教机器人理解三维世界
现代视觉-语言-动作(VLA)系统整合了几个基本模块:视觉感知、语言推理以及视觉与语言的多模态对齐。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
现代视觉-语言-动作(VLA)系统整合了几个基本模块:视觉感知、语言推理以及视觉与语言的多模态对齐。
1、核心组件
1.1 图像编码器
负责感知环境并从当前状态提取特征(如物体类型、位置和其他属性)的关键组件。它充当系统的"眼睛",提取场景特征,随后用于推理和决策。当代VLA系统采用基于Transformer的图像编码器架构。
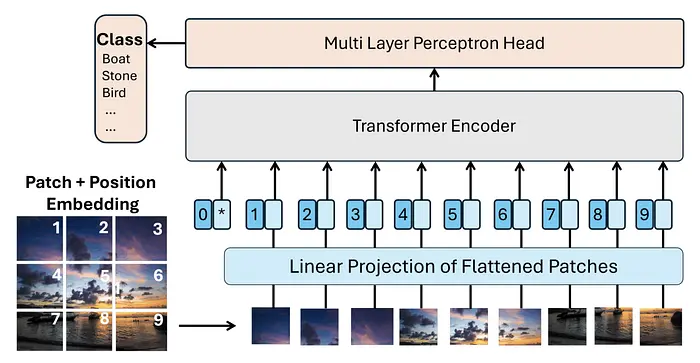
1.2 ViT(CLIP, SigLIP, DINOv2)
视觉Transformer(ViT) 是一种计算机视觉架构,它改编了NLP任务中的自注意力机制。概念很简单:ViT将图像分割成小块,并将每个块投影为向量表示(嵌入向量)。这些嵌入向量在输入到Transformer编码器之前会添加位置编码。
与传统的卷积网络不同,这种方法不仅分析局部片段,还能捕捉不同图像区域之间的关系,从而形成更全面的表示和更完整的场景理解。
这种自编码器为许多后续的Transformer架构(包括CLIP、DINO、SAM等)奠定了基础。
让我们简要了解一下其中几种:
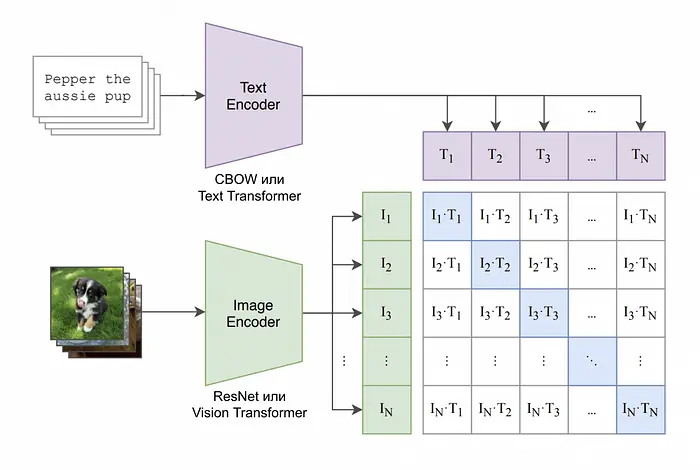
CLIP。一种能够理解文本与图像之间关系的多模态架构。CLIP实现了文本和图像在统一嵌入空间中的联合语义表示,使模型能够同时处理两种数据类型。它包含一个基于ViT的图像编码器和一个文本编码器(基于GPT)。通过对比学习(文本-图像对进行对齐)并利用大规模数据集,模型发展出多样化的表示和对文本-图像关系的通用理解。 主要缺点在于缺乏高精度操作所需的像素级粒度(例如精确的分割掩码或深度估计)。
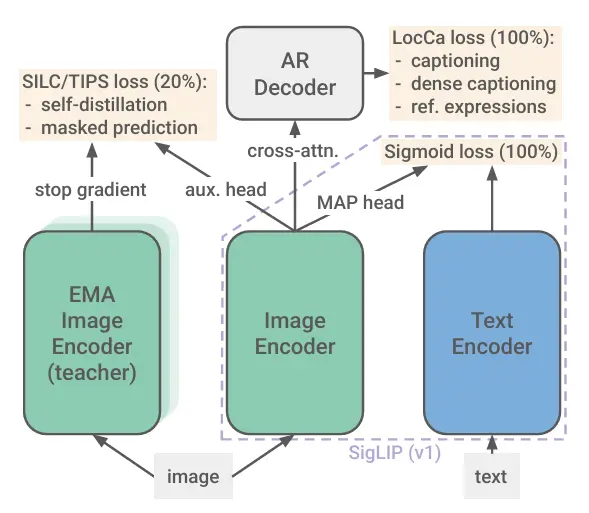
SigLIP 2——CLIP的改进版本。通过SSL方法实现了质量提升,特别是训练过程中的自蒸馏。学生模型仅看到局部图像裁剪,而教师模型看到全局裁剪。这样,模型学会了从细节中得出与完整图像相同的表示。例如,看到狗的鼻子,模型会在大脑中"重建"整条狗。其他技术包括类似掩码自编码器中的块掩码重建,以及在训练过程中生成带标题的边界框,以教导模型将图像细节与文本关联起来。
SigLIP已成为近期开源模型(如OpenVLA和π₀(Pi-Zero))的热门选择。
DINOv2。采用无监督自蒸馏范式,能够提取高度鲁棒的视觉特征。与CLIP不同,DINOv2擅长提取低级空间细节和理解场景几何结构,这对于物理机器人-物体交互至关重要。例如,OpenVLA模型将DINOv2与SigLIP结合使用,以融合深度语义理解与高空间精度。
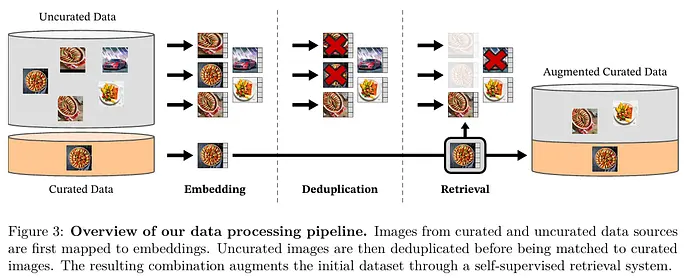
简要总结:
当代趋势是将多个模型(如CLIP、DINOv2和SAM)蒸馏到单个架构中,或同时利用它们进行融合(如OpenVLA所实现的)。这使得模型能够同时理解"什么"在它面前(通过CLIP/SigLIP)以及"在哪里"(通过DINOv2)。
2、3D/点云编码器
由于机器人在三维空间中操作,整合3D数据可以更好地考虑物体几何、姿态和环境物理约束。点云是3D表示的热门选择,因为它们易于从RGB-D相机和LiDAR数据中提取。
3D/点云编码器是将3D数据转换为适合下游任务的紧凑、信息丰富表示的神经网络或算法模型。
