RAG 只是权宜之计
当你调整分块大小时,你并不是在修复 bug。你只是在修补一个从一开始就不存在的反馈回路。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
在我第一个生产级 RAG 系统上线三个月后,我在晚上 11 点收到了告警。
一个企业客户的聊天机器人检索到了一条完全针对不同员工层级的 HR 政策。语言足够相似,以至于检索器认为匹配。实际上并没有。我花了两天时间调优,更小的分块、更大的重叠、不同的嵌入模型。问题不断发生。
那时我意识到,我并不是在修复一个 bug。缺陷存在于架构本身,位于任何分块大小都无法触及的深处。
直到我接触到苹果的 CLaRa 和一种名为 Golden Retriever RAG 的技术,我才终于恍然大悟。一旦你看清这一点,就无法视而不见。继续阅读,了解这个缺陷究竟是什么,为什么每个流行的修复方案都只是掩盖它,以及 CLaRa 究竟做了什么不同的事情。
1、为什么 LLM 需要 RAG?(压缩问题)
要理解 RAG 为什么有缺陷,你需要理解 LLM 究竟是什么。大多数解释跳过这一部分,直接跳到流程。那是一个错误。
大语言模型不是数据库。它们不存储事实。它们没有写着"法国的首都是巴黎"的查找表。
它们实际做的是压缩。
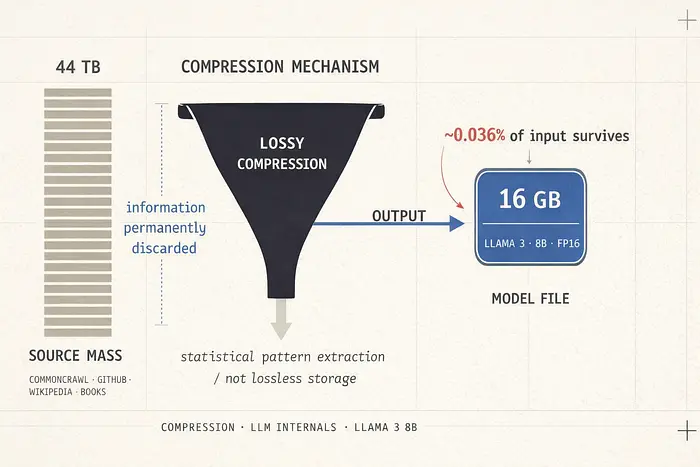
以 LLaMA 3 8B 为例。它在大约 15 万亿个 token 上训练,这些 token 代表从 CommonCrawl、GitHub、维基百科、书籍和类似来源获取的约 44 TB 的互联网文本。最终模型文件在 FP16 精度下?大约 16 GB。
花一秒想想这个比例。你把 44 TB 的人类知识压缩到 16 GB。这不是无损操作。你用 zip 文件做不到这一点。正在发生的是有损压缩,类似于将 JPEG 压缩到最大。模型不会记住事实。它学习统计模式。它学会在"法国的首都是"之后,token "巴黎"有很高的概率紧随其后。全是统计学。
这在生成流畅、上下文恰当的文本时效果很好。当你需要具体的、事实性的回忆时,它就崩溃了。一个精确的日期。一个合同条款。你公司当前的定价表。信息要么太罕见,无法在压缩中完整保留,要么在训练数据收集时根本不存在。
这就是 RAG 被发明来解决的问题。
2、幻觉不是 Bug。它们是预期输出
幻觉不是要修复的故障。它们是有损压缩器被要求重建它不再拥有的数据时的可预测结果。
把一张照片压缩到原大小的 5%,然后放大。图像不会崩溃。它会编造。它用从未存在过的、看似合理的模式填充缺失的像素。块状、模糊、充满伪影。LLM 产生幻觉正是如此。不是坏了。只是压缩系统被迫填补空白时的正常表现。
对于创意写作,这没问题。对于企业文档、患者记录或法律合同,这是一个严重问题。这就是检索增强生成存在的原因:在查询时将确切的文本交给模型,而不是让它从记忆中重建。

3、什么是标准 RAG,为什么它大部分时候能用?
