机器人控制简明教程
本文将深入剖析机器人控制的基础知识,从高层规划讲起,逐步深入到运动物理原理以及支撑其运行的软件公式。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
控制理论的核心在于如何为机器设定目标并确保其最终实现目标。无论是机械臂组装汽车,还是无人机在森林中导航,控制都是连接机器人“思维”(规划软件)和“身体”(电机和执行器)的桥梁。
本文将深入剖析机器人控制的基础知识,从高层规划讲起,逐步深入到运动物理原理以及支撑其运行的软件公式。
1、控制基础
1.1 规划与控制层次结构
在机器人的车轮开始转动之前,必须发生一系列决策。可以将其视为一个指挥链,高层目标被分解为物理电信号。
1. 任务规划(输出:最终目标)
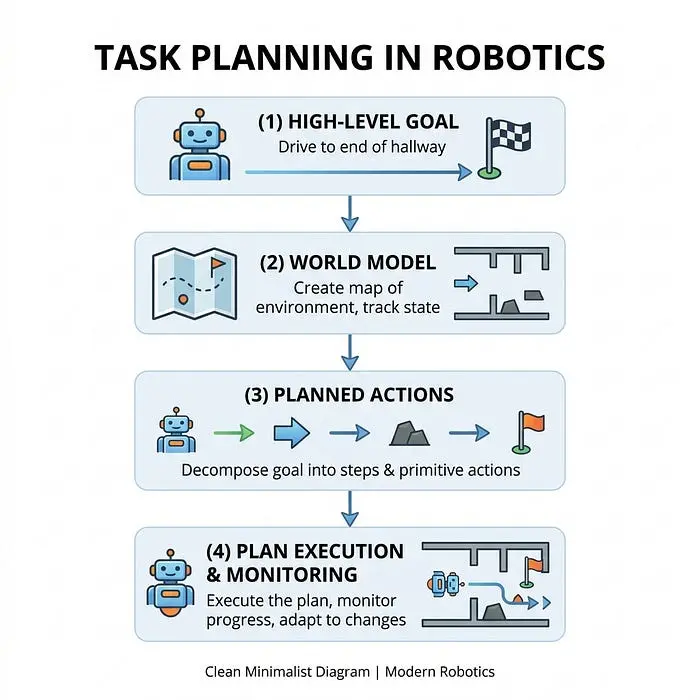
这是最终的、宏观的目标。
示例: "机器人,驶向走廊尽头。"
2. 轨迹规划(输出:机器人状态)
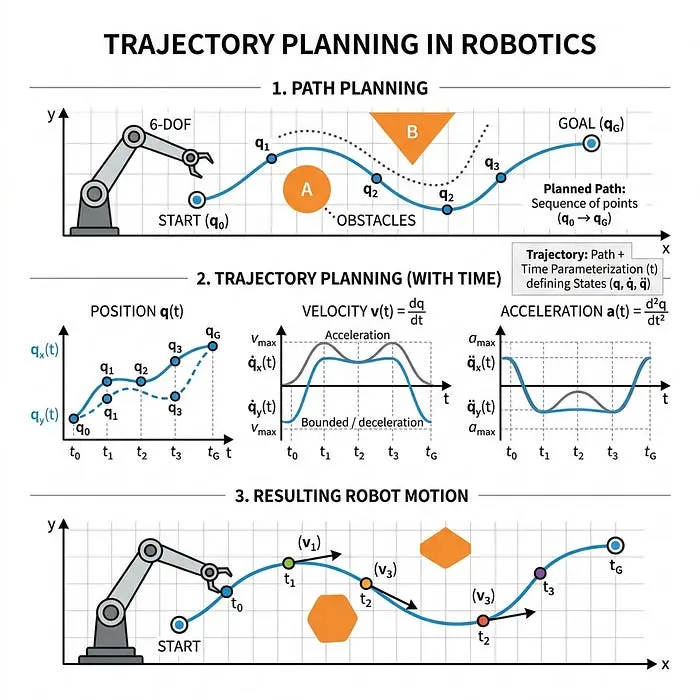
机器人计算出实现该目标所需的确切路径。
示例: "我需要直线行驶10米,然后停下。"
3. 控制(输出:速度)
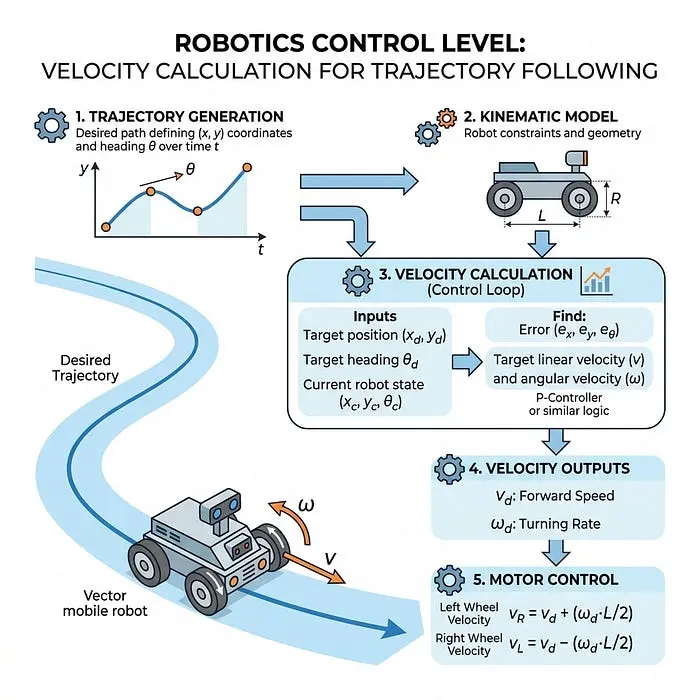
机器人计算需要多快的速度才能平稳地跟随该轨迹。
示例: "我的车轮需要以每秒2米的速度旋转。"
4. 执行器控制(输出:电压和电流)
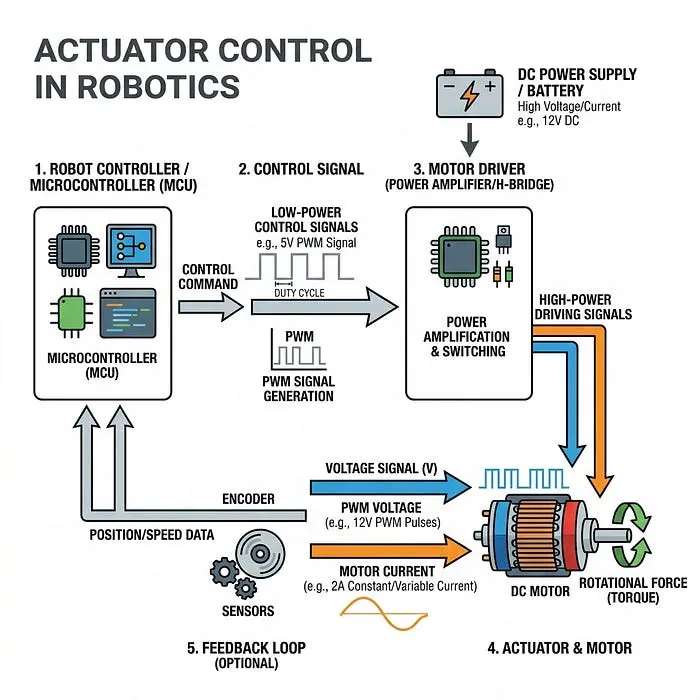
最后一步,物理硬件接收其电子命令。
示例: "向驱动电机发送精确的12伏电压。"
