RAG 2026:检索增强生成
RAG为模型提供特定查询所需的特定上下文,而不是强迫它仅仅依赖从训练中记住的内容。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
基础模型很强大,但它们仍然会犯一种非常人类化的错误:"在信息不足时自信地回答"。也就是我们所说的"幻觉"*。
这正是 RAG 解决的核心问题。
首先,先澄清一点:检索增强生成(RAG)不是魔法,也就是说它不会让一个弱模型变得"聪明",它只是做了一些实际的事情。
它为模型提供特定查询所需的特定上下文,而不是强迫它仅仅依赖从训练中记住的内容。这个简单的转变改变了很多事情。响应变得更加详细。幻觉可以完全消除。用户特定和公司特定的数据变得更加可用。突然之间,一个通用模型开始表现得好像它真的了解你的业务一样。
对我来说,理解 RAG 最清晰的方式是:它基本上就像为基础模型做特征工程。经典 ML 系统需要精心构建的特征才能做出好的预测。现代语言模型需要精心构建的上下文才能生成好的答案。
这听起来不如"AI 代理"或"长上下文推理"那么光鲜。但在生产环境中,它通常是演示和人们可以信任和购买的系统之间的区别。
1、RAG 实际上是什么
一个 RAG 系统有两个主要部分。
第一个是检索器,它找到与查询相关的信息。第二个是生成器,它使用检索到的信息来产生最终答案。
外部记忆源几乎可以是任何东西:内部文档、会议记录、产品手册、之前的聊天历史、SQL 数据库,或者公共互联网。用户提问,检索器拉取最相关的上下文,模型使用该上下文来回答。
