构建 Codegraph CLI 的经验教训
厌倦了用 grep 翻遍代码库,于是我造了一个更懂代码的 AI

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
六个月前,我加入了一个有 20 万行遗留 Python 代码的项目。没有文档。原来的开发者已经离职。我的第一个任务?"修复认证相关的 bug。"
我打开终端,输入:
grep -r "auth" .
47 个匹配。30 个文件。
我花了两天时间翻阅文件,试图理解认证是怎么工作的。哪个函数调用了哪个?存在哪些依赖关系?如果我改了某处,什么会崩溃?
到了第三天,我想:为什么不能直接问代码库呢?
于是我造了 CodeGraph CLI。
1、传统代码搜索的问题
作为开发者,我们有三种主要方式来探索不熟悉的代码:
1. grep/字符串搜索 — 快但笨
- 不理解语义
- 返回所有包含 "auth" 的地方,不管是否相关
- 你需要手动把点连起来*
2. IDE 导航(跳转到定义) — 更好,但有局限
- 只展示直接关系
- 不解释代码为什么存在
- 不支持自然语言查询
3. 读文档(如果有的话) — 经常过时
- 永远讲不全
- 不展示实际依赖
我们真正需要的是: 一种能用自然语言提问,并得到基于实际代码结构的智能回答的方式。
2、解决方案:图 + 向量 + LLM
我构建 CodeGraph CLI 的核心洞察是:
代码不只是文本。它是一个关系网络。
函数调用其他函数。类继承自其他类。模块导入其他模块。这是图结构,不是扁平文档。
但代码也有含义。validate_token() 和 check_auth() 可能做着类似的事情,即使它们没有共享任何字符串。这需要通过 embedding 实现语义理解。
把两者结合,魔法就发生了:
- 解析代码为抽象语法树(tree-sitter)
- 构建依赖图(SQLite 存储节点和边)
- 将符号嵌入向量空间(LanceDB 用于相似性搜索)
- 用 RAG 查询: 向量搜索找到语义相似的代码,图遍历找到依赖关系