注意:虽然整个层次结构对于机器人正常工作是必要的,但机器人控制特别关注第3和第4层(控制和执行器控制)。第1和第2层(任务和轨迹规划)通常称为运动规划。在本篇博文中,我们将主要关注控制层。
1.2 开环与闭环控制器
一旦机器人知道需要做什么(例如以一定速度旋转车轮),它如何管理这个过程?有两种主要策略。
开环控制器
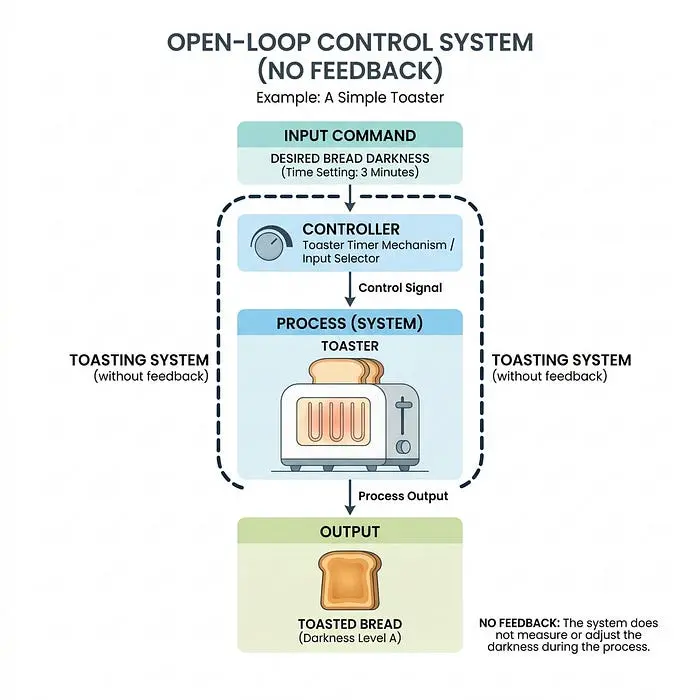
开环控制器告诉系统执行一个动作,但从不检查任务是否正确完成。
- 工作原理: 它直接向机器人硬件发送控制命令,产生实际的机器人状态,但没有验证步骤。
- 现实世界示例: 标准烤面包机。你按下杠杆,它加热设定的时间。它不检查你的面包是否完美金黄或烤焦;它只是盲目地运行计时器。
- 机器人示例: 告诉机器人蒙着眼睛直线行驶5秒。如果2秒后撞到盒子,它只会无助地继续旋转车轮,因为它不知道自己被困住了。
闭环控制器
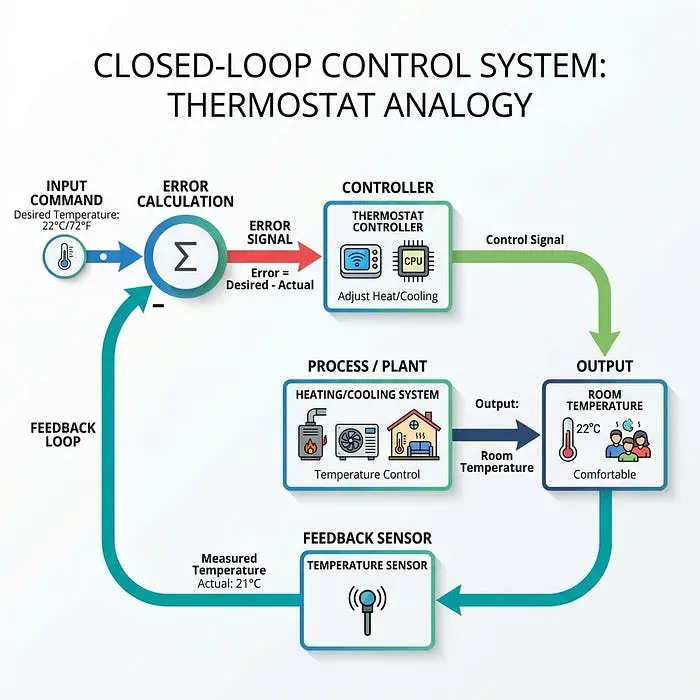
闭环控制器使用反馈来不断检查其进度并实时纠正错误。
- 工作原理: 它持续将机器人的实际状态与参考状态(目标)进行比较,以计算误差。控制器使用此反馈来调整其动作,并将系统驱动至零误差。
- 现实世界示例: 你家里的恒温器。你将其设置为70度(参考状态)。它持续测量实际室温(反馈)。如果变得太冷,恒温器会计算误差并打开暖气,直到误差为零。
- 机器人示例: 一个使用摄像头沿走廊行驶的机器人。如果它注意到自己向左墙漂移太近(误差),它会自动调整转向向右以纠正路径。
注意: 闭环控制是现代机器人能够处理不可预测现实世界的秘诀!