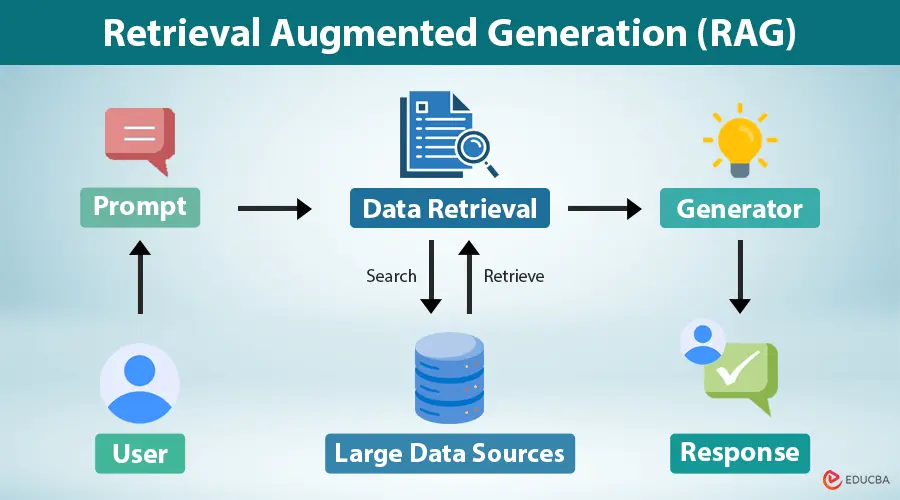
模型本身只有其权重和当前的提示词。RAG 系统让它能够访问新鲜的、针对查询的知识。这很重要,因为大多数实际应用程序之所以失败,不是因为模型缺乏通用智能,而是因为模型没有在正确的时刻拥有正确的事实。
2、为什么在长上下文时代 RAG 仍然重要
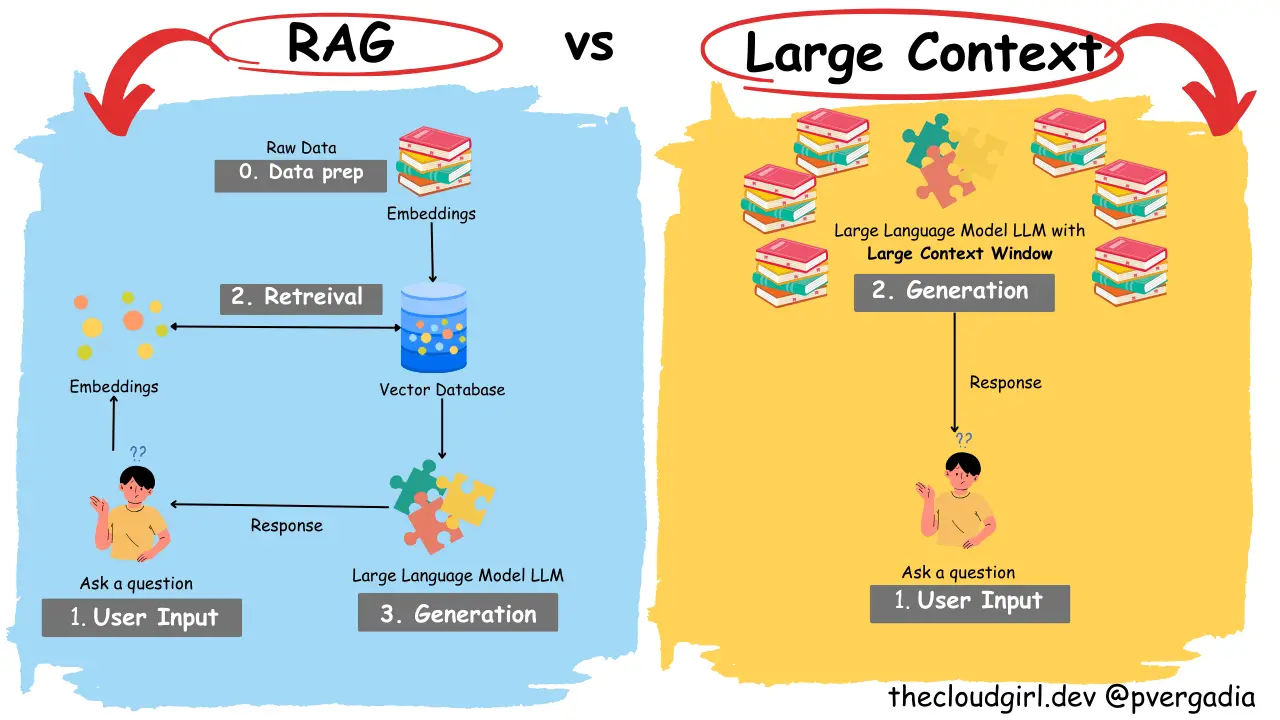
很多人假设更大的上下文窗口最终会使 RAG 变得不必要……这是不对的。
首先,可用数据的增长速度比你合理地塞入提示词的上下文数量增长得更快。即使模型在技术上可以接受很长的上下文,也不意味着你应该总是给它一个。
其次,模型并不总是能很好地使用长上下文。更多的 token 并不自动意味着更多的信号。在现实世界中,更长的提示词可能使模型关注错误的段落,增加延迟,并推高成本。每个额外的 token 都有财务成本和注意力成本。
第三,许多应用程序需要针对不同用户和不同查询提供不同的上下文。如果一个用户询问打印机规格,另一个用户询问退款政策,他们不应该都拖着同一个巨大的上下文块。RAG 让你可以为每个查询构建上下文,这样更清晰、更便宜。
所以真正的竞争不是"RAG 对比长上下文",而是"相关上下文对比臃肿上下文"。而相关上下文的胜率比人们预期的要高。
3、检索器的重要性
当人们谈论 RAG 时,他们通常只关注模型。但检索器往往是真正的瓶颈。
如果检索器找到的上下文很弱,生成器就被困住了。即使是一个强大的模型,如果给它的是错误的文档,也无法很好地回答。
有两种主要的信息检索方式。

3.1 基于词项的检索
