extra xpu # or --extra cpu / --extra cuda
./run.sh
Then, in another terminal, bring up the UI:
cd application/ui
nvm use
npm install
npm run build:api:download
npm run build:api
npm run start
在此本机设置中,后端运行在 http://localhost:7860,UI 运行在 http://localhost:3000。
这听起来可能像是一个基本的第一步,但它比看起来更重要。Physical AI Studio 的主要优势之一是它为早期机器人管道提供了单一的应用程序工作流。您无需在不相关的脚本和实用程序之间跳转,而是从一个地方开始并向前推进。这使其他一切都变得更容易。
2、在接触机器人之前创建项目
应用程序运行后,创建一个项目。
Physical AI Studio 将机器人问题分组到项目中,每个项目包含特定问题的数据集和模型。这是一个小的设计选择,但它是正确的选择。它迫使您首先定义任务边界,而不是让示范从第一天开始分散到临时文件夹中。
在实践中,您的项目可能代表一个桌面拾取和放置任务、一个料箱转移工作流或一个简单的分拣场景。重要的是,项目成为后续所有内容的容器:环境、记录的示范以及稍后训练的策略。
这从一开始就在工作流中提供了一个清晰的重心。
3、设置机械臂
对于我们开发者来说,实践动手操作,这才是真正的开始。
不是数据集收集。 不是训练。 不是基准测试。
第一步是在平台内识别、校准和验证机械臂。
应用程序指南从机器人设置开始是有原因的。在记录数据集和训练模型之前,您需要设置环境,而这个环境由机械臂和摄像头组成。对于 SO-101 示例,推荐的顺序是:添加从臂、分配电机 ID、校准臂、验证运动、保存机器人,然后对 SO-101 主臂重复此过程。
3.1 添加从臂
应用程序流程从从臂开始。指南指导您命名机器人、选择机器人类型为 SO101 Follower、选择正确的串行设备,并在不确定哪个串行 ID 与哪个机器人匹配时使用识别功能。识别操作会打开和关闭夹爪以帮助您确认设备。
这个小的识别功能值得特别指出。在实际的硬件工作流中,即使是对连接设备的微小歧义也会很快浪费时间。良好的入门体验应该减少这种摩擦,这是一个实际的例子。
3.2 分配电机 ID
对于 SO-101,下一步是电机设置。
SO101 菊花链连接伺服器,每个伺服器需要一个分配的 ID,这样系统就知道它属于哪个关节。模式很简单:将一个特定的伺服器连接到控制器板、分配 ID、对每个电机重复此操作、重新连接所有电机,然后在继续之前验证电机。
这不是机器人 AI 中光鲜亮丽的部分,但它是最重要的部分之一。如果您在博客中跳过电机映射,这篇文章就变成了励志性的而非可操作的。Physical AI Studio 中展示的是真实的工作流,而不仅仅是经过美化的部分。
3.3 校准臂
校准是硬件设置变得可信的地方。
SO-101 校准流程表明机器人需要知道根位置和伺服范围。UI 引导的步骤是:将臂移动到其运动范围显示的中心、应用归位偏移、将每个关节移动到其完整范围,然后完成记录。
这是物理机器人和数字表示开始对齐的时刻。这种对齐不仅仅对设置重要。在机器人模仿学习中,今天糟糕的校准会导致明天糟糕的数据。
3.4 继续之前进行验证
校准后,仔细验证运动。
用户被要求将机器人的关节移动到完整范围,并确认 UI 显示相同的运动。如果显示与物理运动不匹配,用户需要在保存机器人之前返回校准。之后,应对 SO101 主臂重复相同的过程。
这个验证步骤在本文中值得特别强调,因为它不仅仅是一个检查清单项目。
它是整个管道中的第一个质量门。