2、系统动力学
在告诉机器人如何移动之前,我们必须了解作用在它身上的物理力。每个机器人手臂、车轮或关节都有质量并经历摩擦。我们使用简化的物理模型——特别是弹簧和阻尼器——来预测机器人被推或拉时的行为。
2.1 质量-弹簧系统(“弹性”机器人)
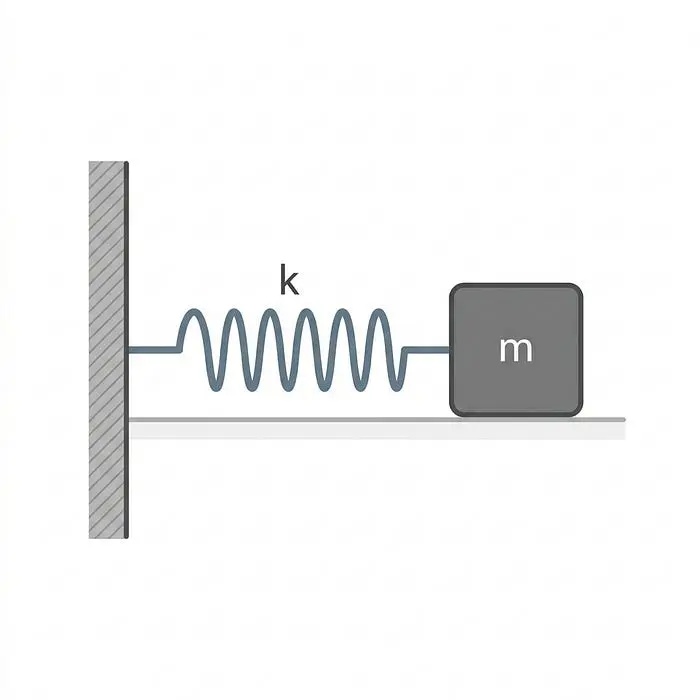
想象一个固体块(代表你机器人的质量,m)通过弹簧(代表系统的刚度,k)连接到墙壁。这是理解系统如何存储和释放能量的最简单模型。在机器人技术中,当我们处理柔性关节、顺应性材料,甚至机器人结构的弹性时,经常会遇到这种情况。
如果你拉动木块然后松开,弹簧会将其拉回。它超过静止点,弹簧再次将其拉回。在没有摩擦的完美世界中,木块将永远来回反弹。这种纯粹的振荡是我们需要理解的基本行为,然后才能尝试控制它。
- 物理学: 移动质量的力(m.dot{x})与弹簧的拉力(-kx)平衡。根据牛顿第二定律,力等于质量乘以加速度(F=ma,其中 a = dot{x})。弹簧力与位移成正比(F=-kx)。将它们等同起来,我们得到基本的运动方程:
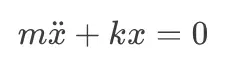
- 固有频率(omega): 这代表系统自然想要振动或反弹的速度。这是一个关键属性,因为如果我们命令机器人以该频率移动,我们可能会引起共振并导致剧烈、不可控的振荡。数学上,它由刚度与质量的比率决定:
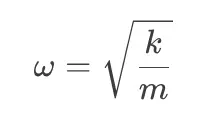
- 现实世界示例: 想象一辆完全损坏了减震器的汽车。如果你按下引擎盖,汽车会继续在其悬架弹簧上以其固有频率上下弹跳。在机器人技术中,一个重型机器人手臂安装在薄而柔性的支架上会表现出同样的弹性行为。
2.2 质量-弹簧-阻尼器系统(添加摩擦)
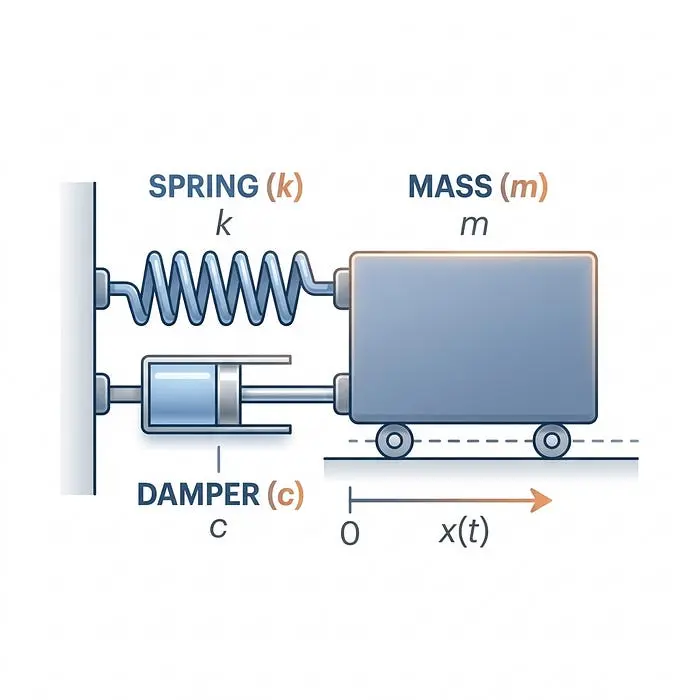