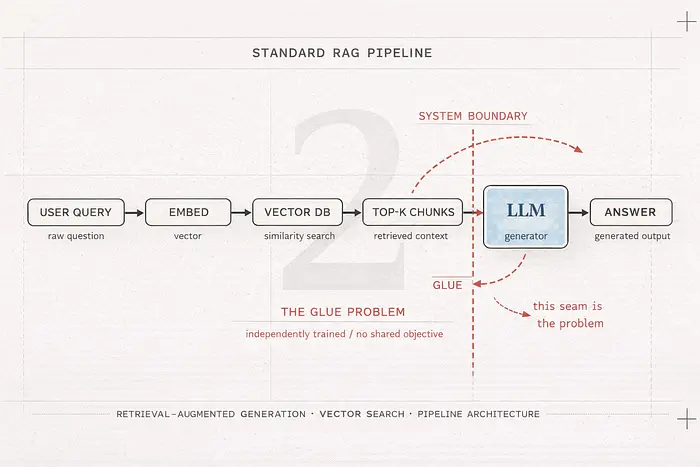
检索增强生成将 LLM 视为开卷考试中的学生。不是从记忆中回忆,而是在查询时将相关页面交给它。
流程:
- 用户提交查询
- 查询被嵌入成向量
- 向量数据库找到相似的文档分块
- 匹配的分块被粘贴到 LLM 的上下文窗口中
- LLM 仅基于该上下文回答
它有效。新文档无需重新训练即可立即使用。这确实很有用。
但 RAG 是一个权宜之计。你将两个基于完全不同原则构建的系统粘合在一起:一个做向量空间数学的检索器和一个做概率 token 预测的生成器。它们不是为彼此设计的。这种不匹配有一个大多数教程从不费心解释的后果。
4、RAG 的真正问题是什么?(梯度墙)
这是实际的缺陷。分块调优无法触及的那个。
现代深度学习之所以有效,是因为反向传播。每当神经网络犯错时,损失函数会计算输出有多错。该误差信号通过网络每一层向后传播,使用链式法则计算每个权重对错误的贡献程度。然后相应地调整每个权重。
这个过程只有在链中的每一步都是可微的时才有效:平滑、连续,数学上足够良好,梯度可以流过。
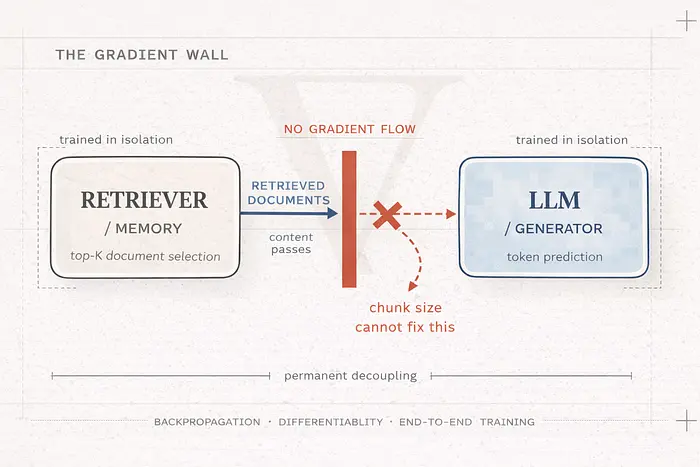
现在看看 RAG 流程中检索时会发生什么。
检索器根据传入的查询为数据库中的每个文档打分。你可能有 10 万个文档。每个都获得一个相似度分数。然后系统选择top K 结果。K 等于 5,或 10,或你配置的任何值。就是这样。高于截止线的文档进入。其他一切都被丢弃。
那个"选择 top K"的步骤是一个硬性的、离散的选择。文档要么在,要么不在。没有平滑过渡。没有分数文档。没有梯度可以流过的连续函数。
所以当检索器拉取不相关的文档,LLM 产生错误答案时,那个错误会发生什么?LLM 没有机制将错误信号发送回检索器。数学根本不允许。梯度在两个系统的边界处消亡。
检索器永远不知道它犯了错误。下次相同的查询进来时,它犯同样的错误。LLM 不能说"那个文档错了,调整你的权重"。没有调整。没有学习。两个组件永久解耦,孤立训练,这种隔离被烘焙进架构中。
这就是核心问题。不是你的分块大小。不是你的嵌入模型。不是你的相似度阈值。
梯度无法流动。系统无法端到端学习。其他一切都是由此产生的。
5、GraphRAG 真的解决了检索问题吗?