点云是3D空间中的一组点,每个点通常具有坐标(x, y, z),有时还包括颜色(RGB)、反射光强度、表面法线甚至密度等附加特征。与位于规则像素网格上的2D图像不同,点云中的点是任意散乱的,数量可能变化,分布不规则且稀疏。编码器的主要目标是将点集转换为保持物体几何和结构信息的固定大小向量表示(嵌入)。
例如,点云用于以下方法:
DP3(3D扩散策略):动作模块。 利用紧凑的3D表示来学习视觉运动控制策略,提供卓越的泛化能力。具体来说,输入包括场景表示(点云)、机器人状态、目标(例如点云中的物体掩码),DP3决定在给定几何约束下如何完成目标任务——即采取什么行动。
LEO:一种将点云编码器与大语言模型(LLM)相结合的模型,使机器人能够理解3D世界(物体几何、位置、朝向以及描述物体是什么的语言嵌入)并规划任务。它桥接了语言↔3D几何↔动作。LEO经常作为VLM/LLM与动作模块(如DP3)之间的桥梁,将场景转换为有意义的3D实体集,而不是原始点云。
简要说明:
LEO = 以物体为中心的3D表示 + 语言嵌入
典型流程:
摄像头/深度 → 3D场景重建
场景分割 → 提取物体
对于每个物体,其3D形状、裁剪/视图通过VL编码器处理
生成LEO集合:LEO₁ = "红色杯子",LEO₂ = "纸箱",LEO₃ = "桌子"
3D-VLA:一类系统,其中语言定义目标,3D场景表示(点云、NeRF、TSDF等)提供对物理世界的理解,而动作模块(通常是扩散策略)生成实际的机器人运动。简而言之:
示例:
VL模型定位杯子和箱子
构建3D场景表示
确定箱子内的目标区域
DP3接收:场景点云、杯子点云、目标姿态
DP3生成轨迹:抓取、搬运、释放
存在几种流行的编码3D点的方法:
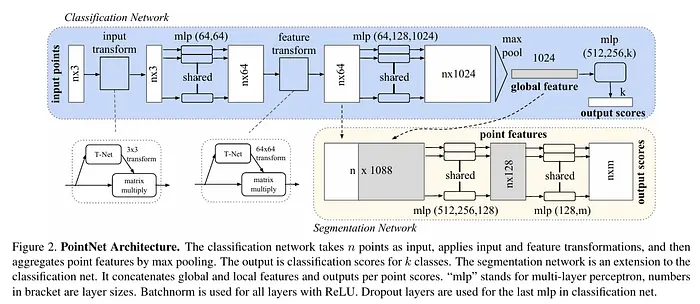
3.1 PointNet和PointNet++
作用于无序3D点且对排列不变的架构。本质上,它们寻找一种排列不变函数。
PointNet 对每个点单独应用小型MLP(多层感知器),然后通过对称函数(通常使用最大池化,因其具有不变性)聚合结果,以获得全局物体向量。
然而,PointNet在捕捉局部结构方面存在困难,由此产生了改进模型。PointNet++ 引入了层次化处理:首先分别处理局部点簇(点子集),然后合并结果,从而更好地捕捉局部结构。
PointNet / PointNet++ 常用作场景编码器、物体编码器(LEO)和3D编码器。
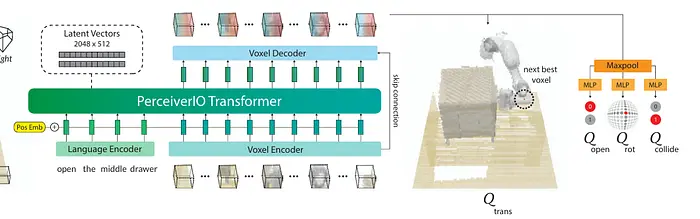
3.2 基于体素的方法
3D空间被划分为体素网格(像素的3D类比)。然后应用3D卷积网络进行特征提取。然而,由于使用标准CNN,精度会有所损失。
例如,PerAct——一种用于机器人操作学习的端到端Transformer智能体,它统一了:3D场景感知、语言理解和机器人六自由度(6-DoF)动作生成。
PerAct不是通过物体检测→姿态估计来构建场景,也不是从2D图像推导策略,而是如下操作:
- 在3D中对场景进行体素化——即将空间离散化为立方体(体素),并用RGB-D数据填充。这生成了场景几何(物体形状和位置)的结构化表示。
- 通过语言模型对语言(指令)进行编码,以理解具体需要做什么。
- 将体素化的3D信息与目标嵌入融合,并通过Perceiver Transformer进行处理——这是一种能够高效处理超长数据序列(可达数百万个体素)的架构。
- 模型输出3D中的离散化动作——末端执行器(机械臂)的位置和方向、夹爪状态(张/合)以及运动规划器参数。这是通过"下一个最佳体素动作检测"实现的。
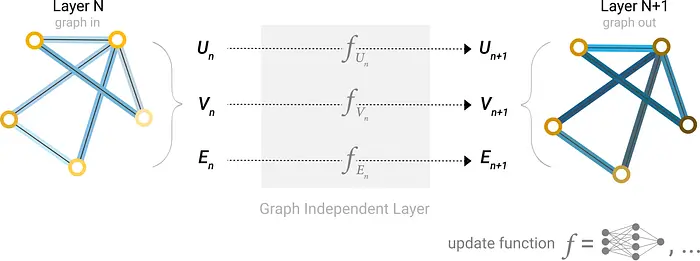