在现实中,机器人不会永远弹跳;摩擦和阻力会减慢它们的速度。我们将这种耗散能量的力数学表示为阻尼器(c)。阻尼器就像汽车中的减震器或在浓稠蜂蜜中移动的活塞——它抵抗运动。关键是,阻力与速度(dot{x})成正比:你试图移动得越快,它抵抗得越厉害。
当我们将质量、弹簧和阻尼器组合在一起时,我们就得到了机器人物理动力学的完整而现实的画面。这是用于设计防止机器人自身震动的控制器的标准模型。
力的平衡现在包括加速度、速度和位置,形成一个二阶常微分方程(ODE):
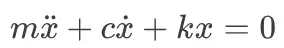
从这个方程中,我们推导出一个关键的无量纲变量来表征系统的行为:
阻尼比(zeta): 这个值告诉我们“反弹”会消退多快。它是实际阻尼与临界阻尼的比率。它决定了系统是振荡、缓慢爬行还是完美稳定。计算如下:
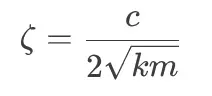
预测运动(四种响应)
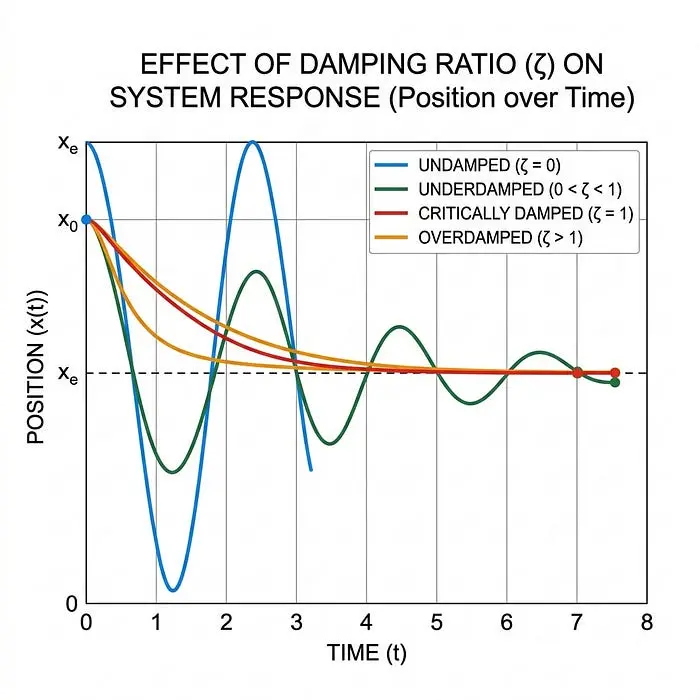
因为我们的系统由二阶常微分方程(ODE)建模,所以机器人随时间变化的运动(x(t))将始终属于四种不同类别之一,具体取决于阻尼比(zeta)。理解这些响应对于设计使机器人平稳安全移动的控制器至关重要。
- 无阻尼(zeta = 0): 完全没有摩擦或能量损失。机器人在一个完美的波中持续振荡(反弹)。在现实世界中,这是不可能的,但一些摩擦非常低的系统(如太空中的卫星)接近这种情况。在机器人技术中,我们通常希望避免这种情况,因为它意味着零控制。
- 欠阻尼(zeta < 1): 有一些摩擦。机器人超过目标,反弹几次(每次变小),最终停止。(就像一个摆动的落地钟摆锤慢慢静止下来)。在机器人技术中,如果优先考虑速度而不是精度,轻微的欠阻尼是可以接受的,但太多会导致不稳定。