- LLM 用自然语言解释结果
这就是图增强 RAG,效果出奇地好。
3、底层工作原理
3.1 架构概览
你的代码库 n↓ tree-sitter 解析器(容错 AST) ↓ SQLite(依赖图:节点 + 边) ↓ LanceDB(所有符号的向量 embedding) ↓ 图增强 RAG 引擎 ↓ LLM(Ollama、OpenAI、Anthropic 等) ↓ 自然语言响应
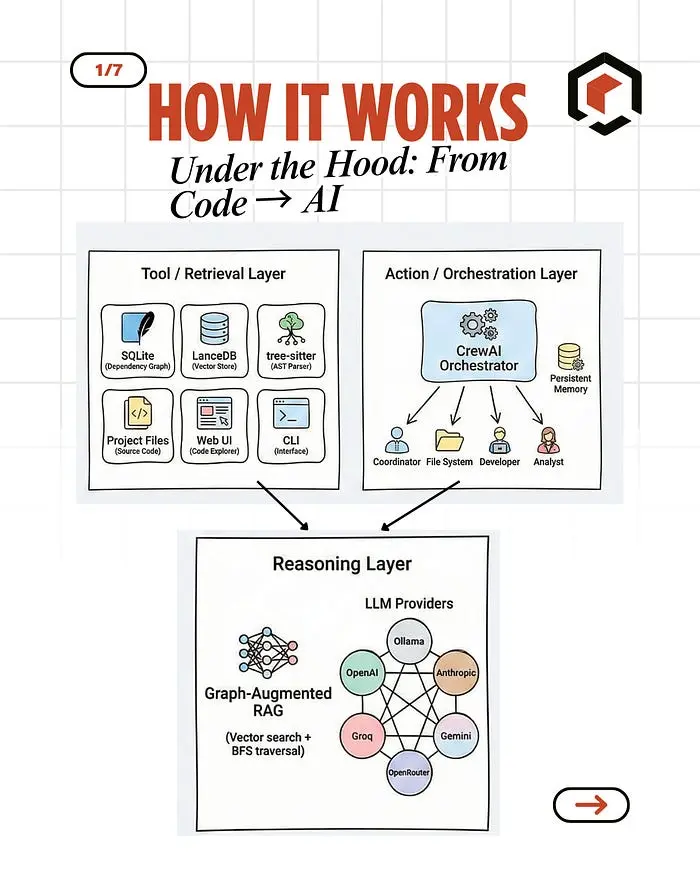
3.2 技术栈
解析:tree-sitter
- 容错(能在有错误的代码上工作)
- 增量更新
- 多语言支持(Python、JavaScript、TypeScript、Go、Rust、Java)
图存储:SQLite
- 久经考验,可嵌入
- ACID 事务
- 完美适合本地优先工具
- Schema 存储函数、类、导入、依赖
向量存储:LanceDB
- 列式格式(快速范围扫描)
- 零服务器架构(向量界的 SQLite)
- 基于磁盘(无内存限制)
- 原生 Python 集成
Embedding:5 种模型选项
hash— 零依赖 BLAKE2b(即时,基于关键词)minilm— 80MB,通用bge-base— 440MB,更高精度jina-code— 550MB,代码感知qodo-1.5b— 6.2GB,最高质量
RAG 引擎:自定义实现
- 向量搜索找到语义相似的符号
- BFS 图遍历扩展到依赖项
- 上下文窗口优化
- 相关性评分
多智能体:CrewAI
- 4 个专用智能体:Coordinator、File System Engineer、Senior Developer、Code Analyst
- 复杂任务最多 25 轮迭代
- 跨轮次记忆管理
- 工具委派
4、你能用它做什么
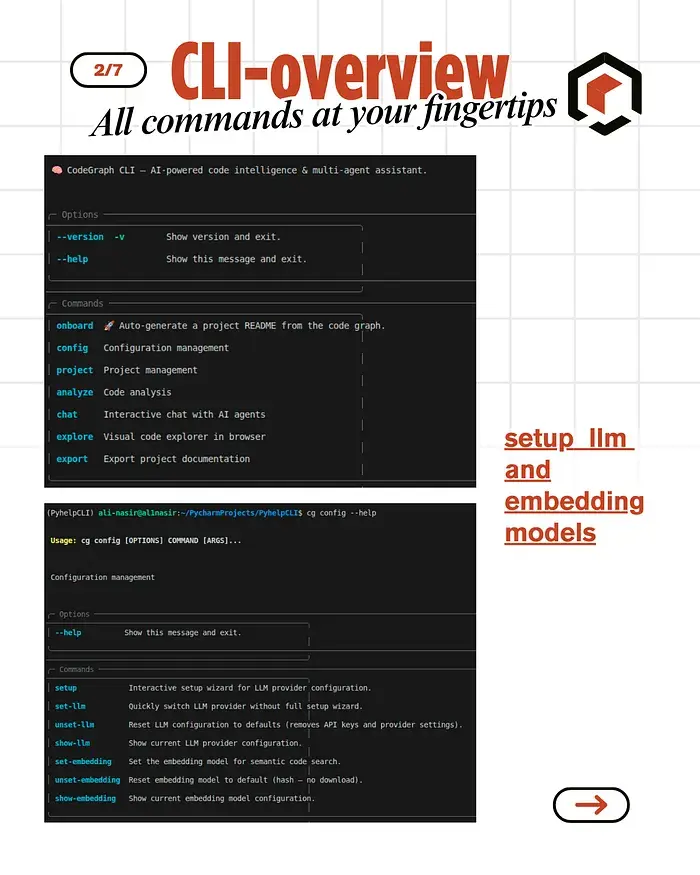
4.1 语义代码搜索
不用这样:
grep -r "authentication" .