3.3 用于点云的GNN
这里,点被当作图顶点,边连接最近邻点。GNN可以捕捉点之间的局部关系,提高复杂几何形状的表示质量。
3.4 Transformer(点Transformer)
其思想是对点应用自注意力,使每个点能够"关注"其他点,学习全局和局部关系。
3.5 对比和自监督编码器
概念与2D图像相同。编码器学习使得相同物体在不同视角或噪声下产生相似的嵌入,而不同物体则产生不同的嵌入。这使得表示更加通用。
小结
优势与挑战:虽然3D编码器提供了优越的几何精度,但它们的实时集成通常受到计算复杂度和3D数据标注成本的限制。
4、文本编码器
- LLM(LLama, Vicuna, PaLM)
- T5-base
- 基于GPT的模型
- 基于Qwen的模型
4.1 动作解码器
负责将抽象的多模态表示转换为具体的机器人控制命令。视觉和语言编码器处理感知和理解,而动作解码器将这些知识转化为物理操作,完成"感知—推理—动作"的循环。
主要动作表示格式
输出格式的选择决定了机器人运动的精度和平滑度:
• 离散标记: 最流行的方法,用于RT-2和OpenVLA等模型。动作被表示为标记,使模型可以像标准语言系统一样训练,预测下一个标记。这很方便,因为Transformer更容易在离散标记预测上进行训练,而机器人在连续空间中操作。
动作标记 是来自有限集合(词汇表)的一个元素,编码了动作的一个组成部分。
存在几种离散化变体。最简单的是分箱。例如,在RT-2中,动作向量被量化到256个"箱"中,包括末端执行器位置、旋转和夹爪状态。然而,主要缺点是动作空间巨大。
或者,分解的动作标记:动作被分解为子动作,每个子动作有自己的词汇表(位置有自己的词汇表,手臂旋转有自己的词汇表等)。动作解码器预测的不是一个向量,而是一个标记序列。
更现代的变体:学习到的离散标记(VQ,码本),其中自编码器(VQ-VAE,VQ-GAN,tokenizer)生成一个码本,用于将连续动作转换为标记——在预训练此自编码器之后。
通用方案:
(场景嵌入 + 语言嵌入) ↓ 动作解码器 ↓ [token_1, token_2, …, token_T]
• 连续输出:用于实现高控制频率和精度(例如在π₀模型中)。不采用离散化,而是应用扩散模型或流匹配,直接生成平滑的关节轨迹。这种方法对于高自由度机器人扩展性更好。
在扩散模型的情况下,我们去除动作中的噪声。最终得到实际动作。
与离散标记相比,这类模型更难训练,更难调试,但提供高精度和平滑运动。
根据控制任务的要求,采用不同的神经网络架构:
- 扩散Transformer:例如在Octo和DexGrasp VLA模型中。
- 自回归Transformer:逐步生成动作,例如Gato模型。
- 带下一标记生成的MLP。OpenVLA和RoboMamba中的较简单架构。
- MCP(规划器)。规划器是控制系统的组成部分,它决定做什么以及按什么顺序做,而不是如何立即移动电机。某些模型(例如VoxPoser)包含基于预测模型的(模型预测控制)模块,用于动态环境中的决策。这个类别包括VoxPoser、Mobility VLA、LMM Planner Integration、FLaRe。
5、架构范式
5.1 端到端
这种方法适用于数据丰富且不需要大量规划的简单短时任务。但对于更复杂的任务,它存在困难,并且无法为长期目标进行规划。
基于扩散的策略通常被归类为端到端,但它们解决的是不同的问题。扩散并不增加规划能力。相反,它使动作推理更加鲁棒:模型不是输出单一确定性动作,而是描述可能动作的分布。这减少了平均效应并产生"更柔和"的行为,但模型本质上仍然是反应式的。