- 临界阻尼(zeta = 1$): “金发姑娘”区域。机器人以物理上尽可能快的速度返回其静止点,没有超调或反弹。这是大多数机器人系统的理想状态,例如机器人手臂抓取物体,因为它确保了最大速度而没有因超调而导致碰撞的风险。
- 过阻尼(zeta > 1): 摩擦太大。机器人根本不反弹,但它非常迟钝,需要很长时间才能到达静止点。(就像一个带有非常紧的液压关闭器的沉重门,需要永远才能关闭)。虽然安全,但过阻尼系统通常对于实际机器人应用来说太慢了。
3、比例积分微分(PID)控制
如果第二章是关于理解机器人自然移动的物理学,那么第三章就是关于我们用来强制其按我们想要的方式移动的软件公式。
我们控制器的最终目标是计算一个控制信号 u(t),发送给机器人的电机。为此,我们首先计算误差 e(t),它只是我们希望机器人所在位置(设定点)与实际位置之间的差异:
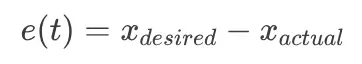
使用该误差,我们应用主连续时间PID控制方程:
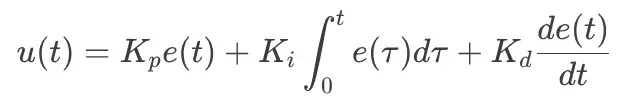
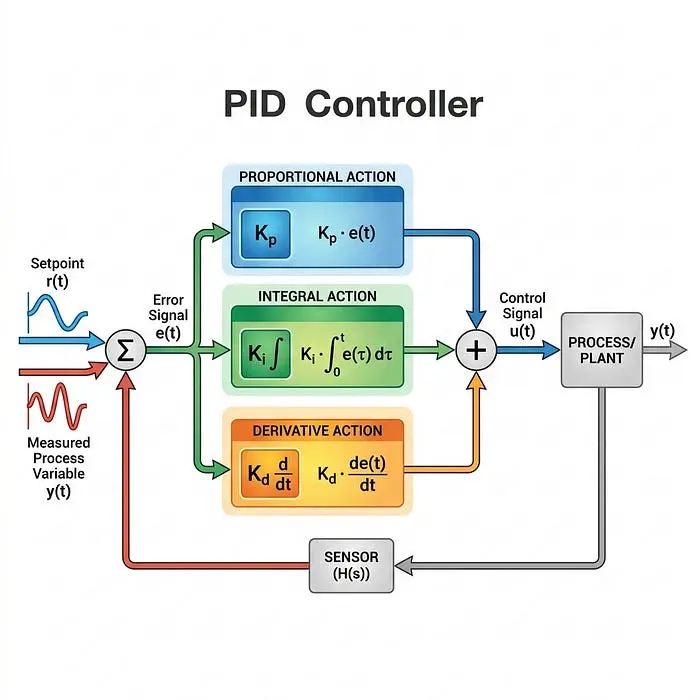
以下是每个部分的工作原理,使用将汽车完美停在停车标志处的类比:
3.1 比例(P)——“弹簧”
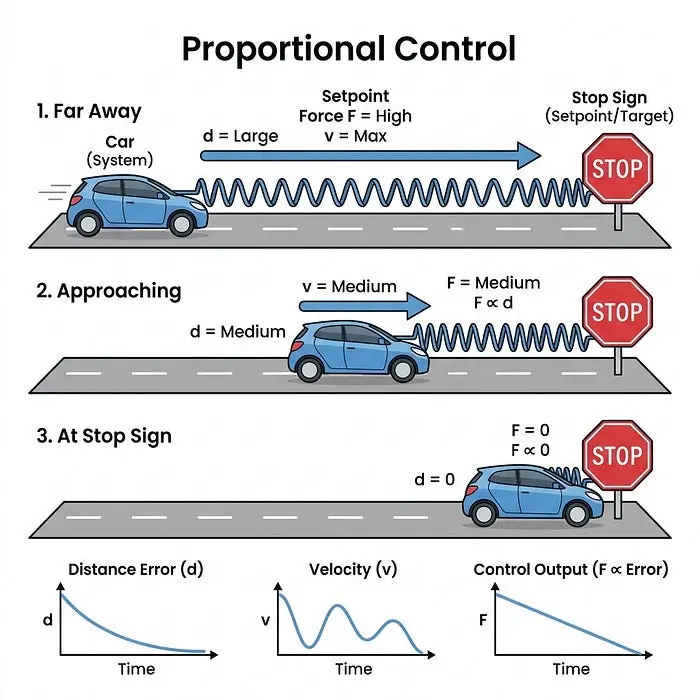
比例项查看你当前的误差。
- 概念: 你离目标越远,你就越用力推。当你接近时,你就放松。
- 在物理学中: 数学上它就像一根连接到目标的刚性弹簧。
- 汽车类比: 如果停车标志在一英里外,你就踩油门。当停车标志越来越近时,你就松开油门。
- 问题: 如果你只使用P控制器,机器人很可能会直接冲过目标,意识到自己走得太远,然后反向并来回振荡。
3.2 微分(D)——“刹车”
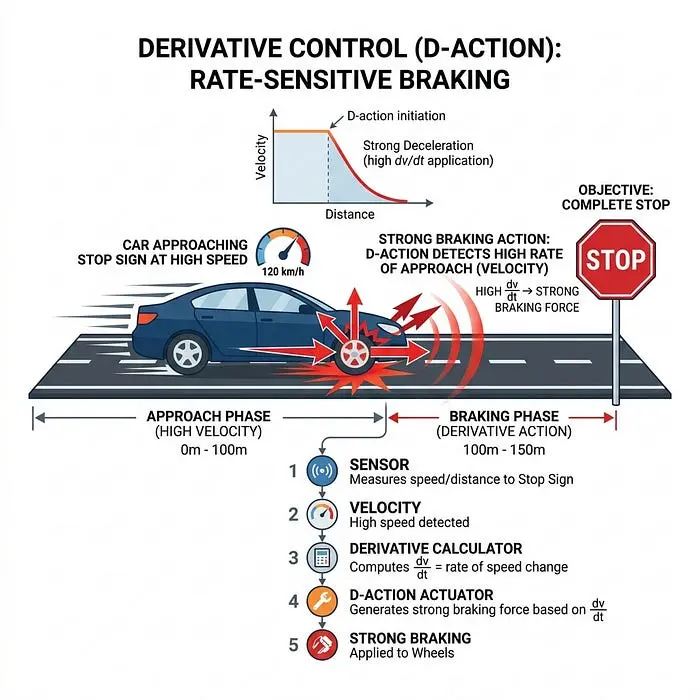
微分项查看误差的变化率。