# 返回 47 个字符串匹配
而是这样:
cg analyze search "how does authentication work"
返回:
validate_token()— 核心认证函数login_handler()— 调用 validate_tokenTokenStore— 验证器使用的依赖auth_middleware— 包装 login_handler- 它们如何连接的完整解释
3.2 影响分析

在修改代码之前:
cg analyze impact process_uploaded_image --hops 3
展示给你:
- 每个依赖
process_uploaded_image的函数 - 多跳依赖(依赖它的东西又依赖什么)
- ASCII 图可视化
- LLM 对潜在风险的解释
这在我第一周就帮我避免了两次生产事故。
4.3 自然语言对话
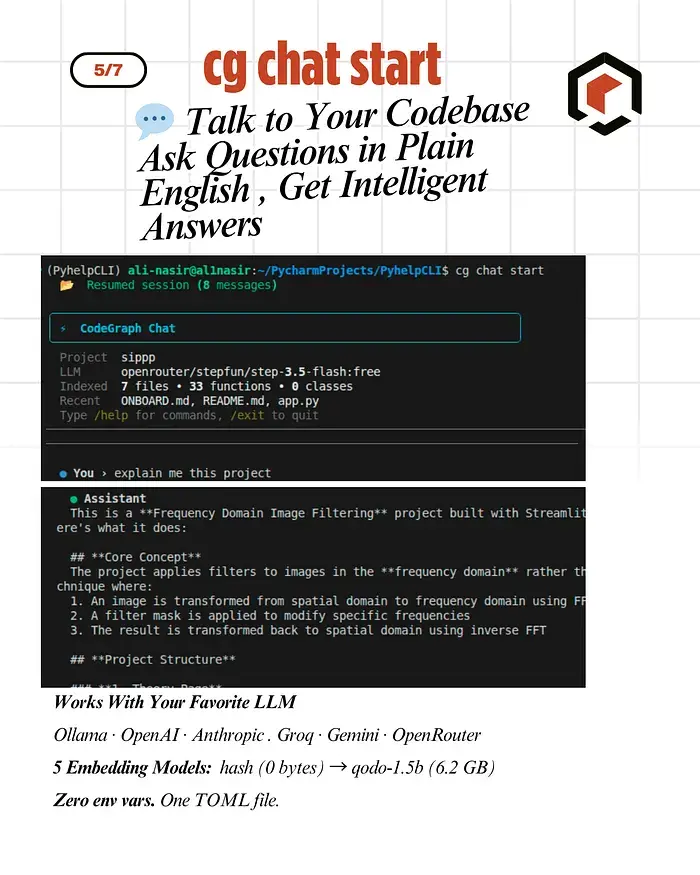
cg chat start
然后问这样的问题:
- "Explain the FFT processing pipeline"
- "What functions use NumPy?"
- "Where is the config file loaded?"
- "Generate a README for this module"
AI 会读取你的实际代码,理解结构,然后解释给你听。