糟糕的校准会话不会孤立存在。它会向前泄漏到远程操作质量、示范质量,最终影响模型质量。
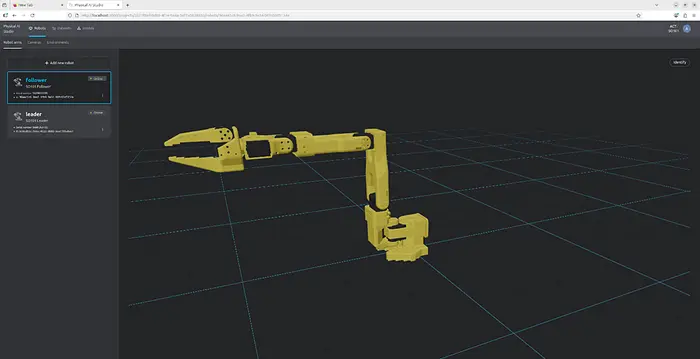
4、添加稍后将依赖的摄像头
机械臂设置完成后,下一步是感知。
应用程序指南中的摄像头设置很简单:添加新的 USB 摄像头、命名、选择设备、选择分辨率和 FPS、预览源,然后添加摄像头。指南说要为机器人所需的所有视点重复此操作。
这里重要的不是追求一个"完美"的通用摄像头布局。重要的是选择在稍后训练和调试策略时仍然有意义的视图。对于许多桌面操作任务,这通常意味着用于任务上下文的更宽场景视图、用于运动理解的另一个角度,有时在精细操作重要时使用更局部的视图。
在我们的案例中,我们在场景设置中使用了三个 USB 摄像头。第一个摄像头从顶部安装,提供桌面工作区的全局视图;第二个安装在从臂上,以捕获物体和夹爪交互的特写视图;第三个放置在桌面上,以观察拾取和放置过程中臂相对于桌面的高度,这有助于捕获仅从顶部视图难以看到的运动细节。因此,摄像头设置不仅仅是一个辅助步骤。它已经是模型设计的一部分。
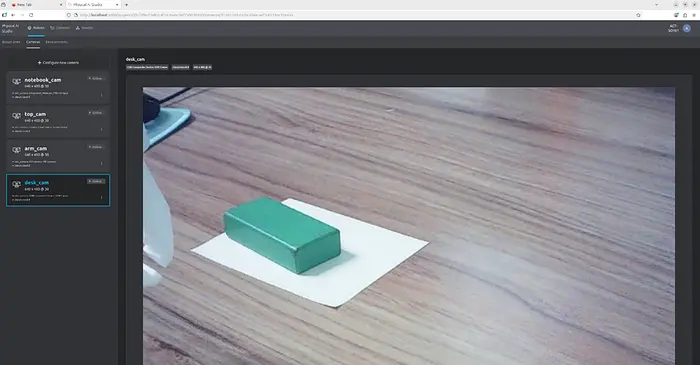
5、定义将一切绑定在一起的环境
到目前为止,您已经配置了单独的部分: 从臂、主臂和摄像头流。
现在您需要将它们绑定到一个工作设置中。
这就是环境的作用。
环境定义了机器人和摄像头,并且它在数据集中用于确定模型的输入特征。工作流是:配置新环境、选择从臂、选择主臂、添加摄像头、预览设置、实时验证机器人,然后添加环境。
环境成为数据模型契约的一部分。换句话说,您现在定义环境的方式直接影响数据集包含的内容以及稍后期望模型作为输入的内容。
这也是系统停止感觉抽象的地方。在此之前,您正在配置组件。在这里,您正在定义数据收集将依赖的实际远程操作包。
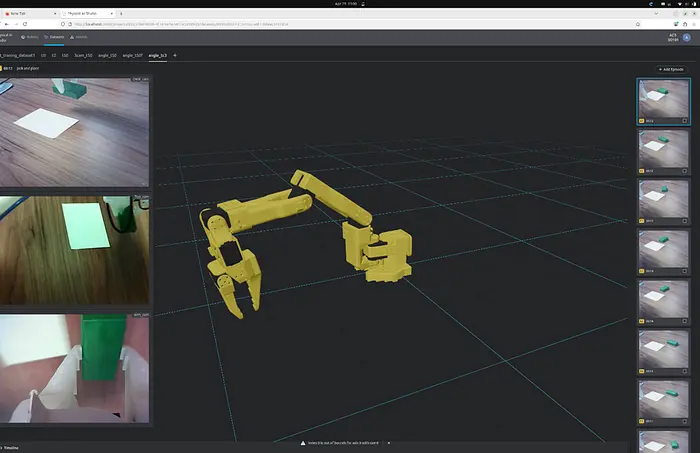
6、记录第一个示范片段
现在才是收集数据的时候。
这个顺序很重要。
一旦应用程序启动、机器人校准完毕、摄像头在线、环境定义完成,数据收集就成为自然的下一步。
应用程序将其分为三个部分:创建新数据集并选择环境、开始记录任务,然后开始一个片段。文档还指出,所选环境决定数据集特征,并且只要共享相同特征,就可以使用多个环境。对于每个片段,记录的流程是验证主臂运动、检查场景照明、重置环境、开始片段、执行运动,然后接受或丢弃该次拍摄。
干净的第一个数据集是通过逐个判断的示范建立的。
即使在这个第一次会话中,也有一条规则值得记住:
不要只记录成功。记录变化。
仓库文档没有明确说明这句话,但它是任何依赖于从真实场景收集的示范的模仿学习工作流的实际含义。如果每个片段都显示物体处于相同位置、在相同光照下、并且具有相同的运动模式,策略可能学得很快但保持脆弱。方向、位置和小场景条件的变化是给模型泛化机会的关键。这是从工作流中得出的推论,而不是引用的仓库声明。
7、结束语
这是我们想在第一篇文章中分享的内容,因为它遵循了开发者进入机器人 AI 的实际路径。
您不是从模型导出开始。 您不是从基准测试开始。 您也不是从数据集收集作为抽象概念开始。
您从启动应用程序、创建项目、校准机器人、验证系统、添加摄像头、定义环境开始,然后记录您的第一个被接受的示范。
这就是将机器人框架从有趣的仓库转变为您可以真正使用的东西的顺序。
一旦您有了校准的主臂和从臂、验证的摄像头流、定义的环境和第一批被接受的片段,下一个问题就变成了正确的问题:
原文链接:From Zero to Robot Data: Build Your First Imitation Learning Pipeline with Physical AI Studio
汇智网翻译整理,转载请标明出处