- 概念: 它不在乎你在哪里;它只在乎你接近目标的速度有多快。
- 在物理学中: 它就像一个阻尼器(摩擦),人为地减慢系统以防止其摆动超过目标。
- 汽车类比: 即使停车标志仍然在50英尺外,但如果你以80英里/小时的速度接近它,D项会意识到你来得太热并猛踩刹车。
3.3 积分(I)——“轻推”
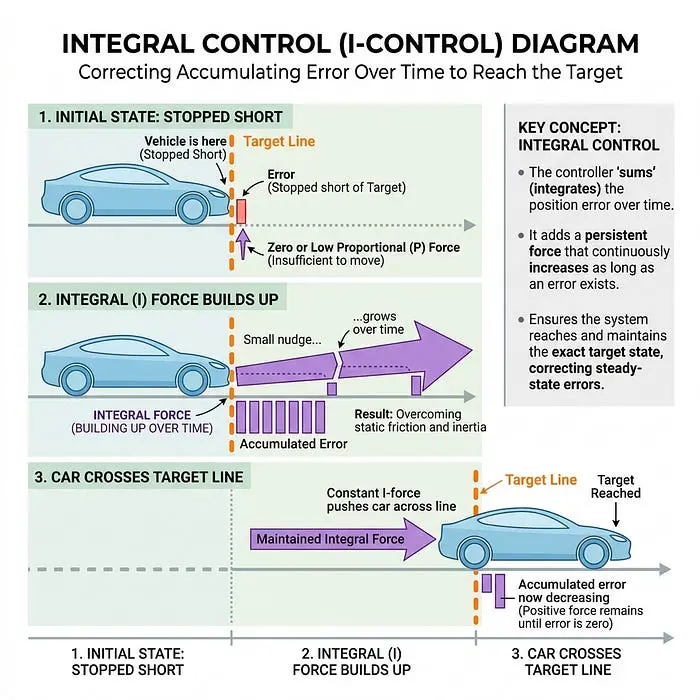
积分项查看你过去累积的误差。
- 概念: 有时机器人几乎到达目标,但物理力(如重力或紧绷的电线)将其停在差几毫米的地方。积分项会慢慢累积这个微小的误差,直到它产生足够的力给机器人最后的推动。
- 在物理学中: 它纠正“稳态误差”。
- 汽车类比: 你在停车线前几英寸处停下。你坐在那里一秒钟,意识到你还没到,然后轻轻踩一下油门踏板向前移动一点。
积分饱和危险: 因为积分随时间累积,如果误差持续太久,积分项可能会变得巨大并导致剧烈的不稳定。
3.4 如何调整PID控制器
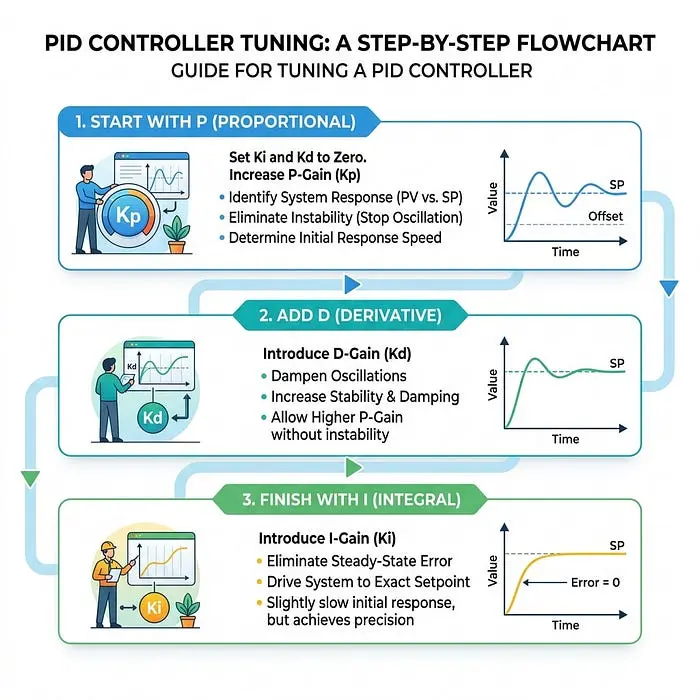
在现实世界中,工程师必须调整乘数(增益 K_p, K_i, K_d)以获得完美的运动。虽然有高级的数学方法,但通常使用标准的“快速手动调整”方法:
- 从仅P开始: 将 K_i 和 K_d 设置为零。增加 K_p 直到系统对设定点变化响应迅速,但在变得不稳定并剧烈振荡之前停止。你希望它到达目标,即使有点超调。
- 添加D以阻尼: 缓慢增加 K_d。你会注意到超调和反弹开始消失。D项充当刹车。继续增加它,直到响应快速且快速稳定而没有过度的反弹。
- 最后用I消除偏移: 如果你的机器人在目标前停止(稳态误差),缓慢增加 K_i。这将累积误差并给机器人最后的推动以达到精确目标。保持 K_i 尽可能小以避免积分饱和不稳定。
4、移动机器人控制
到目前为止,我们一直在讨论控制抽象的“质量”滑动。但真实的机器人有车轮,车轮引入了一套全新的物理规则。