4.4 可视化代码浏览器
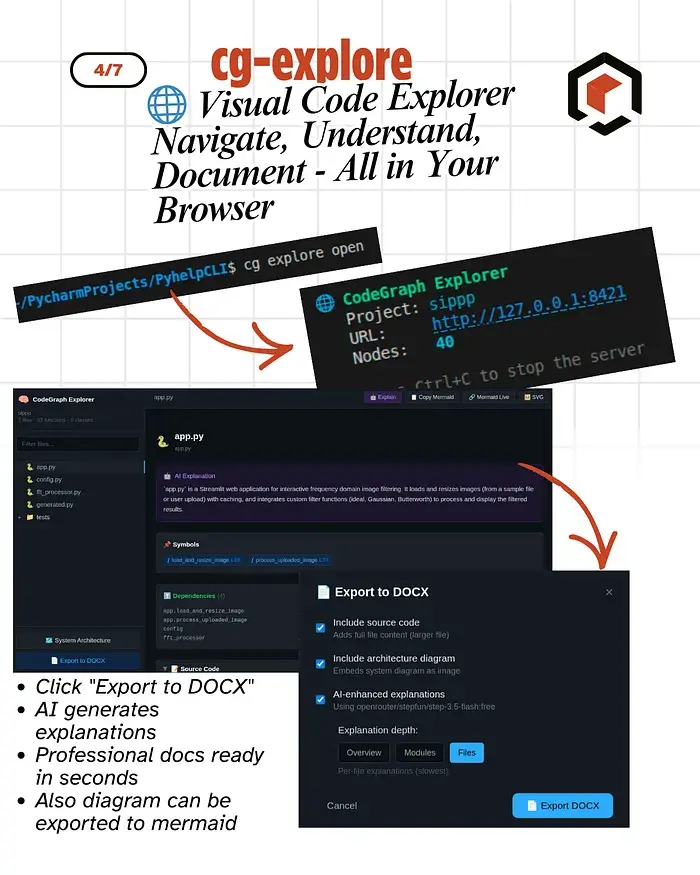
cg explorer start
打开一个网页界面,包含:
- 文件树导航
- 符号查看器(所有函数/类)
- 交互式依赖图
- 悬停 AI 解释
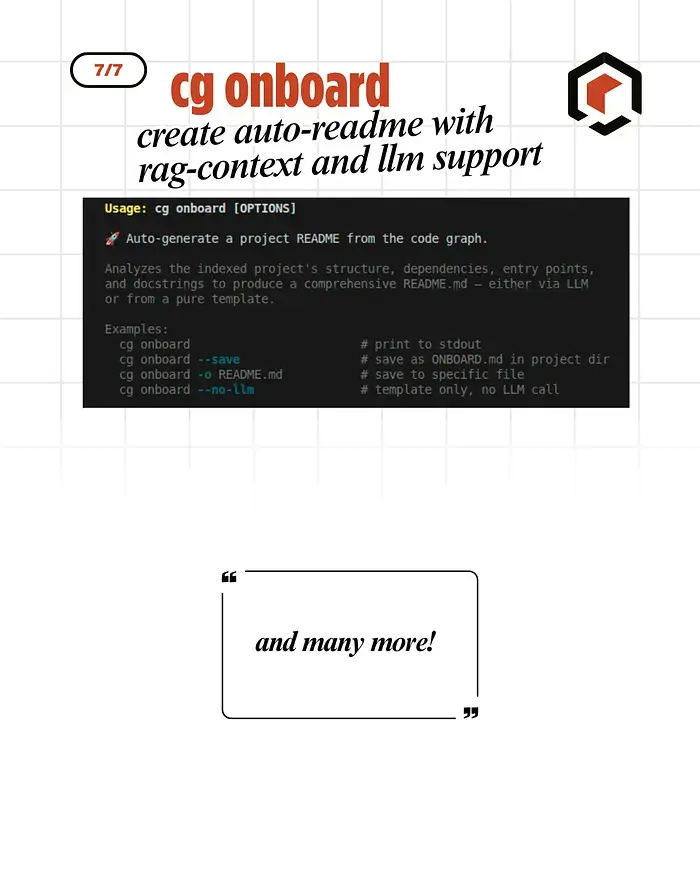
- 导出为 DOCX 并自动生成文档
非常适合新团队成员入职。
4.5 多智能体系统
cg chat start --crew
启动 4 个专用 AI 智能体:
- Coordinator — 路由任务,管理工作流
- File System Engineer — 读取、写入、修补文件
- Senior Developer — 代码分析和生成
- Code Intelligence Analyst — 搜索和总结
它们协同处理复杂任务,比如"把这个模块重构为使用 async/await"。
5、设计决策与权衡
5.1 为什么用 SQLite 而不是 Neo4j?
原因:
- 零服务器设置(只是一个文件)
- 久经考验的可靠性
- 100% 本地优先(无云依赖)
- ACID 事务
- 对代码图来说足够好(大多数代码库 < 1M 节点)
权衡: 图查询能力不如 Neo4j,但对用户来说简单 10 倍。
5.2 为什么用 LanceDB 而不是 FAISS 或 Chroma?