这是传统方法。搜索基于将查询中的词项与文档中的词项进行匹配。 TF-IDF、BM25 和倒排索引等系统就属于这一类。
这种方法快速、成熟、便宜,即使在今天也非常有用。它在精确关键词很重要时尤其强大。产品名称、错误代码、ID 和奇怪的字符串是典型的例子。如果用户搜索类似这样的内容:
PRODUCTID (99),
你真的不希望你的检索器将其平滑化到某种模糊的语义邻域中。
基于词项的检索并不花哨,但它确实有效。这就是为什么 Elasticsearch 这样的系统变得如此占主导地位……
3.2 基于嵌入的检索
这是语义版本。你不再匹配精确的词项,而是将文档和查询转换为向量嵌入,并在嵌入空间中检索最近的邻居。
当措辞改变但含义保持不变时,这要好得多。 用户可能会问"我无法登录",而文档的标题是"如何重置你的密码"。词项匹配可能会错过这一点。嵌入通常能捕捉到它。
但是嵌入也可能模糊重要的关键词……这就是权衡。它们更好地理解了底层含义,但并不总是擅长精确字符串匹配。
这就是为什么许多强大的生产 RAG 系统最终成为混合系统。它们结合了基于词项和基于嵌入的检索,而不是假装一种方法能解决所有问题。
3.3 稀疏检索与稠密检索
另一个有用的区分是稀疏表示与稠密表示。
基于词项的方法通常是稀疏的。向量中的大多数条目为零,只有出现的词项才重要。基于嵌入的方法通常是稠密的,每个维度都携带某种值。
稠密检索更有表现力,但稀疏检索可以更容易解释、运行更便宜,并且对于精确匹配更可靠。这是那种无聊的答案往往是正确答案的领域之一:使用与你的失败模式相匹配的表示方法。