4.1 全向机器人控制(直接速度)
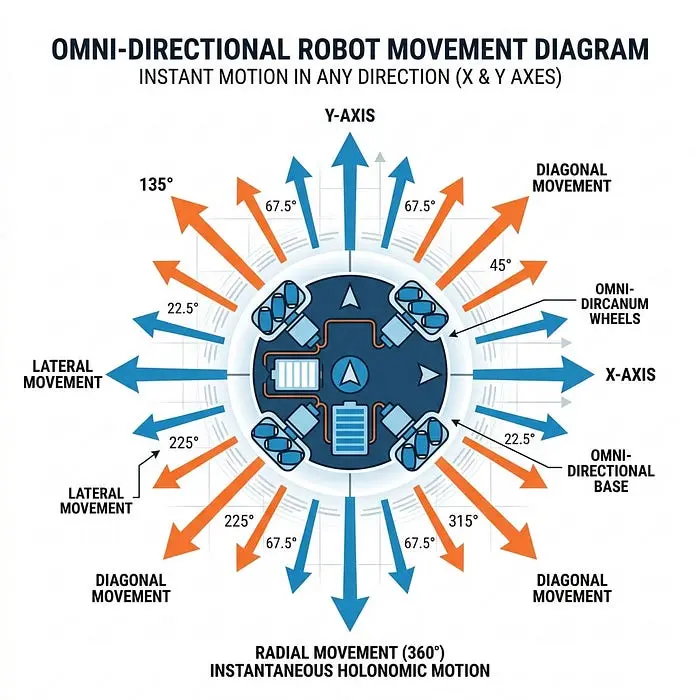
在理想情况下,全向机器人可以立即向任何方向移动。对于这个机器人,我们的控制输入直接转换为沿X和Y轴的速度。
我们可以定义一个比例控制律,将机器人从当前位置驱动到目标位置:
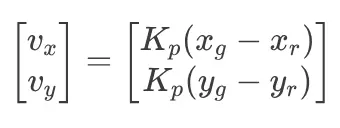
其中:
- v_x, v_y:沿X和Y轴的指令速度。
- K_p:比例增益(机器人对误差的反应强度)。
- (x_g, y_g):目标位置的坐标。
- (x_r, y_r):机器人的当前坐标。
4.2 非完整约束
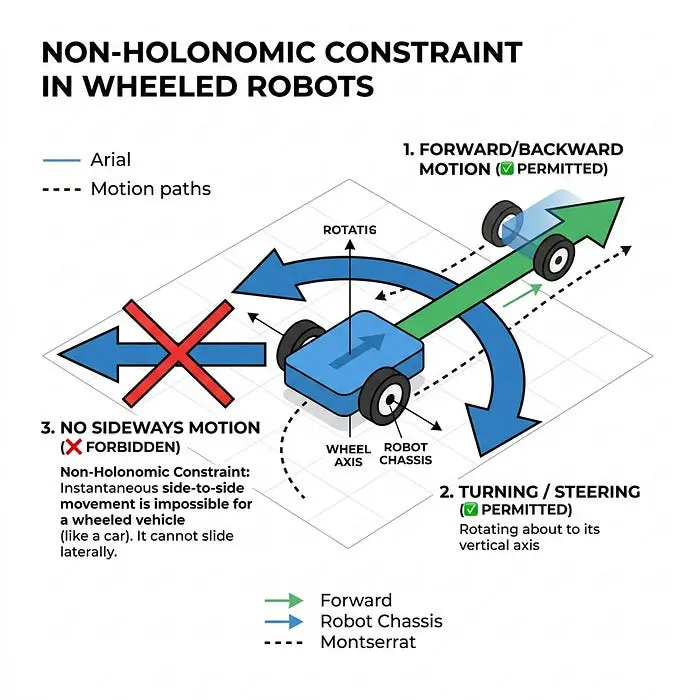
然而,标准的轮式机器人(如汽车或差速驱动机器人)不能横向移动。这是一个非完整约束。因为如果机器人侧向面对目标,它无法立即朝目标方向移动,所以标准的P或PD控制律会失败。
4.3 一个简单的解决方案:“拖车挂钩”数学
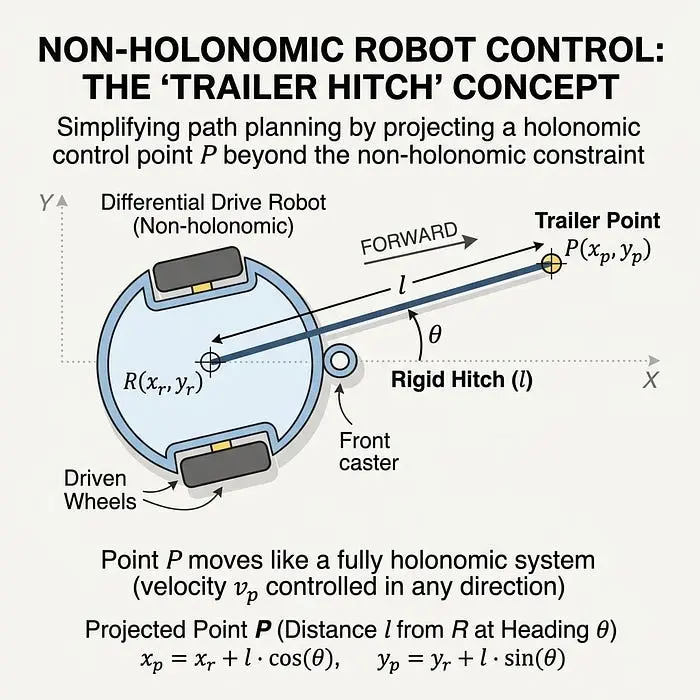
为了解决这个问题,我们从数学上将一个点 (x_p, y_p) 投影到机器人中心前方一小段距离 (l) 处,就像一个刚性拖车挂钩。通过控制这个投影点而不是机器人的中心,我们可以使用标准控制律。
1)投影点: 我们根据机器人的位置 (x_r, y_r) 和方向 (theta_r) 计算其位置:
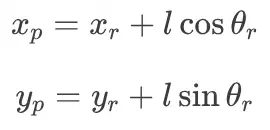
2)速度映射: 我们可以将此投影点的速度 (dot{x}_p, dot{y}_p) 与机器人的物理输入(前向线速度 v_f 和转弯角速率 omega)相关联:
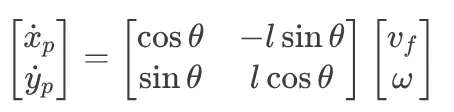
3)反转: 通过反转此矩阵,我们可以根据我们希望投影点去的地方找到要发送给电机的确切命令 (v_f, omega)。