因此,现代VLA系统很少对所有内容采用"纯"端到端架构。通常,它们作为低级策略,擅长局部动作执行,而更高级别的结构叠加在它们之上:任务分解、高级规划或子目标选择。
5.2 机器人Transformer 2(RT-2)——LVLA的先驱
由Google DeepMind在2023年开发,RT-2成为第一个建立VLA范式的机器人领域大规模模型。
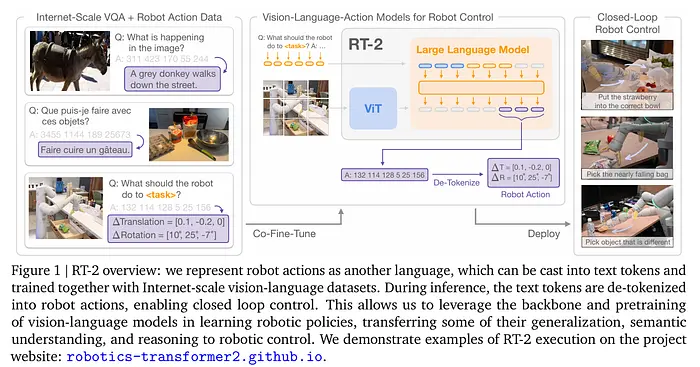
如果LLM学习预测下一个文本标记,那么RT-2学习预测下一个动作标记,以图像和指令为条件。本质上,任务简化为将指令和视觉数据转换为标记序列。LLM以自回归方式训练来预测下一个动作标记。
• 架构:单个大型自回归Transformer。关键是,动作是离散化的。该模型建立在预训练的多模态主干网络(如PaLI-X和PaLM-E)之上。
作为视觉编码器:模型使用大规模视觉Transformer(ViT)变体,参数规模扩展到220亿。
• 训练方法:RT-2采用联合微调。模型同时在两个不同的数据流上进行微调:互联网规模的可视问答数据集(VQA)和机器人特定运动轨迹(帧、文本命令和从机器人收集的真实动作标记序列)。这种方法确保模型在学习机械臂控制的同时,不会"忘记"其积累的关于世界的知识(例如恐龙长什么样)。
RT-2还进行思维链推理的微调。这使得模型能够先口头计划一个步骤(例如"需要找到重物"),然后输出动作标记。
• 数据:基础是之前RT-1模型的数据集。利用用于图像和文本理解任务的互联网数据——PaLI-X和PaLM-E曾在此上训练。这包括数百万个描述物体、其属性和关系的图像-文本对。后续版本(RT-2-X)在OXE数据集上训练,该数据集包含来自22种不同机器人类型的超过100万个轨迹。
• 局限性:在长时规划和精确几何方面存在挑战(由于使用离散表示)。
5.3 OpenVLA
于2024年推出,OpenVLA作为闭源RT-2的开源对应版本,针对广泛的社区采用进行了优化。
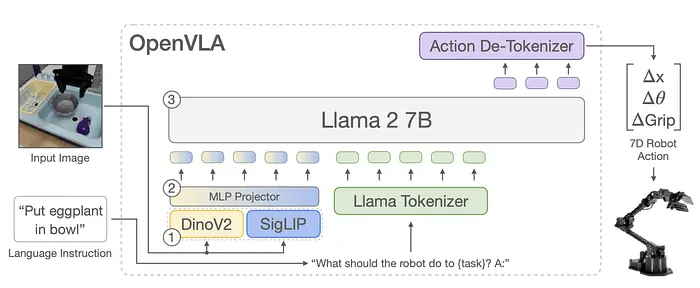
拥有70亿参数,基于Llama 2语言模型构建。与RT-2不同,它融合了两个不同视觉编码器——DINOv2和SigLIP的特征,增强了空间精度。模型处理相机图像、文本指令和机器人本体感觉数据(关节状态),将它们转换为统一的标记序列。OpenVLA预测7维动作向量(夹爪位置、方向和抓取状态)。
尽管规模较小,但在29个操作任务的基准测试中,OpenVLA以16.5%的成功率优势超越了RT-2(55B),同时参数数量少7倍。它支持高效的微调方法(如LoRA),使得在消费级GPU上进行部署和定制成为可能。
数据集:基础包括Open X-Embodiment (OXE)(包含来自22种机器人类型的超过100万个轨迹)和用于真实世界操作的DROID数据集。
5.4 层次化系统
VLA架构中的层次化范式将机器人控制分为两个层次:高级任务规划("系统2")和低级动作执行("系统1")。
高级规划器(任务规划器):将复杂的、长时指令(例如"打扫房间")分解为一系列简单的子任务或自然语言指令。
低级策略(控制策略):接收子任务和视觉数据,生成具体的控制命令(旋转、平移、关节力)。
5.5 SayCan
一种架构范式,其中语言模型决定做什么(Say),而第二个模块处理低级技能(Can)——导航、旋转、抓取等。低级策略(BC-Z或MT-Opt)提供功能函数,估计在当前环境状态下成功执行该技能的概率(世界基础化)。
每一步,SayCan:
- 提示LLM提出可能的下一步动作。
- 对于每个动作,查询相应的技能:"你现在执行此操作的可能性有多大?"