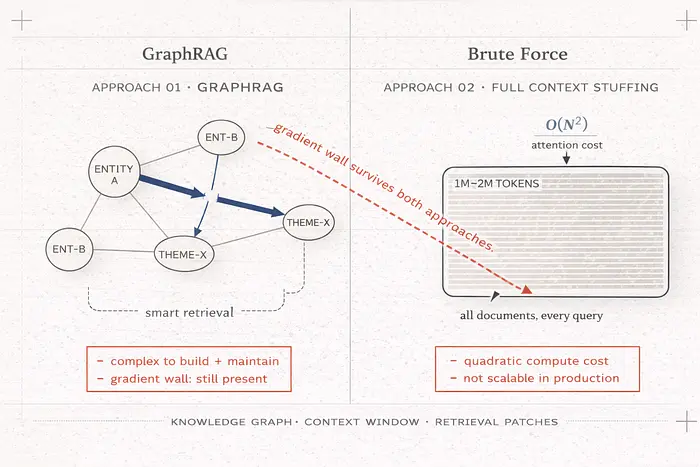
GraphRAG 用知识图谱取代平面向量搜索。不是找到语义相似的分块,而是构建实体及其关系的图谱,然后遍历该图谱找到相关概念。
对于关于事物之间关系的问题,这确实更好。"哪些公司与 2023 年离职的高管有关联?"是向量搜索处理得不好的问题。知识图谱处理得很干净。
但 GraphRAG 构建复杂,维护昂贵,而且完全没有触及梯度问题。检索器更聪明,是的。它仍然无法从生成器接收反馈。解耦完全 intact。
6、把所有内容都放进上下文窗口有用吗?
这种方法完全跳过检索。像 Gemini 2.0 Flash 这样的模型支持 100 万 token 的上下文窗口;Gemini 2.0 Pro 达到 200 万。论点:将每个查询的整个文档语料库转储到上下文中,让模型自己解决。没有检索意味着没有检索错误。
对于有界文档集和重推理任务,这确实有效。模型看到一切。
问题是物理。Transformer 注意力是二次的:
计算成本 = O(N²)
其中 N 是上下文中的 token 数量。上下文长度翻倍,所需计算量翻四倍。在 100 万 token 时,这很昂贵。在 200 万 token 时,为每个用户查询在生产中运行此推理在财务上是残酷的。你无法将其扩展到真实的查询量和真实的成本。
7、修复流程:什么是 Golden Retriever RAG?
Golden Retriever RAG 是一个流程层面的修复,而且确实很巧妙。想法是在查询到达检索器之前让它变得更智能。
标准流程将原始用户查询直接发送到向量搜索。Golden Retriever RAG 首先插入一个由 LLM 驱动的反思步骤:
- LLM 读取原始用户查询
- 它识别行话、扩展缩写、添加上下文细节
- 它将查询重写为明确的、适合搜索的版本
- 那个扩展的查询代替原始查询发送到检索器
如果有人问"我们 Q3 ARR 与计划的差异是多少",模型首先将其扩展为类似"实际年度经常性收入与财年第三季度计划收入目标之间的差异是多少"的内容。检索器用那个扩展的查询找到正确文档分块的机会大大增加。
检索准确性提高。这部分是真实的。
但这里是诚实的评估。你为每个查询添加了一个额外的 LLM 调用,这增加了整个流程的延迟。基本架构没有改变。检索器仍然接收更好的输入,而不是从反馈中学习。你在治疗症状,而不是原因。
8、更好地修复流程
Instructed Retriever 做了什么?