原因:
- 基于磁盘(无内存限制)
- 列式格式(高效范围查询)
- 零服务器架构
- 积极维护
- 原生 Python 集成
权衡: 生态系统比 FAISS 小,但对本地优先工具来说 UX 更好。
5.3 为什么用 tree-sitter 而不是 AST 库?
原因:
- 容错(能在不完整/有错误的代码上工作)
- 增量解析(快速更新)
- 多语言(一个解析器支持 40+ 语言)
- 生产验证(GitHub、Atom、Neovim 都在用)
权衡: 设置比 Python 的 ast 模块复杂,但强大得多。
5.4 为什么本地优先?
原因:
- 隐私(代码不会离开你的机器)
- 离线工作
- 无 API 费用
- 即时响应(无网络延迟)
- 数据自主权
权衡: 用户需要自己管理 LLM 设置,但 Ollama 让这变得简单。
6、构建过程中的经验教训
6.1 图 + 向量 > 只有向量
纯向量搜索(像大多数 RAG 系统)会遗漏结构关系。
一个函数可能在语义上与你的查询相似,但因为没有任何东西调用它而不相关。图遍历解决了这个问题。
关键洞察: 用向量搜索来找到相关节点,然后用图遍历来扩展上下文。
6.2 Tree-sitter 太棒了
我最初用了 Python 的 ast 模块。任何语法错误都会让它崩溃。
Tree-sitter 即使有错误也能继续解析,这对真实世界的代码至关重要。它还免费给了我多语言支持。
关键洞察: 选择能处理真实代码混乱的工具,而不只是完美示例。
6.3 本地优先是特性,不是限制
我最初想"没人会想自己运行 LLM"。我错了。
开发者喜欢本地优先工具:
- 无供应商锁定
- 无 API 费用
- 默认隐私
- 离线工作
Ollama 让本地 LLM 变得触手可及。结合 CodeGraph 的零服务器架构,用户可以在本地运行一切。
关键洞察: "本地优先"是开发者工具的竞争优势。
6.4 多智能体系统需要约束
我的第一个多智能体实现会永远运行下去。智能体会争论、重复自己、或者跑题。
有效的做法:
- 每个智能体的迭代限制(最多 15-25 轮)
- 清晰的角色定义
- 显式的任务委派
- 记忆管理(不要让上下文窗口爆炸)
CrewAI 处理了大部分,但调优至关重要。
6.5 CLI 优先,然后才是其他
我从 CLI 开始。这是对的。
它迫使我:
- 保持核心 API 简洁
- 优雅地处理错误
- 写好帮助文本
- 思考 UX
Web UI 和 VSCode 扩展将在此基础上构建。
关键洞察: 从最简单的可用界面开始。复杂度以后再加。
7、发布后的数据
CodeGraph CLI 两天前发布。以下是发生的事情:
PyPI:
- 500+ 次下载
- 支持 macOS、Linux、Windows
社区反馈:
- "This is what GitHub Copilot should have been"
- "Finally, RAG that understands code structure"
- "The impact analysis feature saved us from a production bug"
最常见的问题:
- "Can it handle monorepos?"(正在做)
- "Will you add [language X]?"(可以,tree-sitter 支持)
- "Can I use it with GPT-4?"(可以,支持 6 个 LLM 提供商)
8、下一步计划
短期(未来 4 周)
- VSCode Extension — 编辑器内的 AI 辅助
- GitHub Action — PR 上自动生成影响分析
- 多仓库支持 — 索引整个组织
- 更多语言 — 优先 TypeScript、Go、Rust
长期(3-6 个月)
- 团队功能 — 共享知识图
- CI/CD 集成 — 防止破坏性变更
- DependencyGuard — 影响分析即服务
- SaaS 选项 — 给想要托管版本的团队
亲自试试
# 安装
pip install codegraph-cli
# 配置(选择你的 LLM)
cg config setup
# 索引你的项目
cg project index ./your-project
# 开始对话
cg chat start
原文链接: Building a Graph-Augmented RAG System for Code Intelligence: Lessons from CodeGraph CLI
汇智网翻译整理,转载请标明出处