- 相乘: — 语言概率(Say), — 可执行性概率(Can)。
- 选择联合得分最高的动作。
这里,LLM和技能不是联合训练的。LLM要么冻结,要么单独微调。技能本身独立训练——通过模仿学习或强化学习。
缺点:该方法相当慢;子任务执行中的错误可能触发重新规划循环,导致运动暂停;规划器可能生成低级系统在物理上无法执行的子任务。
优点:可扩展性(可以使用大型LLM进行规划),长时能力(扩展的规划)。
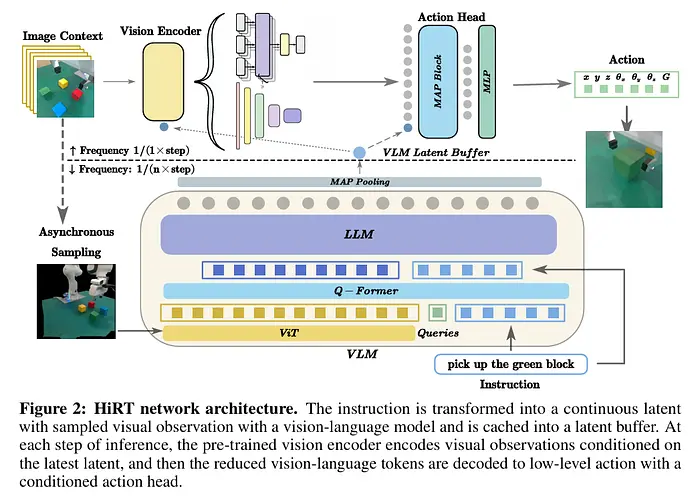
5.6 HiRT
SayCan范式的一个例子是HiRT。然而,它更加神经网络化,不那么"粘合模块",并且朝着端到端推理发展,同时形式上仍然是层次化/规划驱动的。
架构: 视觉编码器:采用InstructBLIP,专注于文本指令上下文中的视觉场景理解。 语言编码器:LLaMA-2作为处理命令的主要"大脑"。 动作解码器:HiRT不使用复杂的扩散系统,而是使用一个MLP头(隐条件策略头),基于上层层次的隐表示生成命令。
5.7 Gemini Robotics 1.5
该范式的当代体现是Gemini Robotics 1.5,采用"智能体"方法:
- 编排器(GR-ER 1.5): 处理高级规划,可以查询外部工具(如Google搜索)来理解任务规则。 • VLA组件(GR 1.5): 使用"具身思考"执行计划——在执行运动之前生成关于运动的内部推理链。
5.8 模块化范式
系统由独立(通常是现成的)组件组装而成,例如大语言模型(LLM)和视觉-语言模型(VLM),将它们连接在一起。与端到端系统不同,模块化架构通常不需要对整个流程进行大规模微调,并允许灵活替换系统的个别部分。
模块不是在单一网络内传递向量(嵌入),而是在"人类"级进行通信。例如,LLM编写程序代码,调用视觉模块进行物体检测,然后将坐标传递给控制器。
5.9 VoxPoser
该系统使用LLM(例如GPT-4)将用户指令转换为可执行代码,该代码调用VLM获取物体坐标。
基于VLM数据,创建两个3D图:一个指示机器人应定位位置的可操作图,以及一个用于避障的约束图。
生成的图被传递给外部模型预测控制(MPC)控制器,该控制器计算机器人的最优实时抓取轨迹。
VoxPoser在零样本模式下成功完成复杂的操作任务(无需在特定机器人数据上进行事先训练)。
6、SVLR
SVLR的核心思想是将控制过程划分为清晰的阶段,而不需要经典的端到端训练(免训练方法)。
该模型使用视觉提示检索来执行控制策略。模型不是从头学习生成动作,而是将识别到的图像片段与预定义的动作库进行匹配。
视觉组件基于Mini InternVL,而语言处理使用Phi-3-mini。视觉编码器(Mini InternVL)将图像分割为物体。系统将获得的片段与视觉提示库进行比较。一旦在数据库中找到匹配的视觉片段,基于脚本的动作绑定器会激活特定的控制策略,将识别的场景片段映射到具体的机器人命令。
在操作过程中,机器人不会收到新的外部提示,而是从记忆中"检索"它们(检索机制)。
该系统使用由自行收集的视觉提示组成的数据集,这些提示帮助模型将视觉模式与空间中的物理对象关联起来。
"非典型动作"问题: 如果人请求的某事不在数据库中(例如"扔苹果"而不是"放在桌子上"),模块化系统可能会遇到困难。如果"扔"这个技能没有被预先编程或在数据集中收集,机器人根本不知道要构建什么轨迹。然而,LLM可能会尝试寻找最接近的类比(例如"扔球")并将该视觉模板应用于苹果片段。
6.1 扩散策略
将动作生成重新概念化为随机噪声的迭代去噪过程。与预测离散标记的传统模型不同,这种方法能够生成平滑的连续轨迹(建模动作分布)。
在这种范式下,机器人控制不被视为下一步分类,而是条件数据生成任务。
模型从有噪声的动作序列开始,并逐步优化。连续输出避免了离散化(量化)问题,而这些问题在RT-2等模型中可能导致空间精度或时间分辨率降低。
6.2 Octo
加州大学伯克利分校开发的大型开源扩散通用策略。
它使用Transformer作为核心枢纽,各种视觉数据编码器和文本指令编码器可以通过块状注意力结构连接到该枢纽。
架构:
- 输入分词器 — 所有输入都转换为标记(观察:图像、历史、文本指令)