如果你的用户经常通过特定型号进行搜索,仅靠稠密检索可能不够。如果他们问的是模糊的语义问题,纯关键词搜索可能会显得脆弱。
4、RAG 系统应该像检索系统一样被评估
我经常看到一个错误:只评估最终答案而忽略检索步骤。到那时,已经太晚了。
检索器有自己的指标,而且这些指标很重要。两个最有用的是:
- 上下文精确率:在检索到的文档中,有多少百分比实际上是相关的?
- 上下文召回率:在所有存在的相关文档中,你检索到了多少百分比?
这两个指标在不同方向上拉扯。检索器可以通过返回一大堆文档来获得高召回率,但精确率会下降,模型必须在噪音中筛选。或者它可以非常精确,但完全遗漏关键证据。
如果你的 RAG 系统感觉不稳定,不要只怪模型。有时答案质量问题实际上是检索质量问题的伪装。
5、让 RAG 更好的3 个优化策略
一旦基本检索器工作正常,三个改进往往很重要。
5.1 查询重写
用户问的问题很混乱。搜索系统更喜欢干净的查询。
如果用户在之前问过关于 John Doe 的问题后,接着问"How about Emily Doe?",检索器不应该字面地搜索这个后续问题。它应该将其重写为实际的查询: "Emily Doe 上次从我们这里购买东西是什么时候?"
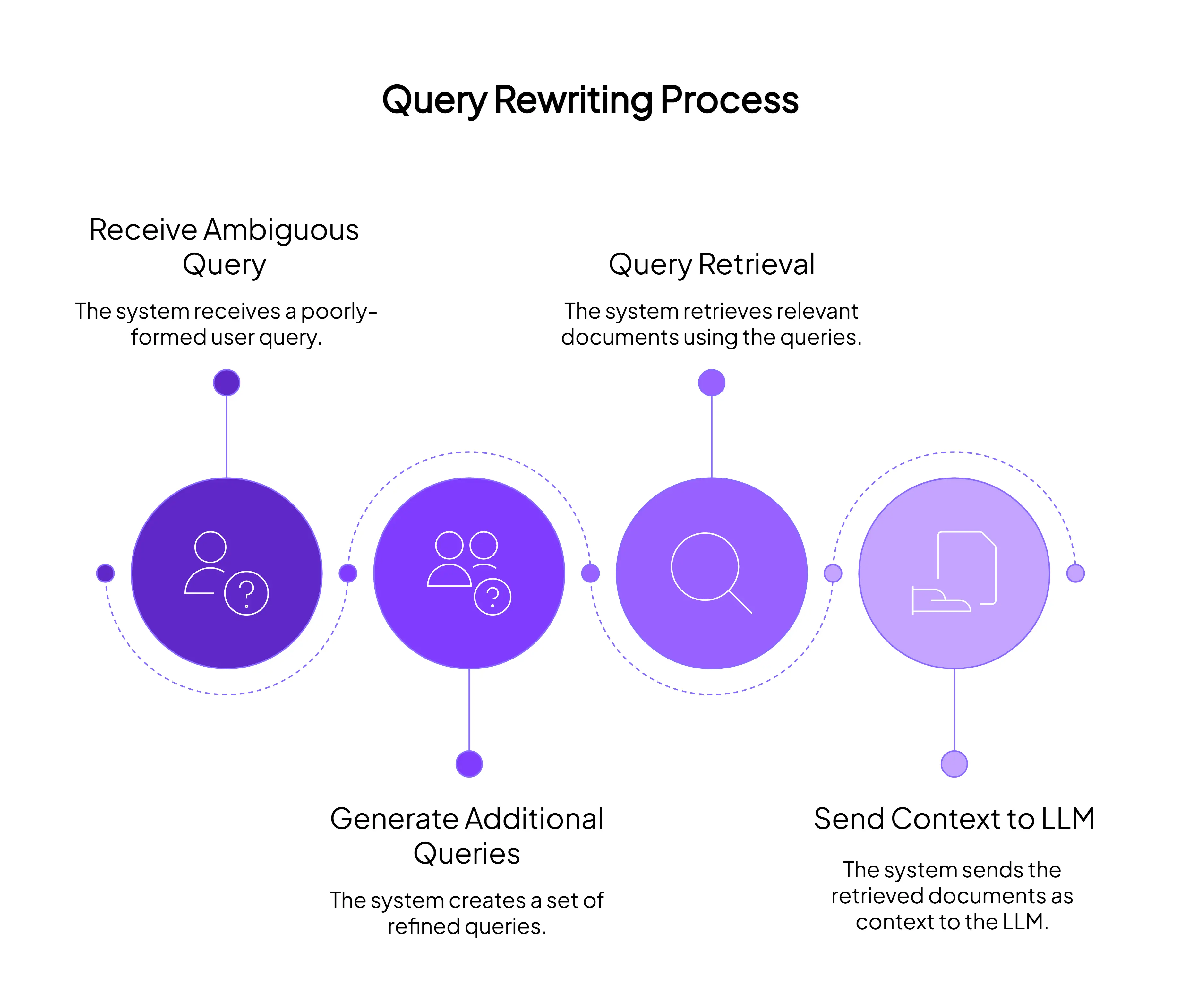
这听起来很简单,但它的影响非常大。很多检索错误来自于用户输入是对话式的,而搜索在显式意图上效果最好。
5.2 重排序
一个便宜的检索器可以获取一个候选集,然后一个更精确但更昂贵的模型可以对这些候选进行重新排序。这通常是 RAG 中最好的权衡之一。
你不需要昂贵的模型查看所有内容。你只需要它更好地排序候选列表。