Databricks 的 Instructed Retriever,于 2026 年 1 月发布,是一个更雄心勃勃的流程层面修复。检索器获得三项升级能力:
- 查询分解:复杂的多部分问题在进入数据库之前被分解成更简单的、可独立搜索的组件
- 上下文相关性:不是纯粹的向量重叠,检索器推理实际意图和含义,而不仅仅是关键词接近度
- 元数据推理:当用户问"去年的销售额"时,系统将其转换为具体的过滤器如
date >= 2025-01-01,而不是对短语"去年"进行语义搜索
Databricks 的 StaRK-Instruct 基准测试结果显示,相比标准 RAG,召回率提升 35% 到 50%。在需要精确遵循指令的更难的企业问答任务上,他们展示了高达 70% 的改进。
这些数字是真实的。这是一个真正有用的系统。
但它仍然是一个补丁。检索器没有从生成器的结果中学习。它只是被预先赋予了更好的规则。梯度墙仍然存在。
8、修复架构
什么是苹果的 CLaRa,为什么它真的不同?
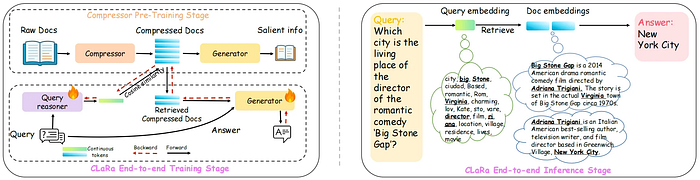
CLaRa(Continuous Latent Reasoning),由苹果和爱丁堡大学的研究人员于 2025 年 12 月发表,是第一个直接攻击梯度墙的方法。
标准 RAG 获取你的文档,将其分解为文本分块,嵌入这些分块,然后通过向量相似度检索。CLaRa 完全抛弃了整个工作流程。
相反,它引入了记忆 token:纯文档内容的压缩表示。不是文本分块。不是文本的嵌入。少量连续的、学习的 token,以 16 倍到 128 倍的压缩率编码文档的语义含义,剥离语法噪音、填充词和结构开销。
然后它引入了一个查询推理器。不是将你的查询与文档嵌入匹配,查询推理器首先生成一个假设的理想答案,然后搜索支持该假设的记忆 token。
这里是改变一切的部分:CLaRa 使用可微的 top-k 估计器执行检索。选择检索哪些记忆 token 不是一个硬性的离散步骤。它在数学上被做得足够平滑,梯度可以从答案生成步骤向后流过检索步骤,进入查询推理器本身。
检索器现在可以从生成器的错误中学习。端到端训练成为可能。两个系统之间的墙被拆除。
苹果在 Hugging Face 上发布了三个模型:CLaRa-7B-Base、CLaRa-7B-Instruct 和 CLaRa-7B-E2E。E2E 变体是用完整的可微检索循环训练的那个。
9、你今天实际应该用什么构建?
对于现在上线的生产系统,将 Instructed Retriever 方法与 Golden Retriever 查询扩展相结合。在初始检索后添加一个重排序器。将检索质量和生成质量作为独立指标监控,因为问题存在于不同的地方,答案质量的下降可能是检索失败,而不是 LLM 失败。
对于结构化文档领域,如金融、法律、医疗或监管,评估分层索引方法。如果你的文档有有意设计的结构(章节、小节、编号条款),向量分块正在主动破坏该结构。停止重建已经存在的东西。
原文链接: RAG Is a Hack. Here's Why It's Fundamentally Broken.
汇智网翻译整理,转载请标明出处