- Transformer主干。 提供对场景正在发生什么以及需要执行什么任务的理解。重要的是,架构设计使得可以添加新输入(例如额外的摄像头流或本体感觉数据),而无需修改Transformer核心。
- 扩散读出头。 扩散策略学习从有噪声版本(故意损坏的动作,我们试图恢复)中恢复真实动作,使用DDPM方法。这是Transformer嵌入与扩散算法之间的适配器。我们从噪声中恢复动作:获取Transformer隐状态 -> 投影到动作空间 -> 输出噪声估计。
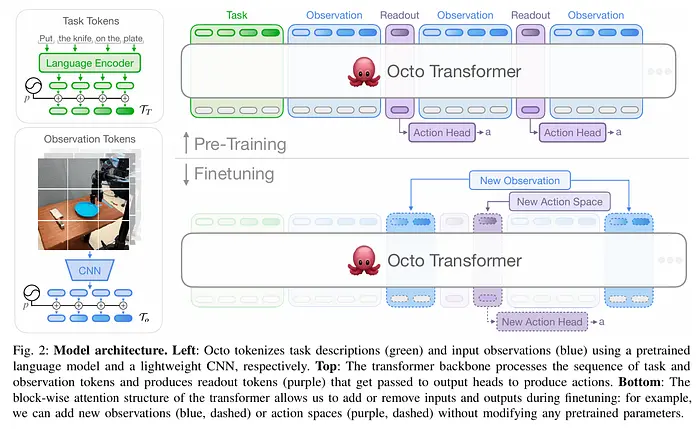
该模型在涵盖22种不同机器人平台的数据集上训练。与自回归解码器不同,Octo采用扩散头输出连续关节轨迹,确保更平滑的运动和快速适应新任务。
在推理时,它的工作方式如下:
取干净的噪声(随机轨迹)
输入场景+指令
多次运行模型
6.3 模型π₀(pi-zero)
Physical Intelligence公司的π₀代表了专注于极端灵巧性的扩散思想的演进。
不采用离散扩散步骤,π₀使用流匹配——一种连续时间模型,训练用于预测将噪声引导向干净动作值的向量场。由于转向流匹配,π₀在动态方面显著超过了Octo。
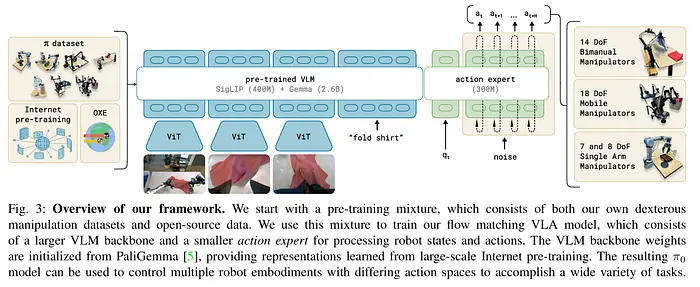
该模型构建在预训练的PaliGemma主干(结合SigLIP和Gemma)之上,并附加了使用**混合专家(MoE)**的专门动作专家模块。
由于扩散速度较慢,会产生延迟问题。对于现实世界任务,使用了**实时分块(RTC)**算法,该算法允许扩散模型在执行先前动作的同时生成新的动作块,消除了机器人运动中的停顿。
7、数据
Open X-Embodiment
- 包含超过100万个轨迹( episode)
- 汇集来自22种不同机器人类型的数据,包括单臂和双臂机械臂以及移动平台
- 涵盖超过500种技能和超过16万个独特任务
- 在311个不同场景中收集的数据
- 以RLDS格式提供,存储为分片TFRecord文件
- 包括RGB图像、深度图、自然语言指令和机器人动作向量
在此数据上训练的模型:OpenVLA, RT-X (RT-1/RT-2), Octo, pi-zero
Kaiwu
一个大规模真实世界多模态数据集,于2025年推出,用于训练机器人进行复杂操作和人机交互。
- 该数据集包含100万个多模态 episode
- 专注于高复杂度操作和长时规划任务
- 涵盖真实世界场景中各种机器人类型的多实体操作
- 包括:RGB图像、深度图和物体/智能体的3D骨架
- 物理信号:触觉反馈、IMU数据和音频
- 人类生物特征数据:EMG(肌电图)信号、注视方向和动作捕捉
- 用于控制和交互的自然语言命令
- 数据以HDF5格式存储
RT-1-Kitchen
- 约13万个 episode
- 包含超过700个独特任务,由12个核心技能组合而成(如"拿取"、"放置"、"打开"、"敲击")
- 涉及在2个不同的办公厨房场景中操作16种不同物体
- 包括RGB图像和自然语言文本指令
- 通过人类远程操作在真实办公厨房环境中手动收集数据
最初为RT-1创建,随后用于RT-2、MOO、Q-Transformer和RT-Trajectory。
DROID
用于在真实非结构化"野外"条件下训练机器人操作的数据集
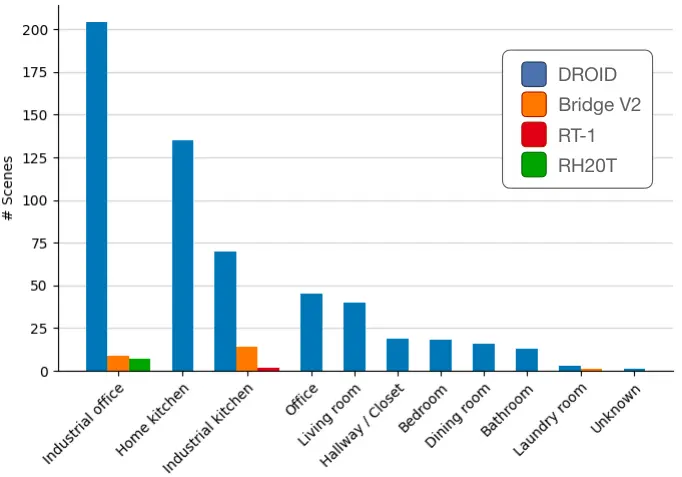
- 76,000个演示
- 在564个不同场景中收集的数据
- 涵盖86种不同操作技能
- 包括RGB图像、深度图和立体视频
- 每个演示都附有自然语言标注
- 以RLDS格式提供的数据(与Open X-Embodiment相同)
用于训练OpenVLA、FAST、V-JEPA 2
BridgeData V2
- 包含60,096个轨迹(episode)。其中50,365个通过人类远程操作收集,9,731个通过脚本策略收集。几乎所有数据都是使用WidowX机器人操作器收集的。
- 数据集涵盖24个不同场景、超过100个独特物体和约250种不同技能
- 包括RGB图像、深度图和自然语言指令
- 动作表示为连续7自由度(7-DoF)向量,能够描述复杂的空间运动
- 数据以TFRecords格式序列化
用于训练的数据集:Octo, RT-X, Edge VLA, 和 ECoT
8、CALVIN和LIBERO