当你想在将块传递给最终模型之前减少块的数量时,重排序特别有用。
5.3 上下文检索
有时候一个块很难被检索到,因为单独来看它缺乏足够的上下文。一个有用的技巧是用元数据来增强每个块:标题、摘要、标签、实体、关键词,甚至它可以回答的示例问题。
这使得检索变得更加强大。
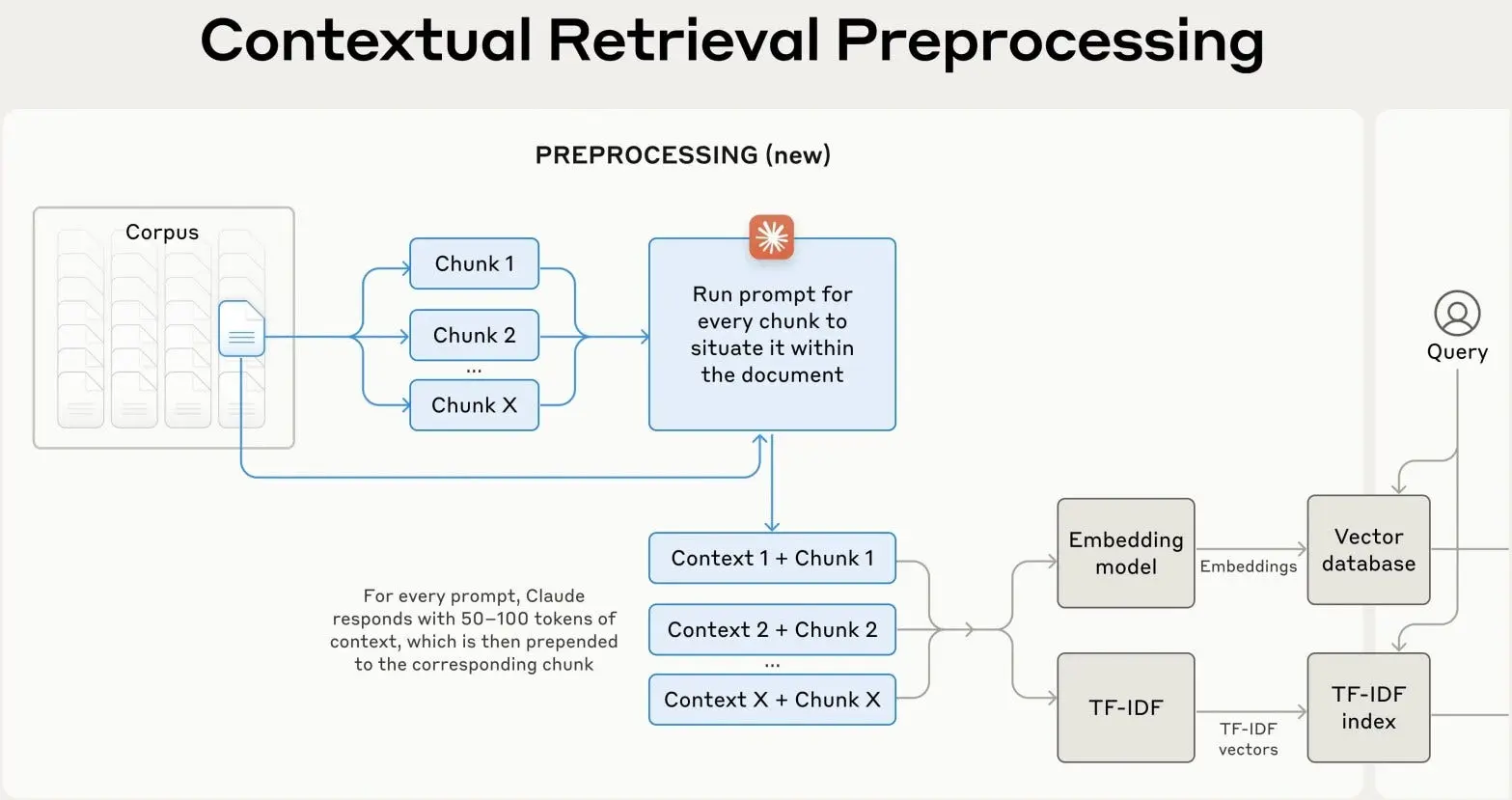
一篇关于密码重置的支持文章可以用相关表述来增强,比如"我忘记了密码"、"我无法登录"或"帮助,我无法访问我的账户"。突然之间,检索器有了多种方式来找到同一个底层答案。
这是那种你看到后就觉得很明显的想法之一,但它可以在实质上改善召回率。
6、SQL 的 RAG
很多 RAG 的讨论假设外部记忆意味着文本文档。这太狭隘了。RAG 也可以处理表格、图像和其他结构化数据源。
一个很好的例子是 text-to-SQL。假设用户问,"过去7天 Fruity Feddys 卖出了多少件?"那个答案不是在某个段落中。它存在于一个 SQL 表中。
在这种情况下,工作流程发生了变化:
- 将自然语言问题翻译成 SQL。
- 执行 SQL 查询。
- 将结果输入生成器并产生最终答案。
这仍然是 RAG。模型在回答之前仍然通过外部上下文来增强自己。区别在于上下文来自数据库查询而不是文档检索。
这很重要,因为许多真实的业务问题是表格形式的。如果你对 RAG 的心理模型是"PDF 聊天机器人",你将错失很多东西。
原文链接:Retrieval Augmented Generation (RAGs)
汇智网翻译整理,转载请标明出处