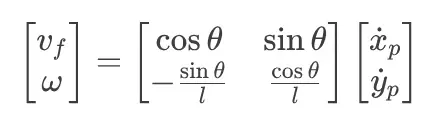
这是一种反馈线性化形式,使非线性系统表现得像线性系统。
5、超越基础(现代研究)
虽然PID和拖车挂钩数学是很好的基础,但现代机器人技术需要更先进的技术来处理复杂任务。
5.1 模型预测控制(MPC)
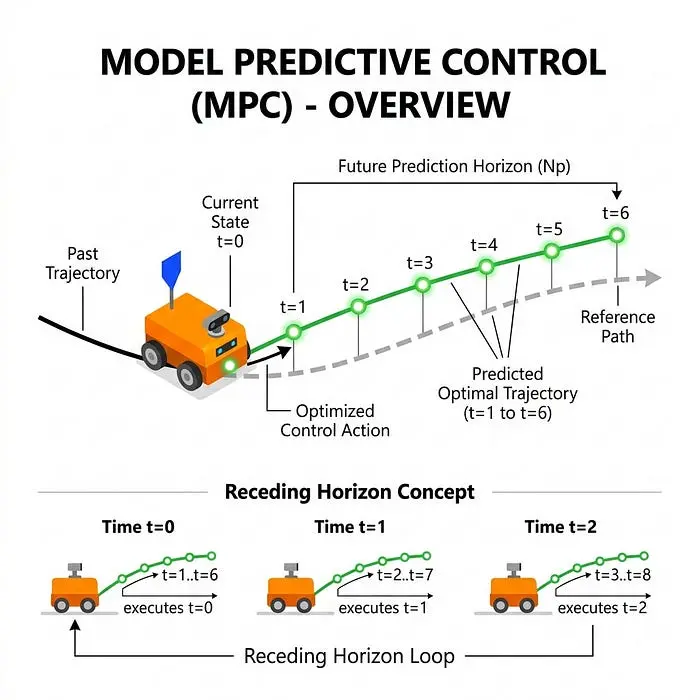
想象下国际象棋。你不仅仅看棋盘的当前状态然后走一步;你计划几步之后,预测结果。
MPC 正是为机器人控制做这个。它不是只看当前误差(如PID),而是使用机器人的物理模型来预测其在未来短时间窗口(视界)内的未来状态。在每个时间步,它解决一个优化问题,以找到最佳控制输入序列,该序列最小化未来误差,同时严格遵守物理约束(如电机电压限制、最大速度或障碍物避让)。一旦序列中的第一个控制输入被应用,该过程就会在下一个时间步重复。它广泛用于自动驾驶(例如,车道保持)和平衡动态机器人,如波士顿动力公司的Spot。
5.2 强化学习(RL)用于控制
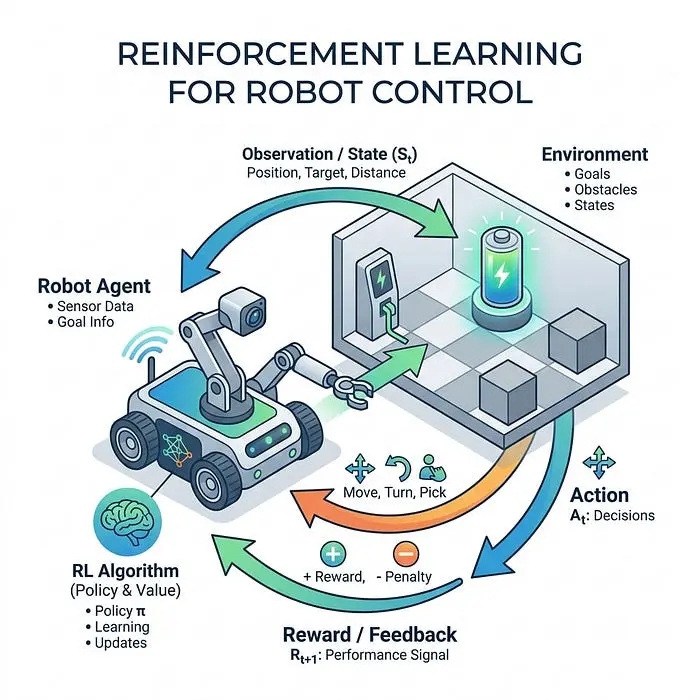
如果不编写复杂的物理方程和手工调整控制器,而是让机器人能够自我控制呢?
在基于RL的控制中,机器人通过试错学习,通常在高速物理模拟中。一个神经网络(策略)接收机器人的状态并输出控制动作。机器人对可取行为(如向目标移动或保持平衡)获得数值“奖励”,对不可取行为(如摔倒或与障碍物碰撞)获得“惩罚”。经过数百万次模拟迭代,机器人学会最大化其总奖励。这种方法在训练四足机器人在不平坦地形上行走和使用机器人手操纵复杂物体方面取得了令人难以置信的成功,这些任务对于传统建模来说极其困难。
原文链接: Robotics Module 5# Robotics Control: From Physics to Software
汇智网翻译整理,转载请标明出处