CALVIN和LIBERO是专门的仿真数据集和基准测试。
CALVIN 基于PyBullet物理引擎,使用Franka机器人模型构建。包含超过5,000个演示,包括同步的RGB-D帧、力数据、本体感觉和文本指令。作为标准基准,用于包括GR-1、HULC、RoboFlamingo、RoboUniView、UP-VLA和OE-VLA在内的模型。
LIBERO 作为研究持续性学习的基准测试而开发。数据集包括130个独特任务。数据以JSON和Parquet格式存储,包括图像、动作轨迹和结构化元数据。LIBERO展示了MDT、OTTER、VLA-Cache等现代架构的能力。
8.1 仿真器
在VLA中,仿真器是一个可控的"伪现实",智能体在其中学习行动:接收视觉观察、执行动作、获得奖励和失败,而无需真实的机器人。
仿真器几乎从不"从头"编写。 在99%的情况下,仿真器开发是从现成的积木组装而成,其中物理、渲染和传感器已经存在,研究人员只需添加必要的逻辑和训练接口。
几乎所有现代仿真器的核心都包含一个物理引擎。这是一个计算物体运动、碰撞、力、摩擦、惯性和关节的大型系统。
在物理之上,添加场景几何。这仅仅是物体的网格:桌子、杯子、盒子、机器人、地板。每个物体都被原始地描述:形状(网格或简单基元)、质量、质心、摩擦系数、弹性。
下一层是机器人模型。机器人通过URDF或等效格式描述:有哪些关节、什么约束、什么连杆、电机在哪里。然后将此描述加载到引擎中,物理引擎自己计算机器人运动学和动力学。
之后,出现环境逻辑。这些是非常简单的东西:episode何时开始和结束,什么算成功,允许哪些指令。
通常,仿真器包含场景(房间、桌子、机器人、物体)、物理(重力、碰撞、摩擦)、摄像头和传感器。智能体接收观察,如RGB或RGB-D图像、机器人状态(关节角度、速度),有时还有场景描述或指令。作为回应,它输出动作:移动手臂、旋转夹爪、张开夹爪等。仿真器计算物理并返回下一个状态。一步一步,一个episode展开。
还有另一种模式,策略直接在仿真器内通过RL或其混合体进行训练。然后模型行动,接收奖励(任务成功/失败),并逐步改进。通常的方法是:首先在仿真演示上进行大规模模仿学习,然后进行一些RL微调,最后全部蒸馏到单个VLA模型中。
流行平台:
AI2-THOR. RGB、深度、分割、物体状态。在逼真的家庭室内场景中进行导航和操作(ALFRED的基础)。
Habitat. RGB、深度、分割、智能体姿态。在大规模3D场景中实现高性能导航。
NVIDIA Isaac Sim. LiDAR、点云、力/扭矩、RTX渲染。工业机器人、RL、数字孪生。
MuJoCo. 接触力、运动学、RGB。用于精确控制和接触动力学的高速仿真。
SAPIEN. 分割掩码、可活动物体。使用可变形和复杂物体进行操作,灵巧抓取。
PyBullet. RGB、深度、接触力。快速原型制作和长时任务(CALVIN的基础)。
Kinetix. 力控制。动态任务(投掷、接住、平衡)。
仿真主要限制是仿真到现实差距,它使得模型不能仅在仿真上训练。仅在虚拟环境中训练的模型通常在物理机器人上表现较差,原因是显著的视觉差异和物理不准确性。
9、训练
VLA模型几乎从不以同时训练所有内容的"从头开始"方式训练。几乎总是有预训练的模块。视觉编码器是ViT、CLIP、DINO、SigLIP或类似模型。语言编码器是LLM或其蒸馏版本。这些不是从头训练的。
训练通常分两个阶段进行:预训练,其中模型获得基本的对世界的理解;以及针对目标领域的微调(对齐)。有时会添加RL或规划引导的微调。
在许多情况下,不需要完整的参数更新。相反,使用允许模型轻松适应新任务同时保留预训练期间获得的大部分知识的方法。这种方法最小化了灾难性遗忘的风险,并使微调更加经济。此类方法中的一种常见方法是低秩适配(LoRA)。
不更新所有Transformer参数,LoRA向每一层添加两个小的低秩矩阵适配器。主权重W保持冻结,只有这些适配器被训练。
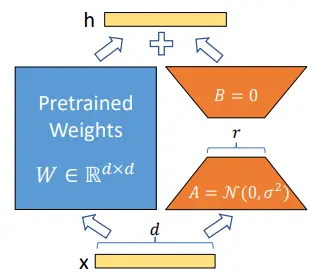
有LoRA的增强版本,如QLoRA,它将LoRA与4位量化相结合。这可以在不损失性能的情况下同时进行适配器训练和基础模型压缩,减少内存需求。
另一种训练方法是冻结所有VLM参数,只更新动作解码器。在这种配置中,VLM充当特征提取器,从视觉和文本信息中提取特征,解码器然后使用这些特征进行动作预测。(RT-2, Lingo-2)
批量大小通常很小,因为图像、视频、扩散和上下文相当占用内存。
9.1 损失函数
损失函数 总是由动作表示方式决定。
如果使用连续动作空间和扩散策略(Octo、pi-zero、部分Gemini Robotics),那么基本损失与图像扩散模型完全相同,只是将图像替换为动作向量。从演示中获取真实动作,在第t步添加高斯噪声,模型必须预测噪声。损失是预测噪声与实际噪声之间的标准MSE。
如果扩散预测的不是一步而是一块动作(例如8-16步的轨迹),那么MSE只需在时间上和所有动作坐标上求和。
如果动作是离散或量化的(如Gato、OpenVLA、一些RT类模型),那么就是标准的交叉熵。动作被表示为标记或标记序列,模型学习预测下一个标记,就像在语言模型中一样。
除了主要损失,通常还添加辅助损失。最常见的是视觉-语言对齐。例如,对比损失(类似CLIP),使场景图像和指令文本存在于相同的空间中。
有时会添加状态预测损失:模型必须预测下一个机器人状态或场景变化。这作为正则化,帮助模型更好地理解世界动力学。
在具有规划或层次结构的模型中,有时会对高级意图产生损失。例如,先预测隐目标或子任务,然后预测动作。然后在这个隐层上有损失,通常也是MSE或交叉熵。
9.2 评估指标
最基本和最重要的指标是成功率。取一组任务或指令,在仿真或真实机器人上运行模型,计算任务完成的episode比例。例如:"把杯子放在桌子上"、"打开抽屉"、"移动物体"。如果100次尝试中63次成功,成功率为63%。这是一个相当粗略的指标。
但成功率是二元的。因此,经常计算部分成功或任务特定指标。例如,到目标的距离、物体定向的准确度、是否保持了N步、轨迹有多平滑。
VLA中一个非常重要的指标是泛化能力。模型在以下方面进行测试:新物体、新场景、新的指令表述、训练中未见的组合。并观察成功率的下降。如果模型"只知道它见过的东西",那么它作为通用策略就没有用处。
在真实机器人中,另一类指标出现:安全性和稳定性。机器人掉落物体、卡住或执行物理危险运动的次数。
还有语言对齐指标。例如,模型执行了一个动作,但不是要求的动作。形式上成功了,但指令被违反了。因此,有时会加入人工评估:人类观看视频并回答行为是否符合指令,尽管这相当昂贵。
吞吐量:速度和性能的组合指标(每分钟完成的子任务数)。对于实时系统至关重要。
累积进度:评估机器人在时间到期前完成了复杂多步任务的哪一部分。
9.3 资源需求(GPU)
所需的GPU数量在很大程度上取决于模型大小和训练阶段:
巨型模型(基础模型):训练像RT-2(550亿参数)这样的模型需要巨大的计算能力和时间,只有主要实验室(Google DeepMind)才具备。
OpenVLA(7B):可以在消费级GPU(例如RTX 3090/4090级别)上进行微调,得益于使用LoRA和量化(需要约24 GB显存)。
SmolVLA(450M):专门设计用于"民主化"研究;它在小型数据集上训练,甚至可以在CPU或单个消费级GPU(<24 GB VRAM)上运行。
9.4 优化
VLA结合了视觉编码器、语言LLM和动作解码器,总参数从几十亿到几千亿不等。因此,模型推理可能花费相当长的时间,在此期间环境和机器人状态可能发生变化。
这通常通过架构改进(例如混合专家)和目标设备上的计算优化(通过量化和GPU高效推理)来解决。
现代研究侧重于解决延迟和精度问题:
动作分块:解码器不预测一个动作,而是预测一个序列(块)的未来步骤。这提供了时间稳定性,并允许系统在执行当前运动的同时"思考"未来。
10、应用
VLA模型的应用领域

到2025年,配备VLA的机器人正在被积极部署到汽车工厂(例如特斯拉Optimus在电池装配车间,或梅赛德斯-奔驰工厂的Apollo)。
像Helix这样的模型使两个类人机器人能够在一个长任务上协作,实时协调手臂和身体运动。
VLA(特别是RT-2)最重要的特征之一是能够涌现出机器人训练数据中未出现过的技能。例如,机器人可以使用语义推理选择岩石作为"临时锤子",或向"疲惫的人"提供能量饮料,利用从互联网获取的知识。
原文链接: Teaching Robots to Think in 3D
汇智网翻译整理,转载请标明出处
